「回顾」Apache HBase的现状和发展
Posted DataFunTalk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「回顾」Apache HBase的现状和发展相关的知识,希望对你有一定的参考价值。
分享嘉宾:杨文龙 阿里巴巴 技术专家,HBase社区Committer&PMC
内容来源:HBase MeetUp《Apache HBase的现状和发展》
出品社区:DataFun
一、HBase是什么
HBase(Hadoop Database),是一个基于Google BigTable论文设计的高可靠性、高性能、可伸缩的分布式存储系统。
它有以下特征:
1.HBase仍然是采用行存储的,采用松散表的结构来获得动态列的功能;
2.原生海量数据分布式存储。在单个数据库中可以存档GB甚至上pb。在一行中也可以存储上百万列。任何大小的数据量都适合采用HBase;
3.不仅支持随机查询,还支持范围查询;
4.高吞吐,低延迟。一个集群可以有上千万个dps,平均的延迟可以做到一毫秒之内;
5.在线NOSQL数据库;
6.多版本,增量导入,多维删除。

1.1 HBase的四大基因
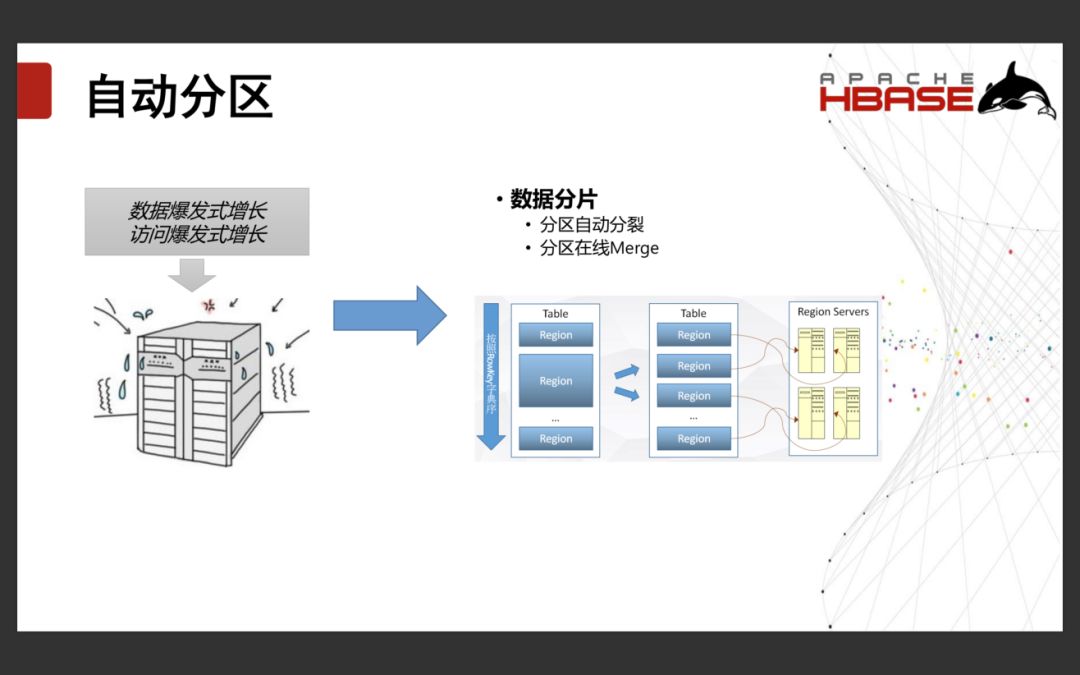
1.1.1自动分区
最开始的时候,我们的数据库是单机的数据库。慢慢的我们发现单机的数据库无法承受数据和访问的爆发式增长。因此就出现了分库分表的方案。将数据库和表拆分到多个服务器上,然后利用中间件作为一个路由。这里就会遇到一个问题,随着数据的增加,中间件就会成为一个瓶颈。如果请求量爆发式增长的时候,要加载新的进去,整个物理的变化需要进行搬迁之后才能够进行使用。
而在HBase中,使用的是自动分区功能。当访问量和请求量增加的时候它可以自动的进行数据分片,以应对数据和请求的爆发式增长。
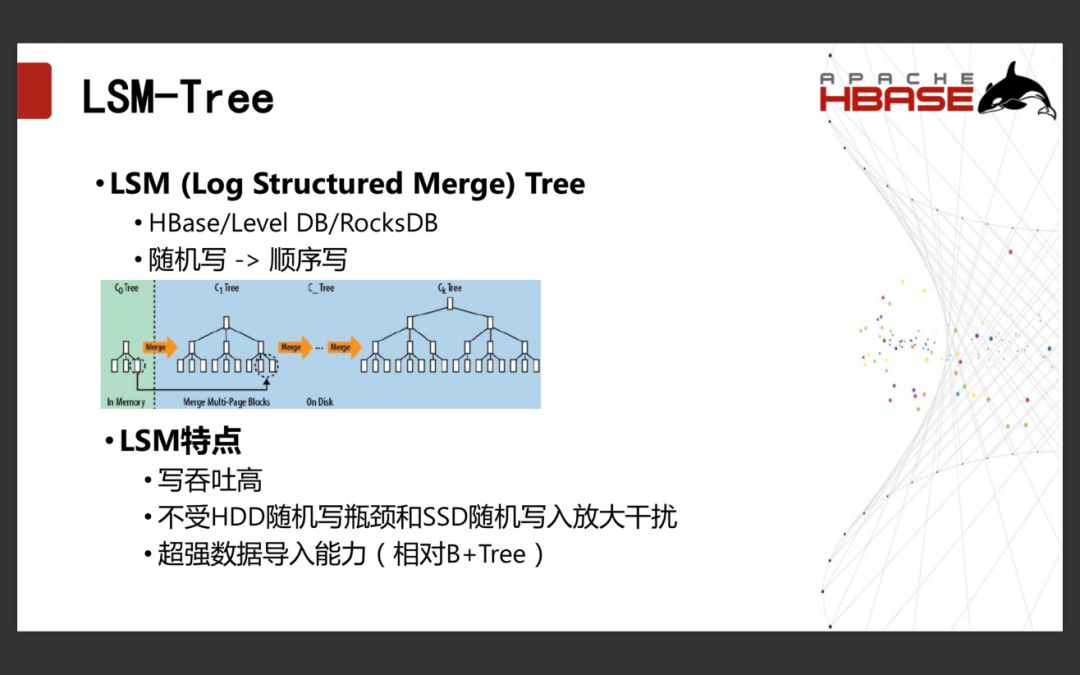
1.1.2 LSM-Tree
LSM(Log Structured Merge)Tree,它的一个重要的功能就是随机写变成顺序写。
现在LSM模型是大数据库的标配。它主要包括如下几个特点:
1)写吞吐量高;
2)不受hdd随机写瓶颈和ssd随机写入放大干扰;
3)超强数据导入能力。
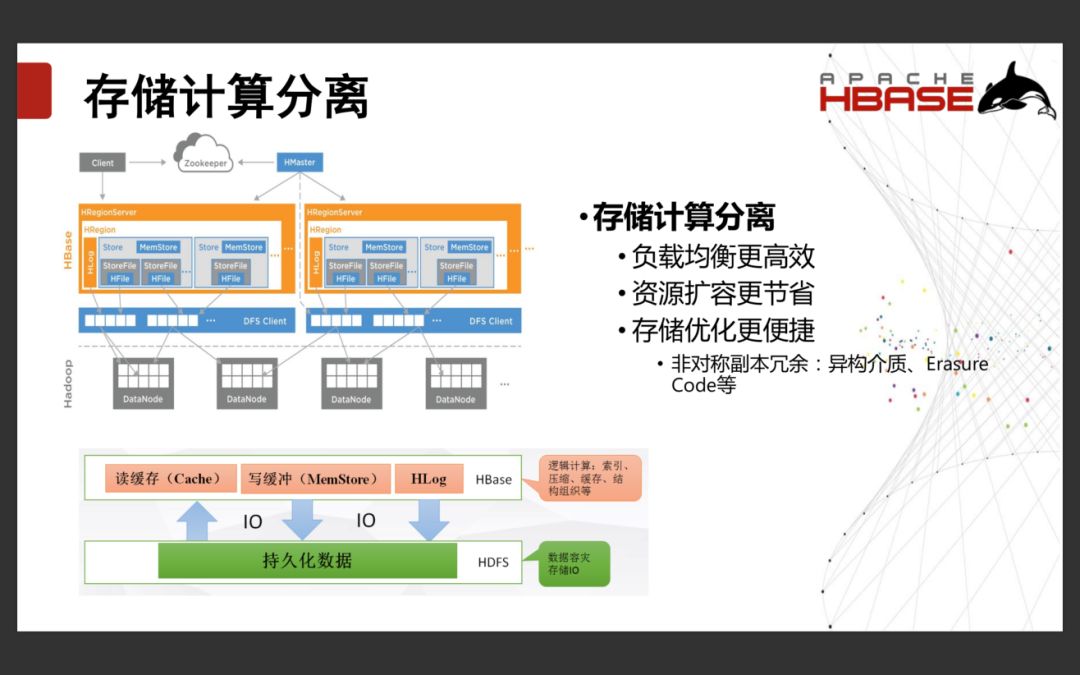
1.1.3存储计算分离
HBase本身不会存任何数据。数据都是存储在底层的HDFS中。存储计算分离有以下好处:负载均衡更高效、资源扩容更节省、存储优化更便捷。
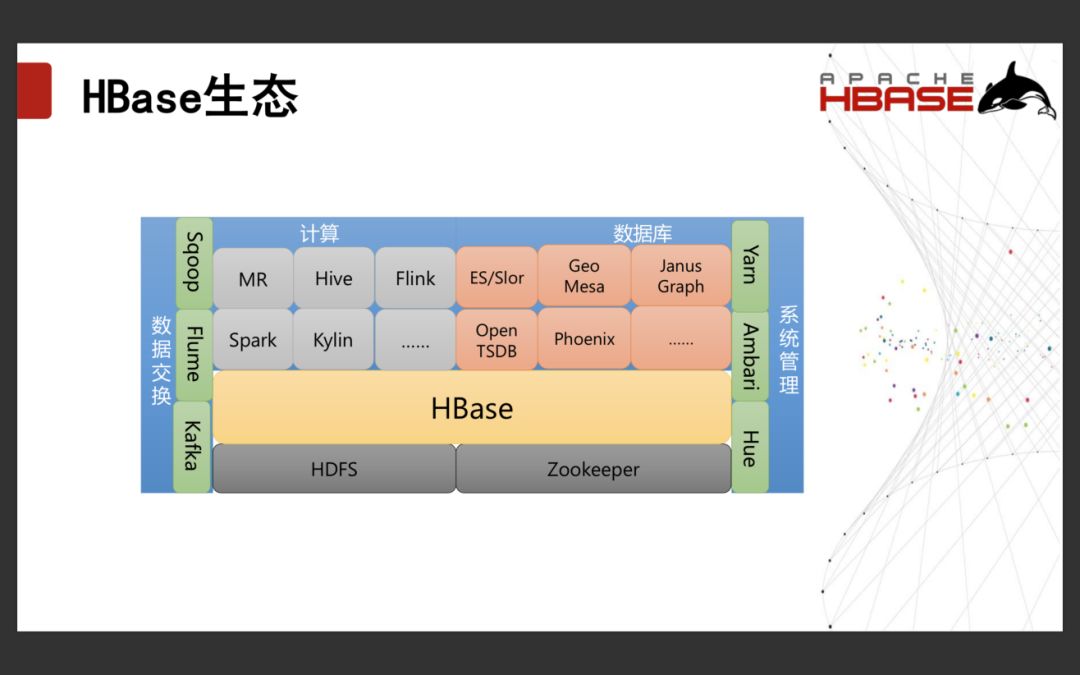
1.1.4 HBase生态
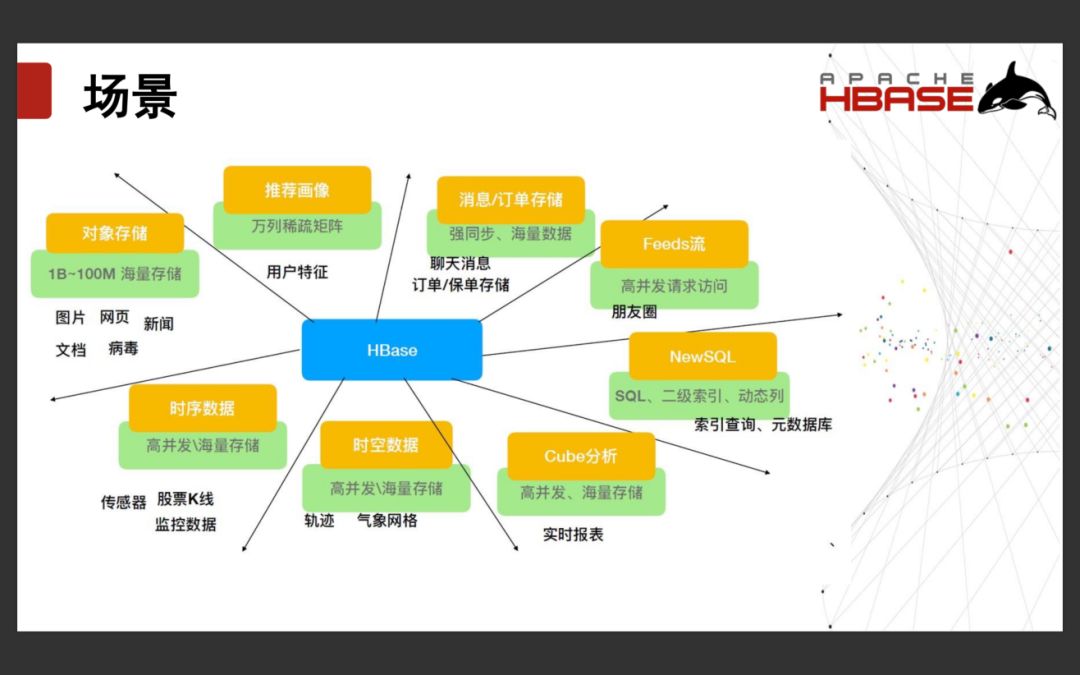
1.2 场景
1.3使用HBase的商业公司
基本上每一个大型的公司都在使用HBase。

1.4 HBase特性总结
HBase,为大数据而生,有LSM树:离线导入效率巨高 、实时写入吞吐大、增量导入隔离性强;伸缩性强;TTL:数据时效性,系统自动处理、时效性的个性化设置;多版本:数据的第三维度、高效删除方式;动态列:数据发散的利器;协处理器:数据校正、高效适应个性化;异构介质多副本存储:海量与实时的性价比满足;Erasure Code:因大而生。

二、HBase社区的发展
2.1 HBase的起源
HBase于2006年诞生于Powerset,一家从事自然语言处理和搜索的创业公司(后被微软收购)
HBase的实现基于Google发布的BigTable论文,用来解决 Hadoop中随机读写效率低下的问题。HBase最初的开发人员是MichaelStack和JimKellerman。2007年4月,HBase做为一个模块提交到Hadoop的代码库中,代码量~8000行,2010年5月HBase成为Apache的顶级项目,同年,Facebook把HBase使用在其消息平台中。
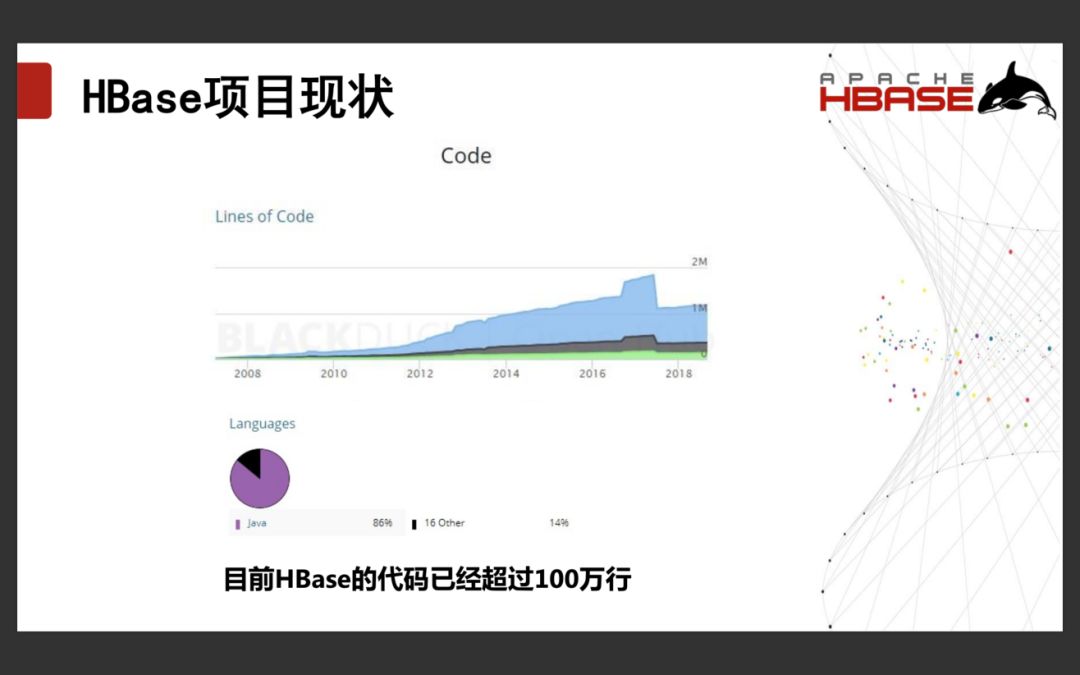
2.2 HBase项目现状
目前HBase的代码已经超过100万行,HBase仍然是最活跃的Apache项目之一,拥有76个Committer,42位PMC,共有328位Contributor,其中14位 Committer/PMC 来自中国。
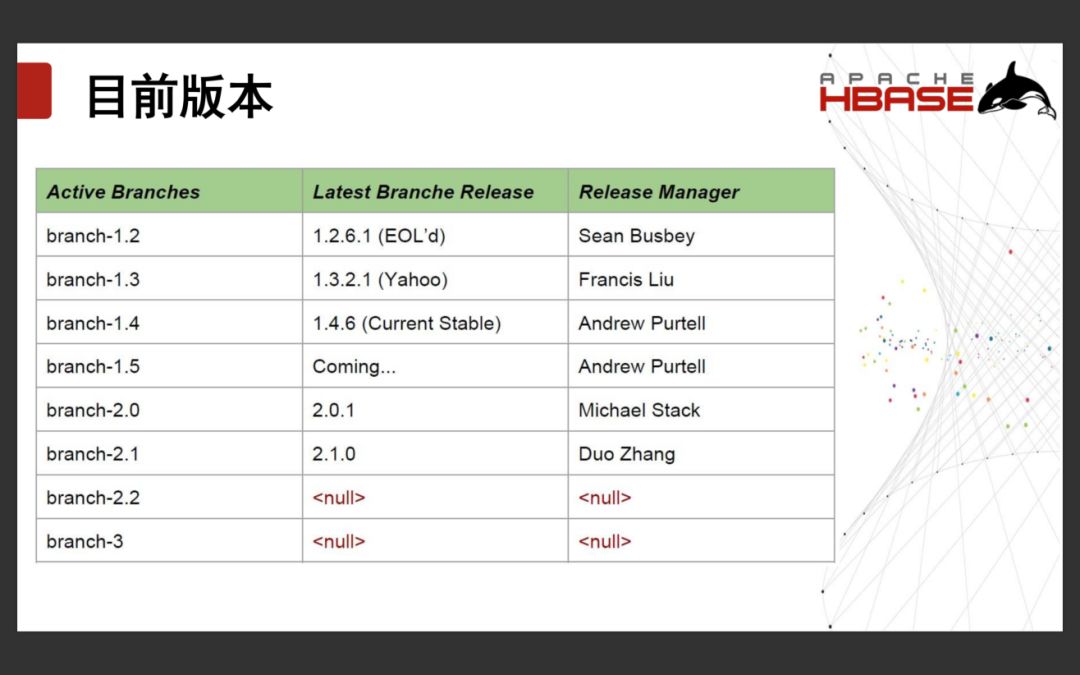
2.3 HBase目前版本
HBase目前版本众多。见下图:
三、HBase2.0
3.1 HBase2.0版本发布历史
HBase2.0的发布是一部血泪史,因为在四年前已经有这个版本了,由于一些因素,造成了没有人管理。最后花了一年多的时间才稳定他的版本发布出来,他的Release Manger多次更换,才把他发布出来。由此,我们吸取了这次教训,我们以后会做好版本控制,把控好发布的节奏。

3.2 新功能
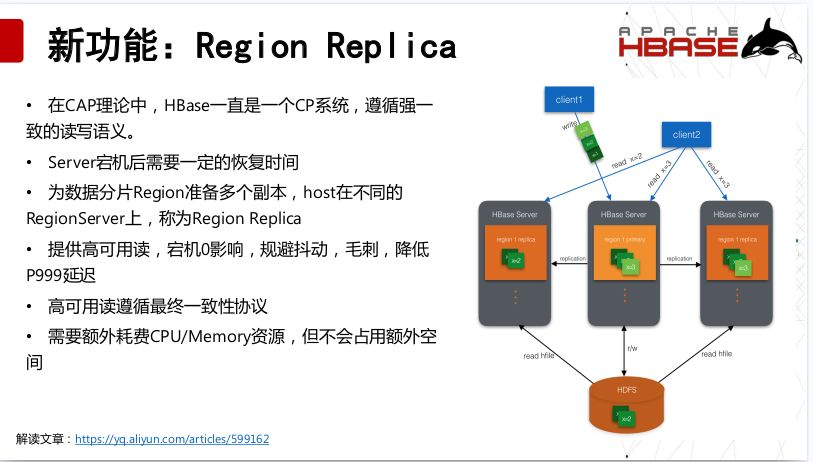
3.2.1 Region Replica
Region Replica这个功能在1.2版本中已经存在,但是为什么叫做新功能呢?是因为之后修改了很多bug,在1.4版本才稳定下来,然后1.4和2.0是同时发布的。在CAP理论中,HBase一直是一个CP系统,遵循强一致的读写语义,所以Server宕机后需要一定的恢复时间,如果宕机了,客户端可以从另外的副本中去读取数据,Region Replica为数据分片Region准备了多个副本,host在不同的RegionServer上,同时,客户端也可以做到,对多个副本同时发请求,然后做到选择最快速的那个副本,提供高可用读,宕机0影响,规避抖动,毛刺,降低P999延迟;缺点是需要额外耗费CPU/Memory资源,但不会占用额外空间。
3.2.2 读写链路Off-heap
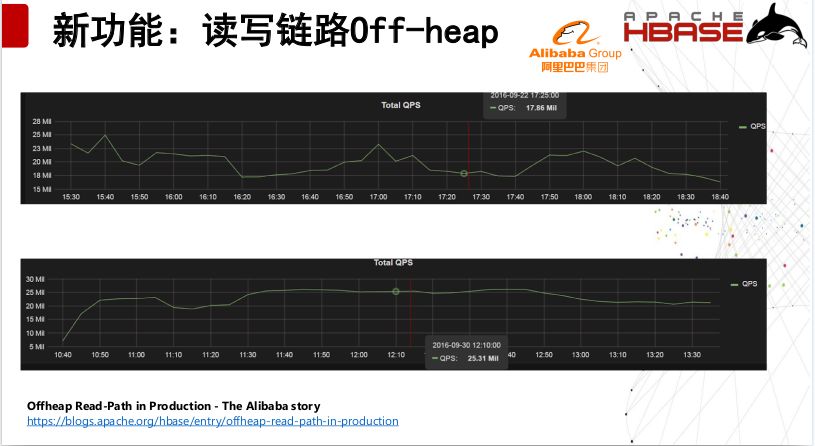
第二个新功能是全链路Off-heap,意思就是读写链路数据端到端Off-heap,减少java GC带来的停顿,进一步降低P999延迟,提高吞吐。这个功能我们从两方面来实现的:写链路Off-heap,我们使用在RPC层使用Netty的Off-heap ByteBuffer,使用支持Off-heap的Protobuf。同时使用Off-heap的Chunk 来存储Memstore中的KeyValue。
在读链路Off-heap方面,使用Off-heap的Bucket Cache,HBase自己管理内存的,我们从Bucket Cache读取数据的时候,先要从Protobuf做一次拷贝,因为可能读取的时候,发生内存不够了,再次分配的情况。在读取对Bucket Cache进行引用计数,保证读取的时候,内存不会被回收掉,读取时不再需要先拷贝到heap,对Bucket Cache进行了一系列性能优化。

后面这是HBase官方放着阿里巴巴在双十一对HBase优化之后的对比图,可以看到优化之后他的请求的曲线更加平稳,吞吐量增长了30%,这个案例大家可以去HBase的官方去看一下。
3.2.3 In Memory Compaction
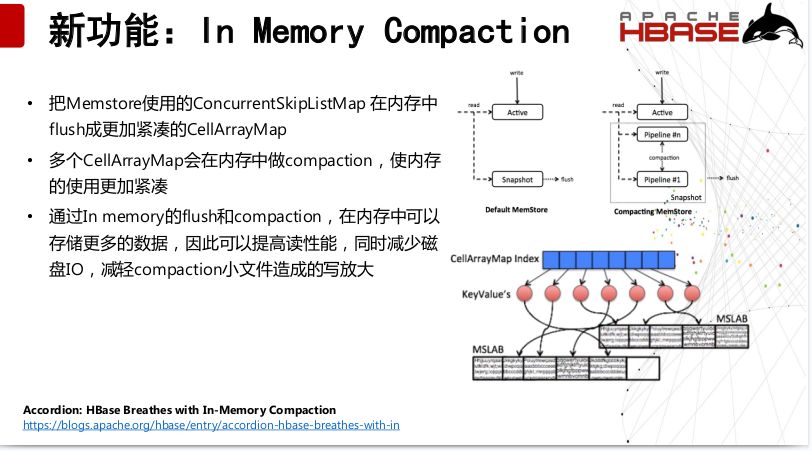
在HBase2.0中另外一个重磅的功能就是In Memory Compaction,以前我们知道HBase中使用的数据结构是java中原生的跳表,但是跳表依然是一个松散的结构,这样的话,虽然内存不断的在增大,但是刷到之后,会造成通过In memory的flush不会到hdfs上,反而回转到更加紧凑的CellArrayMap这个结构,同时多个CellArrayMap会在内存中做compaction,使内存的使用更加紧凑。然后通过In memory的flush和compaction,在内存中可以存储更多的数据,因此可以提高读性能,同时减少磁盘IO,减轻compaction小文件造成的写放大。这个功能社区也有介绍。
3.2.4 小对象存储MOB
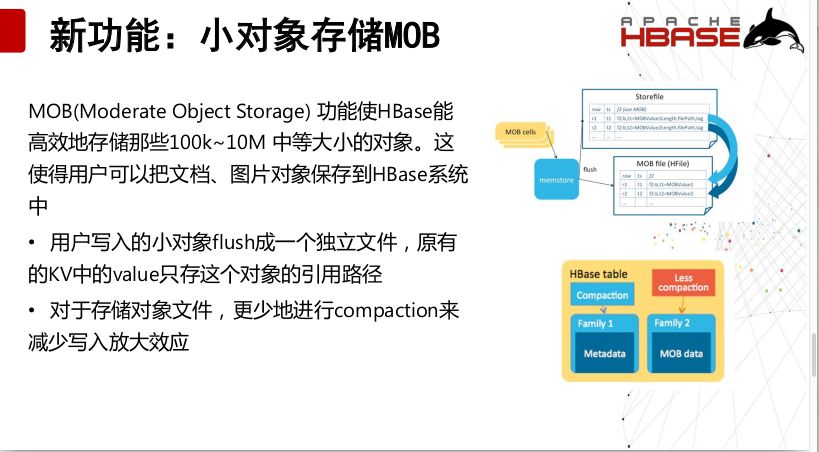
之前我们建议在HBase上不要存很大的KV值,但是MOB(Moderate Object Storage) 功能使HBase能高效地存储那些100k~10M 中等大小的对象。这使得用户可以把文档、图片对象保存到HBase系统中,用户写入的小对象flush成一个独立文件,原有的KV中的value只存这个对象的引用路径,对于存储对象文件,更少地进行compaction来减少写入放大效应。
3.2.5 Assignment MangerV2
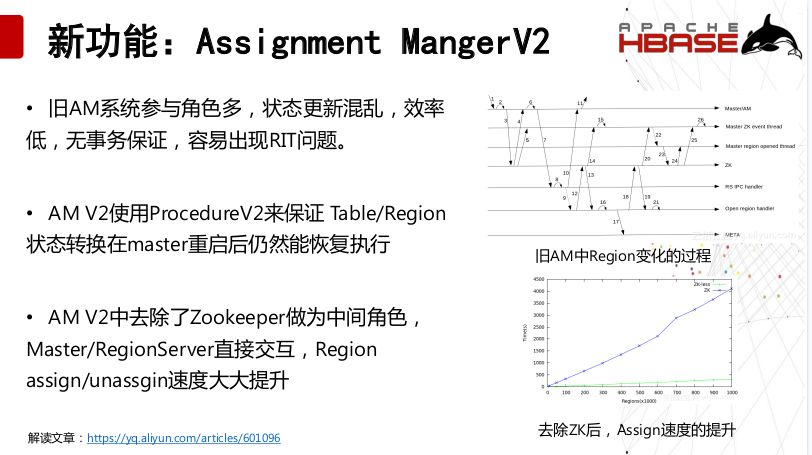
这是一个非常重要的模块,HBase中的状态流转,建表删表,都需要在Assignment MangerV2上进行,之前旧AM系统参与角色多,状态更新混乱,效率低,无事务保证,容易出现RIT问题。所以AM V2使用ProcedureV2来保证 Table/Region状态转换在master重启后仍然能恢复执行,然后去除了Zookeeper做为中间角色,Master/RegionServer直接交互,Region assign/unassgin速度大大提升。
3.2.6 其他
在HBase2.0中,还有非常多的新功能,具体如下:

3.3 兼容性和升级建议
建议如下:

四、HBase未来规划
4.1 HBaseConAsia & 开发者圆桌会议
HBase众多开发者也会参加这个会议,参与讨论它的未来发展方向。
4.2 更加易用
HBase已经提供了,Java的API,但是这个案例不太友好,我们目前打算提供Native的SQL接口,能够做到轻量级的SQL支持、内置的二级索引方案、与Spark SQL更好地结合等功能。

4.3 更高性能
在以后的版本中,不用在对HBase的性能担心了,我们在以后的版本中准备从Use CCSMap to improve HBase YGC tim、全链路异步化、基于非易失存储的WALLess方案等方面努力成为LSM模型下性能最好的Java存储引擎。

4.4 更强扩展性和稳定性
这个方面我们以下几个方面来解决:

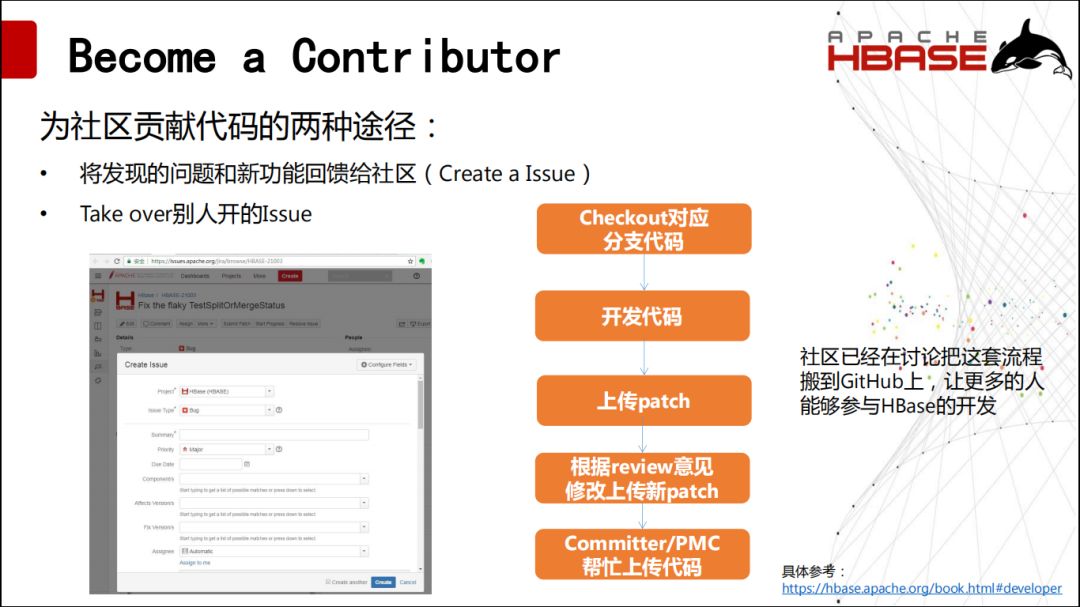
五、如何成为Committer



作者介绍:
杨文龙,阿里巴巴技术专家。HBase社区Committer&PMC,Ali-HBase内核负责人,对分布式存储系统的设计、实践具备丰富的大规模生产的经验。
内推信息:
Base:杭州、深圳,职位:存储服务平台开发,有意者请投递简历至文龙老师个人邮箱:allanwin@163.com ,详细介绍可点击阅读原文。
——END——
HBase交流群及DataFun大数据交流群欢迎您的加入,感兴趣的小伙伴欢迎加管理员微信:
文章推荐:
社区介绍:
DataFun定位于最“实用”的数据科学社区,主要形式为线下的深度沙龙、线上的内容整理。希望将工业界专家在各自场景下的实践经验,通过DataFun的平台传播和扩散,对即将或已经开始相关尝试的同学有启发和借鉴。DataFun的愿景是:为大数据、人工智能从业者和爱好者打造一个分享、交流、学习、成长的平台,让数据科学领域的知识和经验更好的传播和落地产生价值。
DataFun社区成立至今,已经成功在全国范围内举办数十场线下技术沙龙,有超过一百五十位的业内专家参与分享,聚集了万余大数据、算法相关领域从业者。
以上是关于「回顾」Apache HBase的现状和发展的主要内容,如果未能解决你的问题,请参考以下文章