HBase2.0商用首发--有哪些值得期待的新特性
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase2.0商用首发--有哪些值得期待的新特性相关的知识,希望对你有一定的参考价值。
HBase本身是一个分布式存储、数据库引擎,可以支持千万的QPS、PB级别的存储,这些都已经在生产环境验证,并且在阿里得以验证。
早在2010年开始,阿里巴巴集团开始研究并把HBase投入生产环境使用,从最初的淘宝历史交易记录,到蚂蚁安全风控数据存储,HBase在几代阿里专家的不懈努力下,已经表现得运行更稳定、性能更高效,内部HBase集群超过万台的规模,单集群超过千台,是集团核心数据库产品之一,也是国内甚至国际上绝对的HBase大户。
为什么HBase会受到大客户的青睐。首先在这个上云的时代,在云上,对于引擎最为核心的就是存储计算分离,存储可以按需计费,起码得弹性伸缩。计算则按节点存储提供,完全按照QPS计费,要么费用高得吓人,要么难以满足更多的场景。
比如存储10M,到底算一次QPS,还是多少次。 由于HBase天生就是存储计算分离,天然比较适配云上的架构,可以说到了云上,HBase更加具有优势。
所以国内大型互联网企业内部都有大量的HBase集群,尤其阿里更甚。自2012年诞生第一位“东八区” HBase committer,到今天,阿里巴巴已经拥有3个PMC,6个committer,是中国拥有最多HBase committer的公司,其中HBase内核中超过200+重要的feature是阿里贡献。除了拥有强大的内核团队和内核能力,HBase在内部经过双十一等超级业务的千锤百炼,锻炼出一系列的完善的产品形态和企业级能力。
基于阿里长达8年和超万台实践经验和技术积累的延伸,ApsaraDB for HBase在基于社区的HBase的基础上,推出了云HBase服务。建立在阿里云庞大生态体系下,根据云环境生态和HBase存储系统的特点,推出适合企业严苛要求的云HBase存储系统。
HBase2.0在性能,稳定性上做了一系列内核架构级别优化。这次阿里云基于社区HBase2.0稳定版本基础上,进行了进一步一系列性能和稳定性优化和测试验证。
此次首发云HBase2.0云服务,让用户可以第一时间体验到阿里技术加持的HBase 2.0新版本。
云数据库HBase2.0产品架构
对比优势
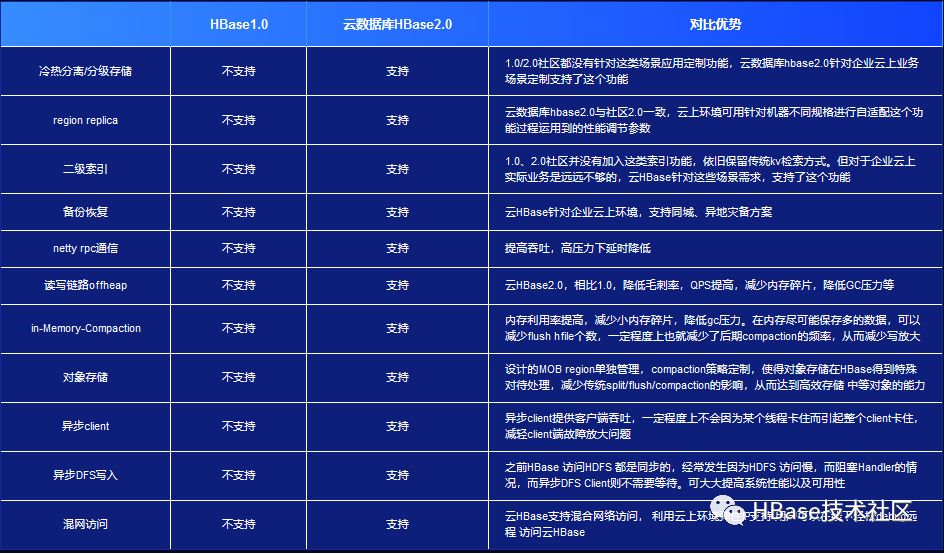
首先是针对企业不同的使用环境,不同的SLA诉求,云HBase一共提供3个版本,分别满足开发环境,在线业务,以及金融级业务的诉求。单节点版本,低廉的价格用于开发测试场景,集群版本,99.9%可用,满足企业在线业务诉求,支持最高5000万的QPS和10P的数据。还有支持金融级高可用的双活版本。所有版本都支持11个9的数据可靠性,无需担心数据丢失。

除了完善的产品形态,针对企业应用中成本、安全、稳定性、易用性等诸多诉求,阿里云HBase提供了强大的能力,例如存储计算分离,按需弹性能力; 数据备份恢复能力;数据冷热分离和分级存储能力;SQL接口和强大的二级索引和倒排索引能力;多层次安全能力等等。
细数ApsaraDB HBase典型场景
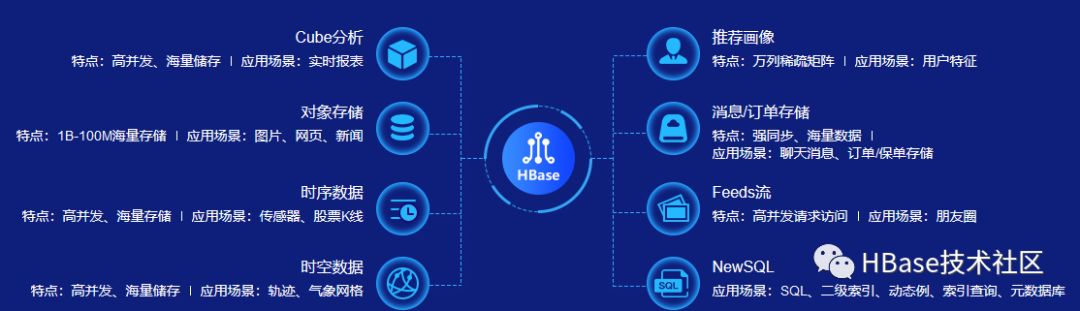
云HBase已经通过阿里云的公共云、专有云及混合云的形态对外服务,用户覆盖社交、金融、车联网、物流、零售、电商、共享出行等数十个行业,帮助用户顶住千万级QPS的业务压力,以及PB级数据高效存储和处理。
HBase2.0支持多region replicas服务,充分利用集群资源支持更高并发随机读。进一步加强了HBase高并发多读能力,因此非常适合车联网等物联网场景。
除了在物联网场景的应用,我们知道不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中。HBase2.0支持中等对象存储,兼容原生api读写访问以及bulkload等,合适企业存储一些附件文档、图片数据,而不需要企业另选其它对象存储系统,大大简化企业后台数据架构。在存储上支持各类数据,包括日志、订单、交易数据、消息等,在线实时写入,实时查询。
通过对读写全链路优化,rpc改进等,比随机读写延时更低。同时满足了金融级分控,推荐等核心场景的极致时延和稳定性要求。
历经近8年的技术沉淀,阿里巴巴大数据NoSQL数据库处理技术的精华沉淀在HBase上,后者成功支撑了成功支撑了阿里经济体中最大的NoSQL业务体量,是阿里大数据处理技术的核心组成部分,当前将这项技术应用到广大企业中,助力企业发现数据价值。

【HBase生态+Spark社区大群】
1.技术交流钉钉大群【强烈推荐!】 群内每周进行群直播技术分享及问答
加入方式1:
点击链接申请加入 https://dwz.cn/Fvqv066s
加入方式2:
钉钉扫码加入:

注明云HBase交流
往期【直播技术分享】和专家面对面【在线回答技术问题】
1.HBase多模式:HBase多模式,包括 分析层:支持复杂分析、算子下推;多模式层:提供各种模型转换,贴切业务;索引引擎:提供索引支持,基于 Lucene ;存储引擎:提供 KV 支持,基于LSM;分布式文件层:保障低成本、与上层分离、共享降低成本。
https://yq.aliyun.com/articles/665319?spm=a2c4e.11153959.0.0.5d8f164a5rw4qN
2.HBase内核及能力:HBase内核及能力 包括:HBase的特性与生态:自动分区、LSM Tree、存储计算分离、HBase生态;全新的HBase2.0版本新功能:小对象存储MOB、读写链路Off-heap 、Region Replica 、In Memory Compaction 、Assignment MangerV2 ;HBase未来规划。
https://yq.aliyun.com/articles/669836?spm=a2c4e.11153959.0.0.5d8f164a5rw4qN
3.Spark介绍及Spark多数据源分析:开源大数据处理首选Spark,Spark引擎助力数据构架升级,大数据构架分为多种系统,如:流式处理系统、离线分析系统、算法分析系统、交互式分析系统,通过阿里多模型数据库专家沐远的讲解学习Spark并解决各种业务问题。
https://yq.aliyun.com/articles/672452?spm=a2c4e.11153959.0.0.6dd3164aPLssuz
欢迎关注HBase+Spark团队号https://yq.aliyun.com/teams/382博客,问答,直播,各类HBase资料,线下Meetup都发布到这里。
以上是关于HBase2.0商用首发--有哪些值得期待的新特性的主要内容,如果未能解决你的问题,请参考以下文章