HBase在G7的应用与实践
Posted G7Tech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase在G7的应用与实践相关的知识,希望对你有一定的参考价值。
整体架构
先简单介绍下G7数据处理的整个流程:
安装在车辆上的车载设备(G7自研,其他设备)通过传感器和车辆信号获取车辆实时状态数据;
数据通过网络层的过滤,验证,将数据发送到解析层;
解析机根据对应的消息协议解析数据,将解析后的数据写入到MQ中;
MQ缓存解析机解析的所有数据,供业务端消费使用;
加工层分为实时计算和离线计算,根据业务需求计算处理数据;
存储层用于存储加工层处理的结果,以供业务系统查询使用,HBase就在这一层;
分析层主要是对存储层的数据进行更深入的分析计算,形成应用层的一些数据产品并提供相应的服务接口,比如公司的一些主要业务:里程、轨迹、事件等。
数据特点
业务数据的特性直接决定了存储选型,而G7作为一个物联网企业,我们的数据有以下的一些特性:
传感器数据
实时性要求高
数据种类多
数据量大
数据结构简单
过期数据低频访问
我们的数据都是来源于车辆终端设备上传的,都是传感器数据;在车联网的场景,很多业务对数据的实时性要求非常高,比如疲劳等,如果延时造成的后果可能非常严重;由于车辆终端设备的种类多,并且我们采集的数据种类也很多,所以我们的业务数据类型繁杂。我们的车辆基数大,每辆车上的传感器也不止一个,并且按照业务需求我们采集数据的频率也不一样,有分钟采集的,有十秒采集的,也有每秒都采集的,所以我们的数据量非常庞大;而庞大的物联网数据大部分都有一个共性,就是过期的数据访问频率很低,更久远一点的数据基本就不会访问了,使用方式更趋近于统计分析的作用。
技术选型
在我们的业务数据特性清楚的前提下,我们对比了很多的存储组件,比如MongoDB,Cassandra等,但是我们最终选择HBase作为我们的实时海量数据存储组件,主要因为HBase有一下特性:
扩展容易,可用性高
读写取性能高
吞吐量大
过期数据清理简单
HBase是存储计算分离的架构,底层依赖于Hdfs做存储,多副本,稳定性和安全性高,计算层以Region为单位,Region不依赖于具体的节点,当单个节点不可用时Region可以自动迁移,然后继续提供服;HBase在查询数据时,通过查询Meta表能够准确获取到数据所在Region,类似于HBase中所有的数据都有一个索引,并且各级都有相应的缓存,所以读取性能非常高;HBase牺牲了多维度查询,但这也使他结构相对简单,写入数据时就单纯的插入数据,不会去考虑太多,使他有非常高的吞吐;同时物联网场景中清理过期数据是家常便饭的事情,HBase使用TTL的方式自动清理过期数据,在物联网场景中是最合适不过了,所以我们最终选择了HBase作为我们的海量实时数据存储。
业务应用
HBase接入
我们对HBase的定位是一个实时海量数据存储的平台。使用方是整个公司,所以为了方便整体的管理和提高集群的可维护性,我们封装SDK,提供了如下功能:
基本功能
ORM
日志上报
双活切换
首先要满足的是日常使用的基本功能,就是将HBase原生的功能进行封装并提供使用,比如:写入、查询等功能;并且我们为了降低业务方的接入难度,我们采用的ORM,就是将HBase原有的插入数据的方式进行改造,将HBase表的属性,如:列名、列蔟等与对象属性进行绑定,这样业务方不需要太了解HBase,就能够像操作对象一样操作HBase表。为了方便判定集群的健康状况,以及业务方使用是否良好,我们在SDK中将查询HBase慢或者查询异常的一些请求以及客户端信息上报到中心管理服务器,供运维管理和优化使用。要能够做这样的事情,只有标准统一接入才能够实现,这也体现了标准化的重要性。因为SDK是统一的入口,因此,我们的双活切换也是通过SDK来实现的。
里程计算
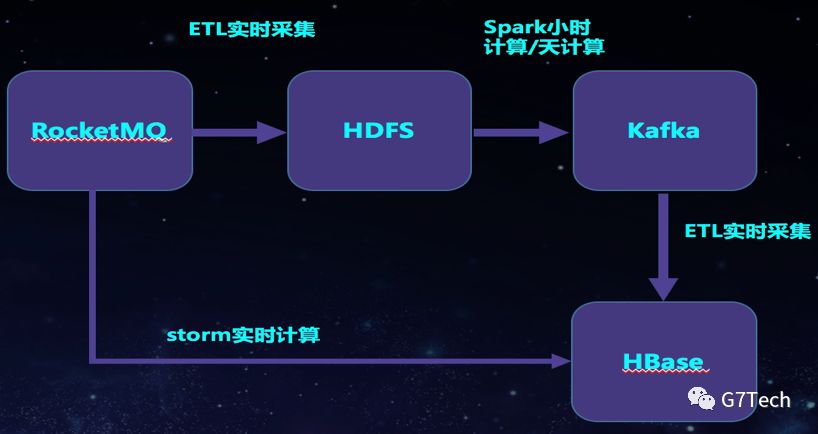
里程计算是公司的最核心的业务之一:经过解析过后的定位、经纬度数据都是存入了MQ中的。Storm会实时消费MQ中的定位数据,通过合并、聚合等算法,计算出车辆的里程数据并存储到HBase中。这是初步结果,因为网络原因,GPS漂移等问题,数据有一定的不准确性,因此还有一个补偿算法,我们会通过ETL将数据实时采集到Hdfs,然后Spark Sql通过小时计算和天计算来进行深度计算,包括补偿算法,缺失值修复,异常值剔除,最后计算出最终里程数据写到MQ,再消费写入HBase。
以上是里程计算的架构设计,我们再来看下,对于HBase的表我们是怎么设计的,对于表的设计我们主要考虑了以下两方面:
Rowkey设计
列设计
HBase是单维度查询,因此HBase的Rowkey设计一定要满足业务查询条件,要达到能够通过Rowkey能够过滤出所需要的数据,里程的业务查询需求是查询一辆车在某一时间的里程数据,因此我们的Rowkey是需要车辆的唯一标识(imei)+时间就能够满足查询需求了。同时我们在设计Rowkey时还有一个非常重要的考虑点就是防止热数据,也就是要让数据分散到所有的节点上,这样才能够发挥集群的优势。常用的防止热数据的方式有:反转、加盐和hash,我们采用的是反转,因此我们最终设计出的里程表的Rowkey为:Reverse(imei)+00000+String(date),中间的0主要是为了以后车辆编号长度的调整做的预留位。
对于列的设计我们很大的一个考虑点就是成本问题,HBase的存储都是Key-Value,Key包括了列簇和列,因此在HBase中存储了大量的元数据,所以我们在设计列的时候要充分的考虑减少元数据,因此我们的做法是:以业务读取数据的需求分组,将相同读取需求的数据放在同一个列或者列蔟里面,以json的形式存放,这样多列数据就合并成了一列,减少了大量的元数据。这是我们设计所有HBase表的时候都会考虑的一个方式。
报文系统
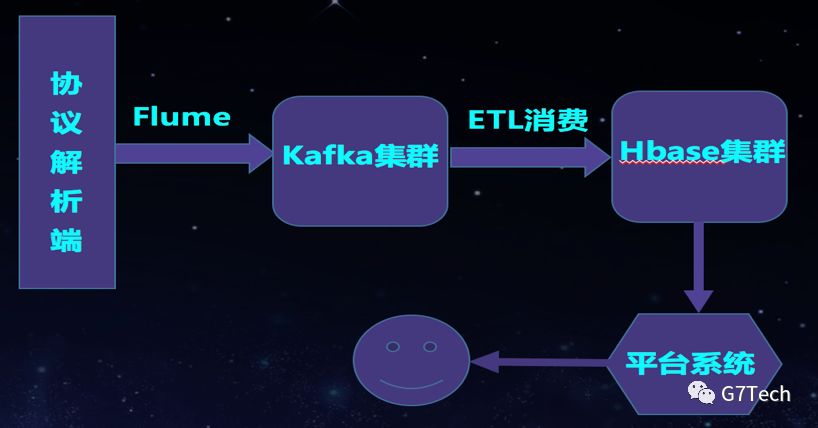
报文系统的主要功能是存储传感器上传上来的原始报文,供内部人员测试和排查问题使用。因为存储的是所有的原始数据,所以数据量很大,同时这个系统的使用是内部人员使用,因此会使用一个尽量低配置的集群来满足需求。并且在需要使用的时候要求能够立刻查询到数据,所以对数据的实时性有要求。
根据需求我们的集群要达到的要求是:低配置,高吞吐,写多读少,有实时性要求,因此我们最终优化出的集群效果为:
Ø 降低Read Buffers,加大Write Buffers(Memstore):
Ø 读写队列分开,增多写队列,减少读队列
Ø 设置低TTL
Ø 关掉WAL log
通过以上的优化过后,我们集群的吞吐有了很大的上升,尤其是关掉WAL log过后,集群的写入性能提升了3倍以上。关掉WAL log最大的问题就是数据的安全性问题,那么我们的解决办法是定时flush,让数据落盘。如果真的出现了小概率事件宕机,我们会另外启动一个新的Kafka消费组,将偏移量重置到最后一次flush的时刻,然后重新消费这一段时间的数据,来达到数据的完整性。
数据分层

物联网的数据量是很庞大的,我们从成本、可用性、扩展性等方面综合考虑,将数据分为热数据、温数据和冷数据,热数据为在线数据,访问非常频繁,而温数据的访问频率较低,冷数据的访问基本是用于统计分析使用,不会直接查询访问。因此,我们将热数据放在了扩展性和稳定性有优势的公有云上,温数据我们放在了成本可控的私有云中,而冷数据我们存在了私有云的离线存储Hdfs上,主要用于离线计算分析使用。业务系统对热数据和温数据的查询,我们是通过SDK路由访问。
稳定性建设
我们在使用HBase的初期,由于接入业务也较少,集群压力不大,同时也为了快速发展业务,我们一味的追求,方便,快速,而忽略了稳定性、规范性,所以在接入业务到达一定量的时候,我们频繁的出现很多问题,严重影响了我们业务的稳定性,比如:
HBase Request有时候突然很低,大量请求都超时
HBase总是会定时的出现请求超时,几分钟后,又自动恢复有
长时间的RIT,无法提供服务
完善监控
刚开始,在出现问题的时候我们整个的一个感觉就是举足无措,我们只有查看日志,看一下机器是否有问题,能够看到就是有问题,但是也不知道是什么问题,并且很多时候发现问题都是来源于业务方告诉我们有问题,我们自己的监控报警覆盖不全。我们当时就想的监控太弱,一定要大力完善监控。因此我们整体做了如下的监控:
基础监控
集群监控
表监控
连接监控
基础监控主要是HBase的一些普通的Metrics,比如:机器性能指标,gc,99线等等,用于日常的排查HBase新能等问题;集群监控就是将不同的HBase集群的吞吐量做为监控,并且获取一个业务范围的吞吐值,用于报警判定集群是否健康。表监控是监控一张表的tps,主要体现在单表过量tps影响集群性能的判定。连接监控用于每个客户端的连接数变化监控,能够判定集群是否有大量导数据影响集群整体tps等问题。
通过以上的一些监控和一段时间的升入排查,我们排查出HBase初期不稳定的主要原因有以下一些:
单表不合理的数据请求
协处理器影响集群
导数据全表扫描
gc不合理
针对单表不合理的请求,造成了大量的Scan数据影响集群性能,我们的解决办法是通过HBase的Quota限流来解决。而协处理器的话在我们的具体业务中对他的使用不是重度使用,所以我们关闭了协处理器功能,业务上的使用需求我们通过其他方式实现。对于导数据造成大量全表load集群数据,影响实时业务的问题,我们是将导数据统一改成实时的从MQ中去采集来代替直接从HBase中批量导。而gc的影响会造成很多的毛刺,我们通过优化垃圾回收来减少gc的时间、次数以及尽量避免full gc。
通过一系列的调整优化,在优化在调整,HBase的稳定性得到了保障。HBase的吞吐曲线基本是一条有规律的,稳定的曲线,极少出现毛刺影响业务的情况。
HBase双活
像HBase这种实时海量数据、高频访问的分布式数据库,他的维护难度是很高的,即使投入再多的人力研究也不能够保证他不出现问题,并且这种复杂的分布式系统,一旦出现严重的问题,往往不是短时间内能够修复的。所有,双活是保障整个系统稳定性的唯一出路。
我们为了尽量减少对HBase集群的影响,我们的双活是依赖于MQ来实现的,我们会在MQ层将数据实时同步出来,分别消费,然后以相同的逻辑处理并分别写入对应的HBase集群。在读取数据的时候我们在SDK中会自动判断,如果发现主HBase集群不可用时,SDK会自动的将请求切换备集群上去的,这中间有很多的判断和实现逻辑。当然在某些情况下SDK是无法正确切换的,比如集群健康状况都正常,但是里面的部分数据出现问题,那么这样的情况我们是需要手工切换的。我们有专门的HBase配置管理中心,可以通过配置强制切换HBase的主备节点。
平台建设
我们开发了一套数据存储平台,HBase为其中的一部分,平台主要是用于管理人员的管理和业务人员的日常查询使用。功能主要包括:对HBase的表管理,数据查询,数据修改,监控,双活切换等功能。通过平台我们能够大量的解放自己的时间,方便业务方的使用,同时能够减少运维人员直接的对服务器的操作。
未来规划
以上是我们目前的HBase的部分使用情况介绍,在基本稳定了目前的使用过后,我们也定下了未来一段时间的规划:
HBase2.0
Phoenix深度配合使用
HBase标准统一写入
形成HBase的存储体系
HBase2.0是一个大版本的更新,里面的很多优化,新特性都是期待已久的,比如:读写链路Off-Heap、Region Replica 、Assignment MangerV2等等,因此我们会逐步的使用HBase2.0。Phoenix对HBase多维度查询的补充大大弥补了HBase的不足,我们已经在使用Phoenix了,接下来我们会更加的深度使用。对于一些固定的消费MQ,写入HBase的通用入库,我们会提供统一的写入。最后,HBase本身是一个数据库,但很多时候他也是一个存储,我们会以HBase作为底层存储,形成一个HBase的体系来使用。
以上是关于HBase在G7的应用与实践的主要内容,如果未能解决你的问题,请参考以下文章