HBase实操 | 使用Phoenix在CDH的HBase创建二级索引
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase实操 | 使用Phoenix在CDH的HBase创建二级索引相关的知识,希望对你有一定的参考价值。
1.文档编写目的
对于HBase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询。如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄。对于较大的表,全表扫描的代价是不可接受的。
但是,很多情况下,需要从多个角度查询数据。例如,在定位某个人的时候,可以通过姓名、身份证号、学籍号等不同的角度来查询,要想把这么多角度的数据都放到rowkey中几乎不可能(业务的灵活性不允许,对rowkey长度的要求也不允许)。
所以,需要secondary index来完成这件事。secondary index的原理很简单,即通过索引表来实现,但是如果自己维护的话则会麻烦一些。在很早的版本中,Phoenix就已经提供了对HBase secondary index的支持。
Fayson在前面的文章《》和《》中介绍了Cloudera Labs中的Phoenix,以及如何在CDH5.11.2中安装和使用Phoenix4.7。本文Fayson主要介绍如何在CDH中使用Phoenix在HBase上建立二级索引。
内容概述:
1.建表与数据准备
2.启用Kafka的Sentry赋权
3.Kafka的赋权测试
4.总结
测试环境:
1.CM5.14.3/CDH5.14.2
2.Phoenix4.7.0
3.操作系统版本为Redhat7.4
4.采用root用户进行操作
5.集群未启用Kerberos
2.建表与数据准备
1.首先确保你的CDH集群已经安装Phoenix的Parcel,安装过程省略,具体可以参考《》。
2.准备一个测试csv文件用来导入Phoenix的表中,Fayson这里准备一个1.2GB,995W行,11个字段的数据文件。
[root@ip-172-31-6-83 generatedata]# cat hbase_data.csv | wc -l
9950000
[root@ip-172-31-6-83 generatedata]# du -sh hbase_data.csv
1.2G hbase_data.csv
[root@ip-172-31-6-83 generatedata]# head hbase_data.csv
340111200507061443,鱼言思,0,遂宁,国家机关,13004386766,15900042793,广州银行1,市场三街65号-10-8,0,1
320404198104281395,暨梅爱,1,临沧,服务性工作人员,13707243562,15004903315,广州银行1,太平角六街145号-9-5,0,3
371326195008072277,人才奇,1,黔西南,办事人员和有关人员,13005470170,13401784500,广州银行1,金湖大厦137号-5-5,1,0
621227199610189727,谷岚,0,文山,党群组织,13908308771,13205463874,广州银行1,仰口街21号-6-2,1,3
533324200712132678,聂健飞,1,辽阳,不便分类的其他劳动者,15707542939,15304228690,广州银行1,郭口东街93号-9-3,0,2
632622196202166031,梁子伯,1,宝鸡,国家机关,13404591160,13503123724,广州银行1,逍遥一街35号-14-8,1,4
440883197110032846,黎泽庆,0,宝鸡,服务性工作人员,13802303663,13304292508,广州银行1,南平广场113号-7-8,1,4
341500196506180162,暨芸贞,0,黔西南,办事人员和有关人员,13607672019,13200965831,广州银行1,莱芜二路117号-18-3,1,4
511524198907202926,滕眉,0,南阳,国家机关,15100215934,13406201558,广州银行1,江西支街52号-10-1,0,3
420205198201217829,陶秀,0,泸州,商业工作人员,13904973527,15602017043,广州银行1,城武支大厦126号-18-2,1,0
3.连接到Phoenix的终端,在Phoenix中建表hbase_test
cd /opt/cloudera/parcels/CLABS_PHOENIX/bin
./phoenix-sqlline.py ip-172-31-6-83.ap-southeast-1.compute.internal:2181:/hbase create table hbase_test
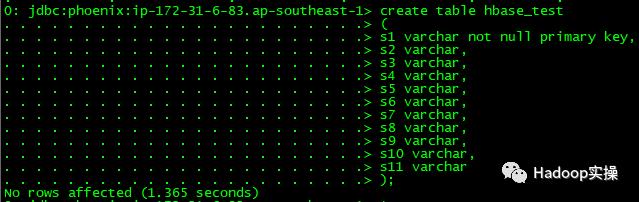
(
s1 varchar not null primary key,
s2 varchar,
s3 varchar,
s4 varchar,
s5 varchar,
s6 varchar,
s7 varchar,
s8 varchar,
s9 varchar,
s10 varchar,
s11 varchar
);
4.将准备好的csv文件put到HDFS,然后通过Phoenix自带的bulkload工具将准备好的csv文件批量导入到Phoenix的表中。
[root@ip-172-31-6-83 generatedata]# hadoop fs -mkdir /fayson
[root@ip-172-31-6-83 generatedata]# hadoop fs -put hbase_data.csv /fayson
[root@ip-172-31-6-83 generatedata]#

[root@ip-172-31-6-83 generatedata]# HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol-1.2.0-cdh5.7.6.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf hadoop jar /opt/cloudera/parcels/CLABS_PHOENIX/lib/phoenix/phoenix-4.7.0-clabs-phoenix1.3.0-client.jar org.apache.phoenix.mapreduce.CsvBulkLoadTool -t hbase_test -i /fayson/hbase_data.csv

5.在Phoenix和hbase shell中分别查询确认数据入库成功。
select * from HBASE_TEST limit 10;
scan 'HBASE_TEST',{LIMIT => 1}


3.Covered Indexes(覆盖索引)
1.使用覆盖索引获取数据的过程中,内部不需要再去HBase的原表获取数据,查询需要返回的列都会被存储在索引中。要想达到这种效果,你的select的列,where的列都需要在索引中出现。举个例子,如果你的SQL语句是select s2 from hbase_test where s6='13505503576',要最大化查询效率和速度最快,可以建立覆盖索引。
CREATE INDEX index1_hbase_test ON hbase_test(s6) INCLUDE(s2)
提示要对HBase进行一些配置才能执行该语句。
2.将以下配置增加到hbase-site.xml,通过Cloudera Manager搜索HBase服务的“hbase-site.xml 的 HBase 服务高级配置代码段(安全阀)”。
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>

保存更改,然后重启HBase。
3.在执行建立覆盖索引之前,我们先执行2个查询语句方便后面跟建立索引后的查询时间进行对比。
select s6 from hbase_test where s6='13505503576';
select s2 from hbase_test where s6='13505503576';


4.再次执行建立覆盖索引的语句
CREATE INDEX index1_hbase_test ON hbase_test(s6) INCLUDE(s2);

5.再次执行上面2个查询语句。
select s6 from hbase_test where s6='13505503576';
select s2 from hbase_test where s6='13505503576';
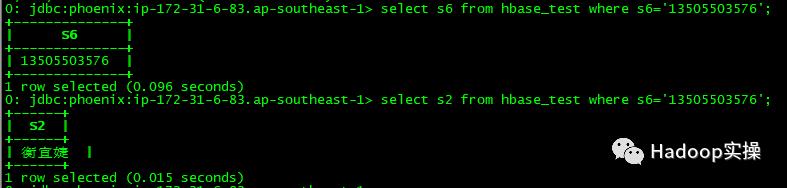
发现都是毫秒级返回,而之前2个查询都是需要30几秒。
6.我们再来具体看看建立覆盖索引的语句。
CREATE INDEX index1_hbase_test ON hbase_test(s6) INCLUDE(s2);
如果查询项中不包含除s2和s6之外的列,而且查询条件不包含除s2之外的列,则可以确保该查询使用Index,关键字INCLUDE包含需要返回数据结果的列。这种索引方式的最大好处就是速度快,而我们也知道,索引就是空间换时间,所以缺点也很明显,存储空间耗费较多。
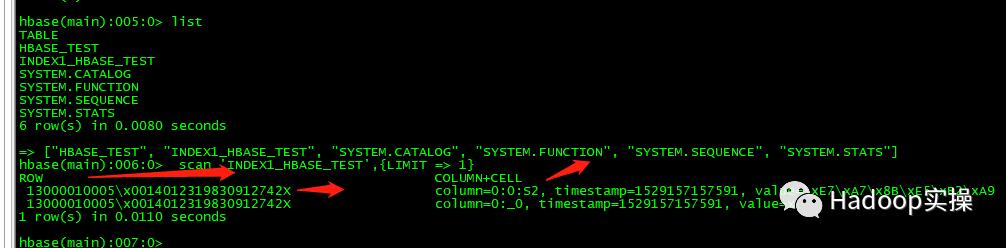
如上图所示,Phoenix的索引其实就是建了一张HBase的表。你可以通过hbase shell的list命令看到。查看表index1_hbase_test,你会发现,这张表一共三列,一列就是索引,第二列是RowKey,最后一列就是s2的值。很明显在这里记录的RowKey,就是为了快速查找HBase中的数据。只是这里用不到,s2已经被保存到了这张索引表中,直接返回。
4.Functional Indexes(函数索引)
函数索引从从Phoenix4.3版本就有,这种索引的内容不局限于列,还能在表达式上建立索引。如果你使用的表达式正好就是索引的话,数据也可以直接从这个索引获取,而不需要从数据库获取。
1.在建立函数索引时,我们先执行两个查询语句好方便与建立索引以后的性能进行对比。
select s1,s7 from hbase_test where substr(s7,1,10)='1550864580';
select s1,substr(s7,1,10) from hbase_test where substr(s7,1,10)='1550864580';

2.建立函数索引
create index index2_hbase_test on hbase_test (substr(s7,1,10));

3.再次执行前面的查询语句进行比较
select s1,s7 from hbase_test where substr(s7,1,10)='1550864580';
select s1,substr(s7,1,10) from hbase_test where substr(s7,1,10)='1550864580';

如果查询项包含substr(s7,1,10),则查询时间在毫秒级,而之前需要30多秒。如果查询项不包含substr(s7,1,10),则跟不建索引时是一样的。如果想让第一个查询语句走索引,我们可以在建立索引时采用INCLUDE(S7)来实现。
5.Global Indexes(全局索引)
全局索引适合那些读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表(数据删除了,索引表中的数据也会删除;数据增加了,索引表的数据也会增加)。而查询数据的时候,Phoenix会通过索引表来快速低损耗的获取数据。默认情况下,如果你的查询语句中没有索引相关的列的时候,Phoenix不会使用索引。
6.Local Indexes(本地索引)
本地索引适合那些写多读少,或者存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引之所以是本地,只要是因为索引数据和真实数据存储在同一台机器上,这样做主要是为了避免网络数据传输的开销。如果你的查询条件没有完全覆盖索引列,本地索引还是可以生效。因为无法提前确定数据在哪个Region上,所以在读数据的时候,还需要检查每个Region上的数据而带来一些性能损耗。
1.先删除之前建立的函数索引INDEX2_HBASE_TEST。
drop index INDEX2_HBASE_TEST on hbase_test;

2.建立本地索引
create local index index2_hbase_test on hbase_test (s7);

3.在查询项中不包含索引字段的条件下,一样查询比较快速。
select s2 from hbase_test where s7='13500591348';
select * from hbase_test where s7='13500591348';

可以发现这2个查询语句返回时间都在毫秒级,而如果不建立索引,查询时间为35S以上。
7.总结
Phoenix的二级索引主要有两种,即全局索引和本地索引。全局索引适合那些读多写少的场景。如果使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。本地索引适合那些写多读少,或者存储空间有限的场景。
索引定义完之后,一般来说,Phoenix会判定使用哪个索引更加有效。但是,全局索引必须是查询语句中所有列都包含在全局索引中,它才会生效。举个例子,下面是创建索引的语句:
create index my_index on hbase_test (s6);
而查询语句是
select s2 from hbase_test where s6='13505503576';
上例就不会用到索引my_index。因为s2并没有包含在索引中。所以使用全局索引,必须要所有的列都包含在索引中。那么怎样才能使用索引呢?有三种方法。
1.创建索引时使用覆盖索引
CREATE INDEX index1_hbase_test ON hbase_test(s6) INCLUDE(s2)
这种索引会把s2加到索引表里面,同时s2也会随着原数据表中的变化而变化。这种方式很明显的缺点是索引表的大小较大,然后就是全局索引不适合写特别多的情况。
这个查询效果具体可以参考第三章
2.使用类似于Oracle的Hint,强制索引。
select /*+ INDEX(hbase_test index1_hbase_test)*/ s5 from hbase_test where s6='13505503576';

如果不带hint,查询时间为35s,带了hint强制使用索引后查询时间为0.099秒。
查询引擎会使用index1_hbase_test这个索引,由于它会发现索引表中没有s5数据,所以每一行它都会去原数据表中获取s5的值。这个强制索引只有在你认为索引有比较好的选择性的时候才是好的选择,也就是说s6等于13505503576的行数不多。不然的话,使用Phoenix默认的全表扫描的性能也许会更好。
3.创建本地索引
create local index index2_hbase_test on hbase_test (s7);
本地索引和全局索引不同的是,查询语句中,即使所有的列都不在索引定义中,它也会使用索引,这是本地索引的默认行为。Phoenix知道原数据和索引数据在同一个RegionServer上,能保证索引查找是本地的。本地索引查询效果具体可参见第6章。
注:使用函数索引,查询语句中带上hint也没有作用。
号外:【贡献社区】如何向 Apache Kylin 做贡献,并成为一名 Committer?
Apache Kylin 是第一个由国人主导的 Apache 项目,自2015年从 Apache 孵化器毕业至今已经三年,三年的时间,Kylin社区发展迅速,用户从早期的 eBay、京东、美团等互联网企业逐渐发展到现在国内外各行业上千家企业。
Apache 强调 “Community over code”,只要你长期在社区树立影响力,获得其他人的认可和信任,都可以成为Committer。
众所周知,顶级开源项目历来受到技术业界的普遍认可,成为 Apache Kylin Committer 不仅能提升在技术圈的影响力,也将成为开源软件的“代言人”参与到项目管理中。当然,成为 Committer 是一个荣誉与责任共存的事情,它不是终点,而是一个更高的起点。
目前,Apache Kylin 未来还有大量的创造性工作需要完成,目前在 roadmap上的功能就有:
完全使用 spark 的构建和查询引擎
支持更多数据源(关系型,非关系型等)
支持灵活(Ad-hoc)查询
列式存储引擎
实时分析引擎及 Lambda 架构
容器化(Docker & Kubernetes)
为此我们非常诚挚地欢迎
社区开发者参与到 Kylin 的开发中来
共同打造这一大数据分析领域的神兽!


不想只是Contributor,还想打怪升级成为Committer?
接着往下看!

还有点不明白?来 Kylin 社区找我们吧:
http://kylin.apache.org/community/

以上是关于HBase实操 | 使用Phoenix在CDH的HBase创建二级索引的主要内容,如果未能解决你的问题,请参考以下文章