HBase实操 | 如何使用HBase存储文本文件
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase实操 | 如何使用HBase存储文本文件相关的知识,希望对你有一定的参考价值。
1.文档编写目的
Fayson在前面的文章中介绍了《》和《》,假如我们有大量的文本文件,我们应该如何保存到Hadoop中,并实现文本文件的全文检索呢。为了介绍如何对文本文件进行全文检索,本文会先介绍如何使用HBase保存文本文件。虽然HDFS中也可以直接保存这种非结构化数据,但是我们知道像这种文本文件,一般都是10KB~1MB的小文件,因为HDFS并不擅长存储大量小文件,所以这里选择HBase来保存。
内容概述
1.文件处理流程
2.准备上传文件的Java代码
3.运行代码
4.Hue中查询验证
测试环境
1.RedHat7.4
2.CM5.14.3
3.CDH5.14.2
4.集群未启用Kerberos
2.文件处理流程
1.如上图所示,Fayson先在本地准备了一堆记事本文件,有中文内容的,英文内容的,有中文名的,也有英文名的。
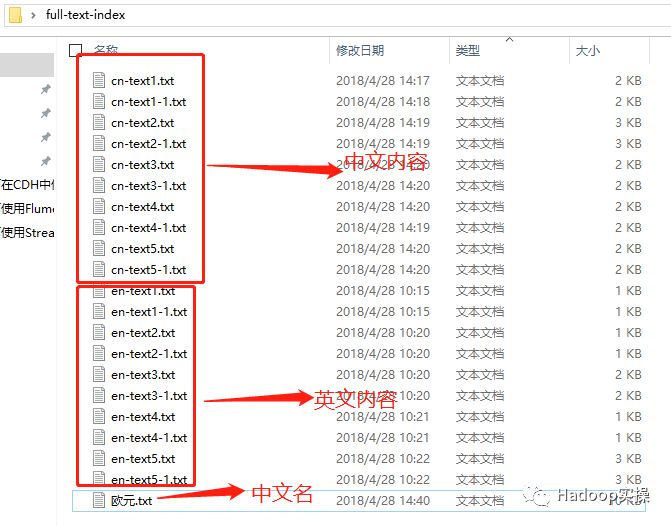
中文内容示例
英文内容示例

2.然后通过Java程序遍历本地的文件夹所有文本文件入库到HBase,在入库过程中,我们读取文本文件的文件名作为Rowkey,另外将整个文本内容转为bytes存储在HBase表的一个column里。
3.最后可以通过Hue来进行查看文本文件的内容,当然你也可以考虑对接到你自己的查询系统。
3.准备上传文件的Java代码
1.首先是准备Maven文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.cloudera</groupId>
<artifactId>hbase-exmaple</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>hbase-exmaple</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
<name>Cloudera Repositories</name>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.14.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>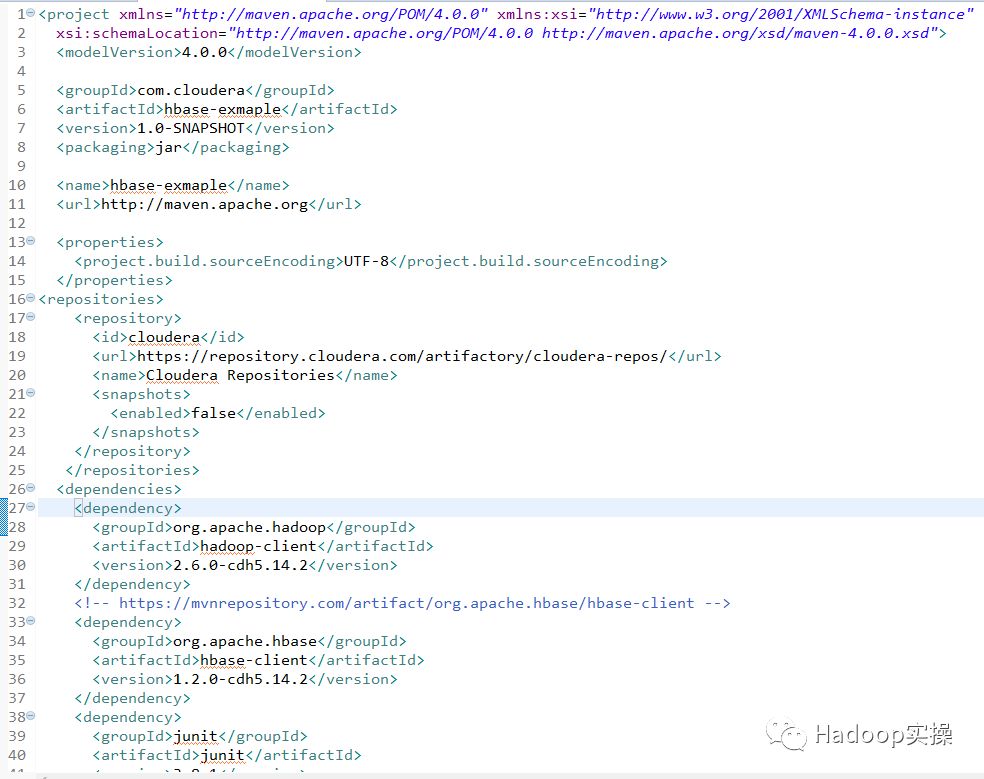
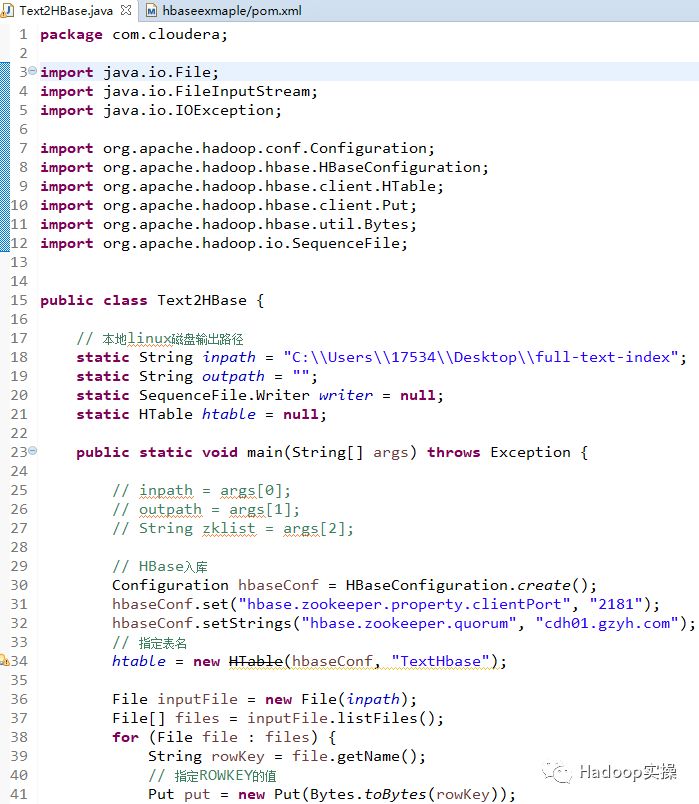
2.准备上传文件到HBase的Java代码
package com.cloudera;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.SequenceFile;
public class Text2HBase {
// 本地linux磁盘输出路径
static String inpath = "C:\Users\17534\Desktop\full-text-index";
static String outpath = "";
static SequenceFile.Writer writer = null;
static HTable htable = null;
public static void main(String[] args) throws Exception {
// inpath = args[0];
// outpath = args[1];
// String zklist = args[2];
// HBase入库
Configuration hbaseConf = HBaseConfiguration.create();
hbaseConf.set("hbase.zookeeper.property.clientPort", "2181");
hbaseConf.setStrings("hbase.zookeeper.quorum", "cdh01.gzyh.com");
// 指定表名
htable = new HTable(hbaseConf, "TextHbase");
File inputFile = new File(inpath);
File[] files = inputFile.listFiles();
for (File file : files) {
String rowKey = file.getName();
// 指定ROWKEY的值
Put put = new Put(Bytes.toBytes(rowKey));
// 指定列簇名称、列修饰符、列值 temp.getBytes()
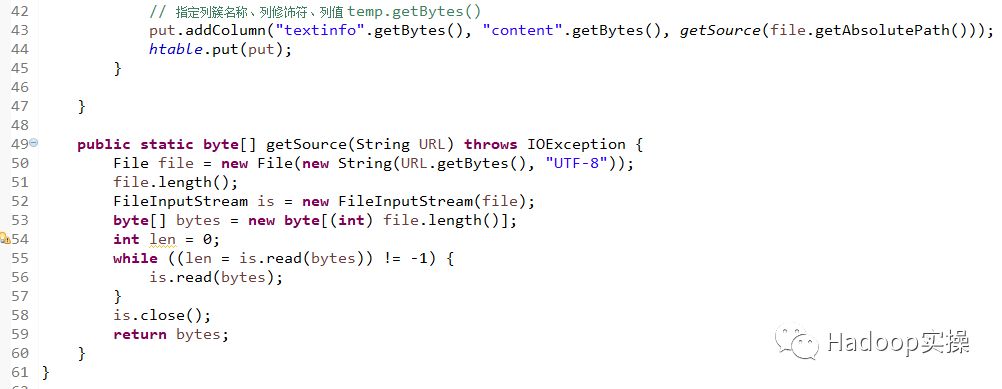
put.addColumn("textinfo".getBytes(), "content".getBytes(), getSource(file.getAbsolutePath()));
htable.put(put);
}
}
public static byte[] getSource(String URL) throws IOException {
File file = new File(new String(URL.getBytes(), "UTF-8"));
file.length();
FileInputStream is = new FileInputStream(file);
byte[] bytes = new byte[(int) file.length()];
int len = 0;
while ((len = is.read(bytes)) != -1) {
is.read(bytes);
}
is.close();
return bytes;
}
}
4.运行代码
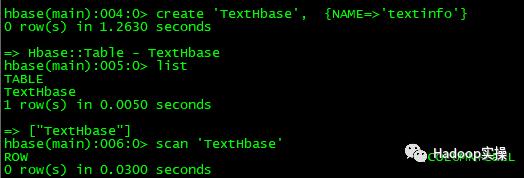
1.首先我们在HBase中建一张表用来保存文本文件
create 'TextHbase', {NAME=>'textinfo'}
2.配置客户端Windows机器的hosts文件
4.到HBase中进行查询确认
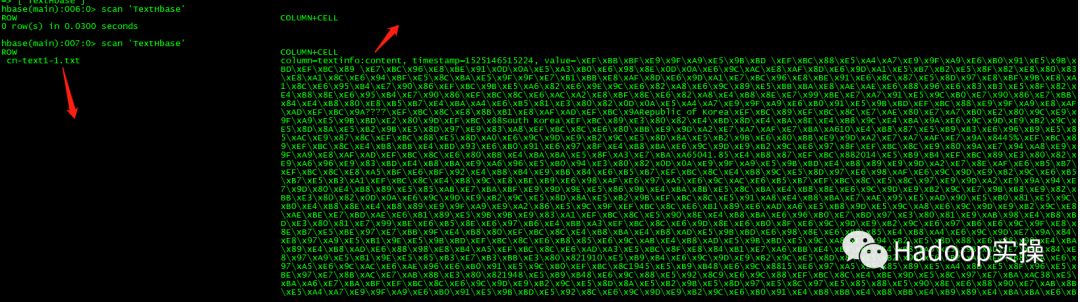
一共21条,表明全部入库成功

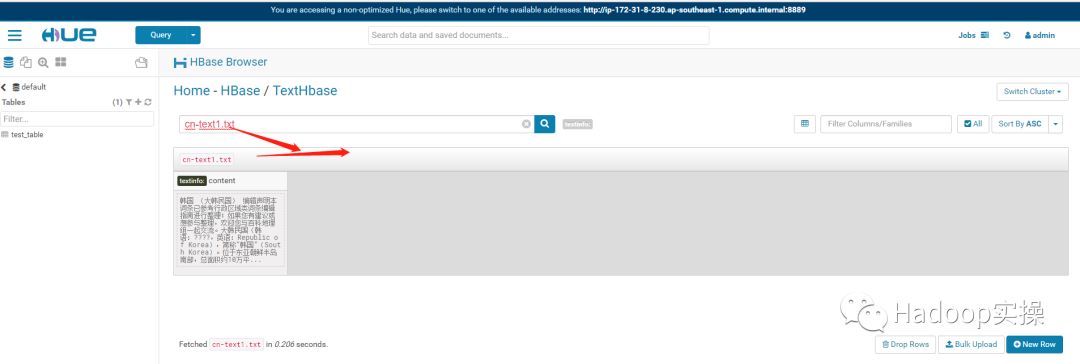
5.Hue中查询验证
1.从Hue中进入HBase的模块
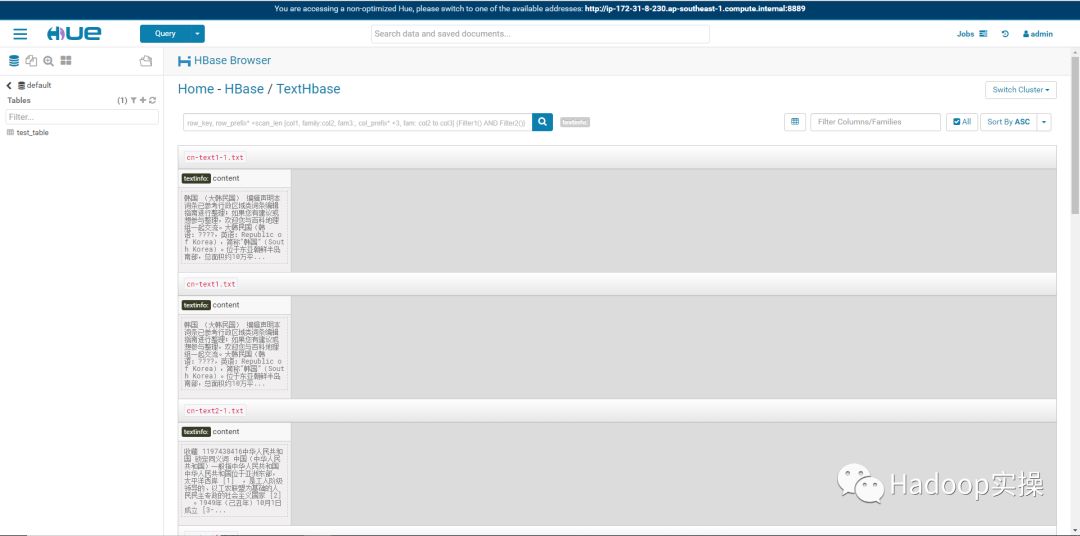
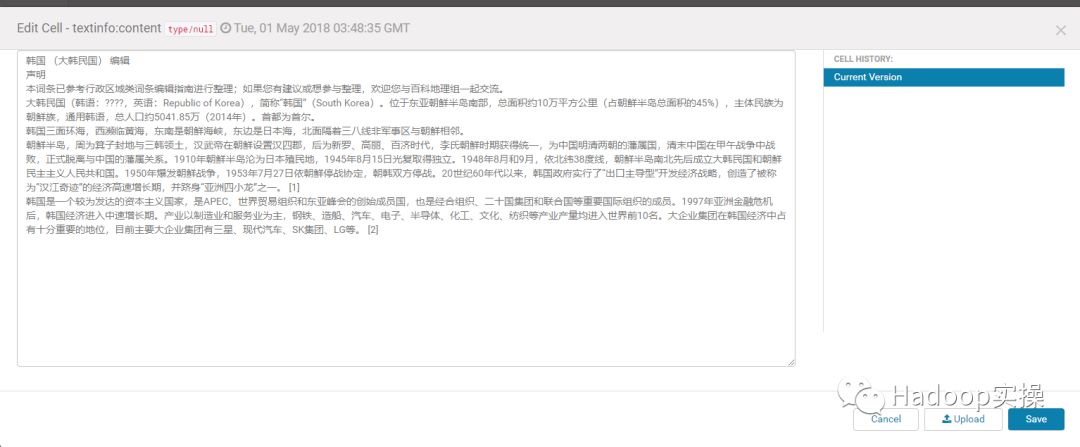
单击某个column,可以查看整个文本内容
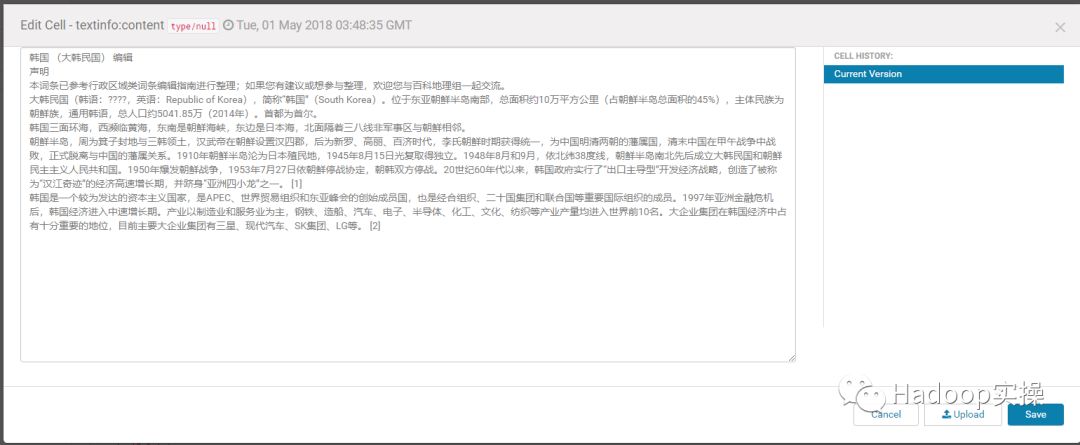
2.查询某一个Rowkey进行测试
https://github.com/fayson/cdhproject/blob/master/hbasedemo/src/main/java/com/cloudera/hbase/Text2HBase.java
https://github.com/fayson/cdhproject/tree/master/hbasedemo/full-text-index
以上是关于HBase实操 | 如何使用HBase存储文本文件的主要内容,如果未能解决你的问题,请参考以下文章