HBase实战 | Bit Map在大数据精准营销中的应用
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase实战 | Bit Map在大数据精准营销中的应用相关的知识,希望对你有一定的参考价值。
本文根据58同城何良均老师在DataFunTalk数据主题技术沙龙活动“大数据从底层处理到数据驱动业务”中分享的《Bit Map在大数据精准营销中的应用》编辑整理而成,在未改变原意的基础上稍作修改。

今天分享主题分为四个方面,第一个是项目背景,第二个依据项目需求的技术选型,接着就是项目架构,最后讲一下项目实现过程中的一些细节。


技术选型依据数据特点,数据量大但也不是特别大,有千万级标签+十亿级用户;依据项目需求,需要很多维度,用户标签分布于几百上千个维度,没有度量概念,度量和维度都是olap中的概念。除了数据之外还有产品要求,需要在线应用,性能要求较高,必须做到毫秒级响应;数据量不断增长,必须做到底层数据存储和计算可扩展性以应对数据量的增加;同时希望产品不属于用户方,再出现问题时能够很容易恢复,需要代码可控。

基于这些需求,对开源技术进行相关调研,像Kylin/Druid都是多维分析常见的工具,但是我们并没有使用。这两个框架都会做一些数据预计算/聚合,都能做到亚秒级查询,像Kylin底层是基于HBase可扩展性很强,Druid本身就是一个分布式系统,两个框架都是开源。但是我们选用Bit,因为依据数据需求简单而且Bit只有维度没有度量,还有就是维度个数多,查询是基于用户uid,查询明细数据。在查询明细中Druid有两个问题,如果将uid和维度存储Kylin和Druid,对维度的基数有限制,会构建维度字典,光一个uid就有4G,因此在几百上千维度查询效率会降低;还有一个就是uid用户量大,Kylin和Druid会将uid和其他维度进行组合会出现很多情况,会额外增加数据量,因此这种请款也不适合用Kylin,还有就是Kylin会对维度构建索引,uid索引会很大,查询效率也是很低。基于这些要求还有其他一些技术需求,最终方案是使用HBase+BitMap的自研框架,HBase主要做数据存储,将HBase做处理器做并行计算,BitMap构建索引。
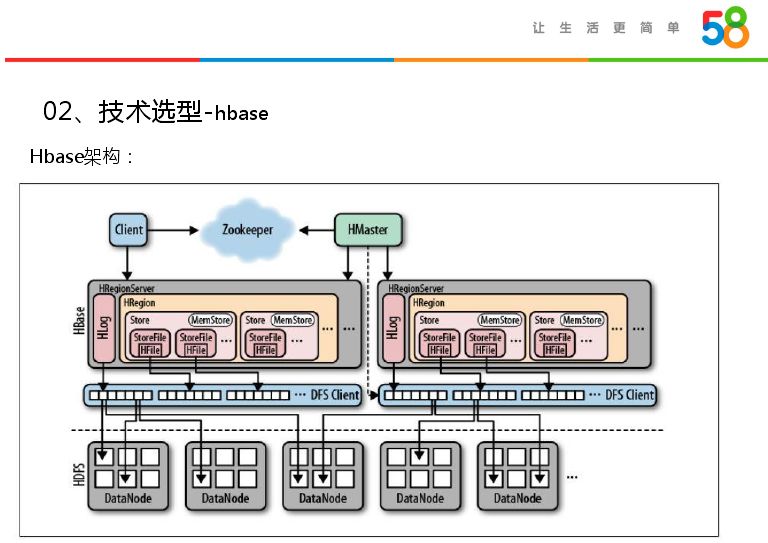
HBase是由一个active和region master作为服务主节点,有Hfile子节点和多个region server,底层是HDFS层,每一个region server管理很多region,每一个region会根据数据量会有很多Store file,这几者是依靠客户端协调。接着说一下HBase表分区,HBase表里面很为很多region,我们一般会设置每个region的最大值达到最大值自动分裂。而每一个region会有管理范围,分区是用region server管理。
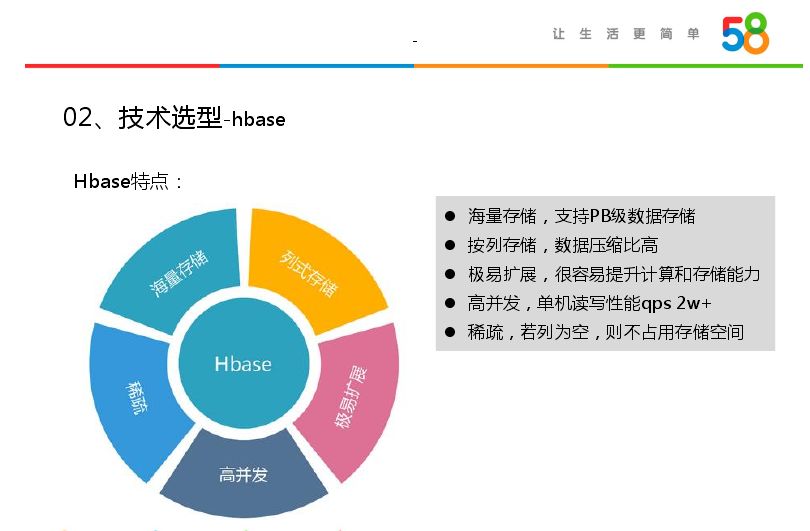
HBase有很多特点,第一个就是海量存储,其底层是基于HDFS,是横向存储,可以加很多节点,支持PB级数据存储;按列存储,将树属性相似的放到列组里面,压缩比比较高;第三个就是极易扩展,分为存储和计算,都是分布式存储和计算;然后高并发,单机读写性能在2w+;第五个就是稀疏,当列中属性为空,不占用存储空间。
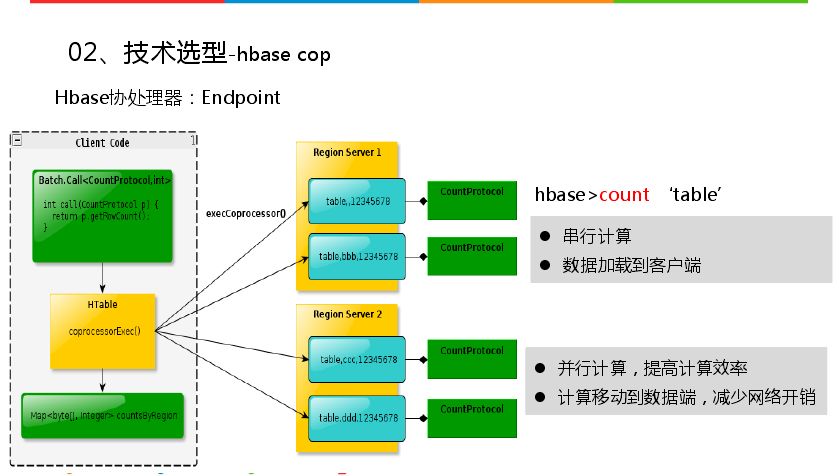
前面讲存储是HBase,计算是HBase协处理器,HBase协处理器分为两种,一种是Endpoint,一种是region server。与数据中存储过程和触发器类似,项目用的是Endpoint,类似于数据库中的存储过程。上图左右两边目的相同都是统计表的行数,不用协处理器会直接在命令行中count相关表,从每一个region里面扫描最后得到结果,这种方式耗时很大,由于串行计算,同时会将数据从服务端加载到客户端。Endpoint会以并行方式实现,会将客户端请求发送到所有region上,每个region分担数据量,最后将数据返回协处理器客户端,然后汇总聚合,这样运行速度快很多。速度快一个是并行计算,另一个是将计算的数据移动到服务端,这样数据稳定性高,直接从本地加载数据计算也会减少开销,协处理器返回客户端是数据的数量。

可能你们会对BitMap了解很少,其应用场景比较单一,但是在某些方面效果比较好。BitMap底层实现是一个位数组,位数组的value取值只能是0或1,因为是数组,数组下标是整数范围内的取值,最大为2147483647。上图中长度为10的BitMap,通过BitMap的api进行相关设置,会将对应的下标设置为1,如图中6、3、5、7的下标都设为1。BitMap可以进行布尔计算,可以求交集和求并集,其取值是0或1(或者是或否,出现与不出现),节省存储空间。BitMap的应用一个是数据排序,排序要求数据不能重复。第二个就是Bloom filter,是对应于一组hashmap对应一个BitMap,是牺牲一定错误率来释放存储空间,如在HBase的索引和爬虫URL判重。但是重点是作为索引,其实它在数据库、搜索引擎和OLAP应用很多。
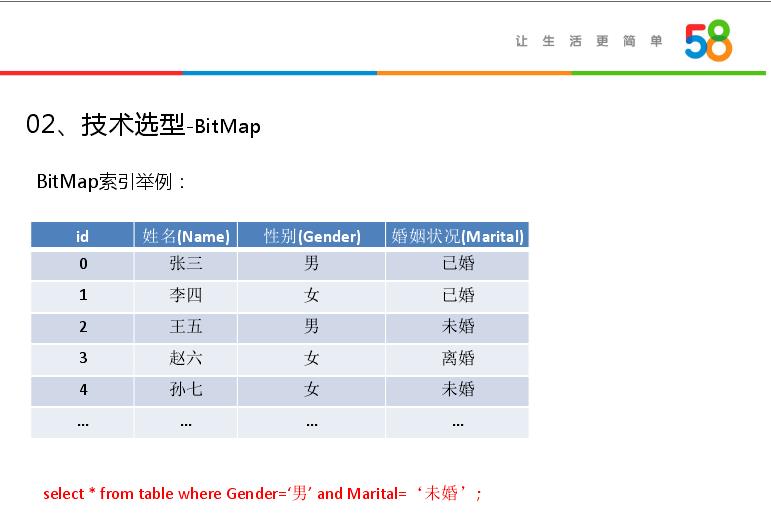
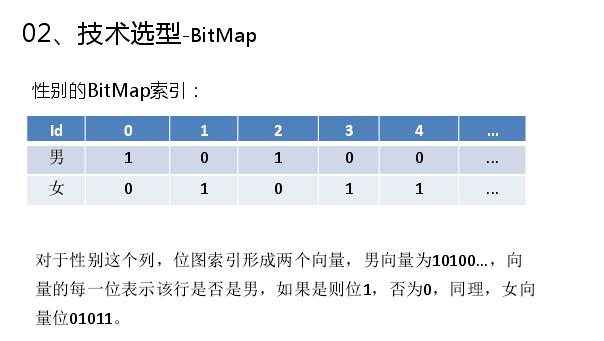
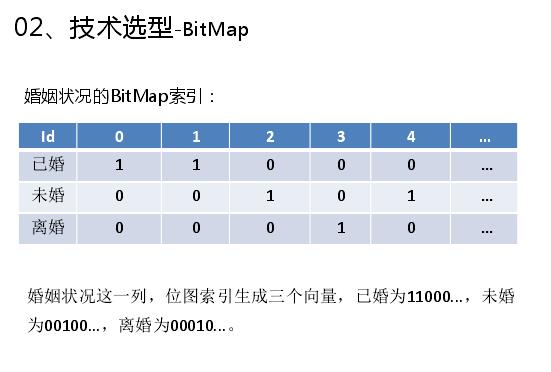
举一个例子说明下,如上图是一个数据表有四列,下面是一个简单查询,查询有性别和婚姻状况两个维度,性别有两个取值,婚姻状况有三个取值,BitMap首先会在维度里面构建BitMap,第一步如何构建性别的BitMap,对于性别这个列,位图索引形成两个向量,男向量为10100...,向量的每一位表示该行是否是男,如果是则位1,否为0,同理,女向量位01011。第二部构建婚姻状况的BitMap,婚姻状况这一列,位图索引生成三个向量,已婚为11000...,未婚为00100...,离婚为00010...。这样就构建完需要查询的BitMap,首先将性别为男的标签拿出来,然后将婚姻状况为未婚的标签拿出来求交,这样就定为下标为2,就查出满足需要的结果。
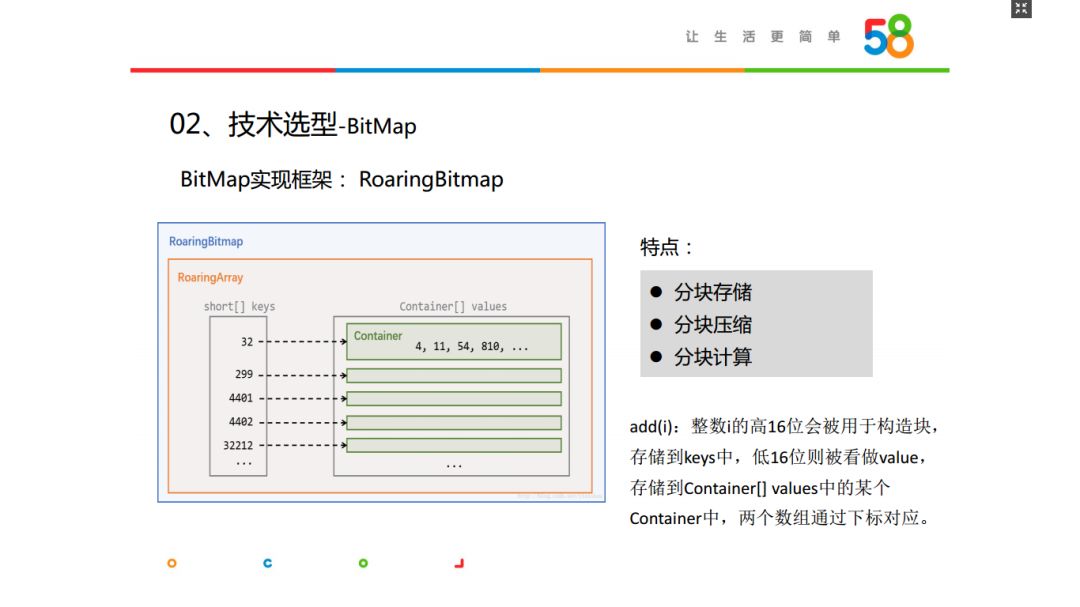
BitMap有很多实现方式,构建框架也有很多。最后我们选用Roaring Bitmap,选择的原因在于:我们存储的是整数,将下标标签取值设为1,该框架将整数i的高16位会被用于构造块,存储到keys中,低16位则被看做value,存储到Container[] values中的某个Container中,两个数组通过下标对应。BitMap是分块实现的,有三个特点就是分块存储、压缩、计算,这样在BitMap使用时可以按块解压节省内存空间。但是在计算时必须全部解压。Roaring Bitmap在开源框架里应用很多,如OLAP中有Kylin、Druid、Piont等,搜索引擎方面有Lucene、Solr、Elastic Search等,还有Spark、Hive、Tez等。也有很多实现语言,比如Java、C、C++、Python等。
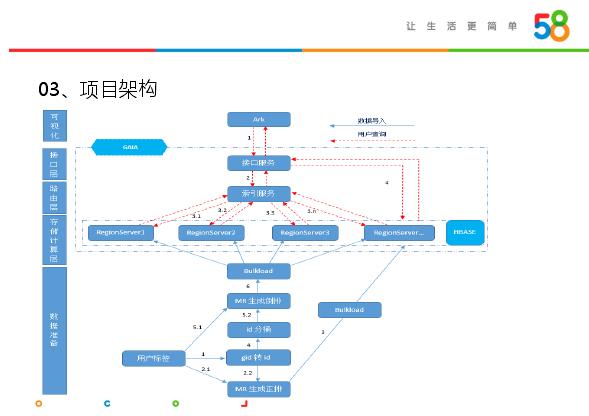
前面介绍了项目背景、技术选型,接下来介绍下基于HBase和BitMap实现的项目框架构建。上图是项目整体架构,因为是用户从页面构建标签,因此从上到下分为几个模块。可视化层,给用户提供页面,选择标签,然后接口层传入标签,提供API服务,将选择标签传入路由层,构建索引服务,在索引服务中会判断是存客营销还是新客营销,页面标签是求交还是求并;然后索引服务将标签部署于服务器的region server上,在存储计算层,通过协处理器存储查询。通过标签和startkey构建rowkey,然后查询数据,在BitMap中进行求交、求并的操作,最后将结果返回给索引服务,索引服务将结果返回前端页面,用户拿到的是匹配到的uid。存储计算层还好,主要发费在数据准备阶段,需要考虑很多东西。数据量大(十亿级标签)并不能直接构建BitMap,需要做这些用户标签做MR生成倒排、uid分桶、gid转id,通过bulkload生成BitMap索引,然后传入region server里面,提供相关服务。
数据准备层完成uid转连续整数id,根据最大id分桶,标签分桶生成Bit Map索引,并序列化后生成HFile,Bulkload Bit Map索引。存储计算层完成HBase:存储索引数据,HBase cop:分布式计算,Roaring Bitmap :索引,布尔计算,求交求并。路由层实现计算请求参数:新客营销、存客营销,将请求通过cop路由到Region Server。接口层完成使用netty构建http服务,接受前端查询请求并解析接口层。可视化层完成标签选择,查询客群,下载客群。
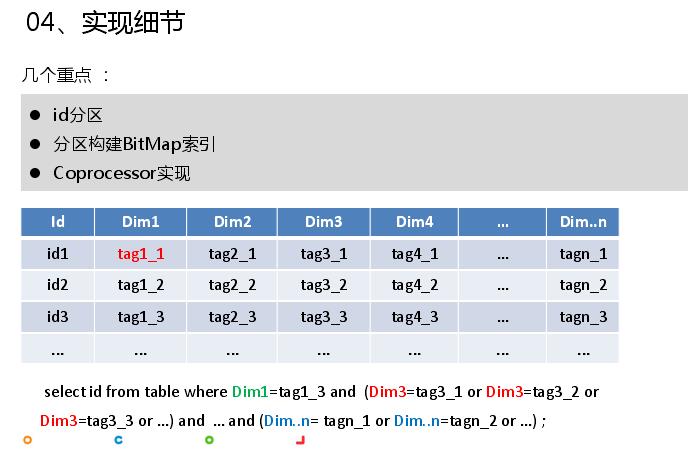
接下来讲一下第四部分实现细节,讲几个关键重点:id分区,分区构建BitMap索引,coprocessor实现。用户有十亿,并不是直接将数据构建BitMap,会对id进行分区,依据分区构建BitMap。将uid进行转义成id,为连续整数,因为BitMap里面是整数。原始表有很多维度,每个维度有很多标签,通过标签求交求并筛选出需要的结果。

Id分区有两个问题,一个是为什么id要分区,第二个是如何进行id分区。首先说第一个,BitMap是依据标签查询的,id不分区,下标很长,十亿标签有100M,不能很好结合HBase协处理器的并行计算能力,查询效率很低;每个标签构建的bitmap索引长度达到10亿级,存储开销大;id不分区,如果id超过了整数最大范围,无法构建BitMap索引。
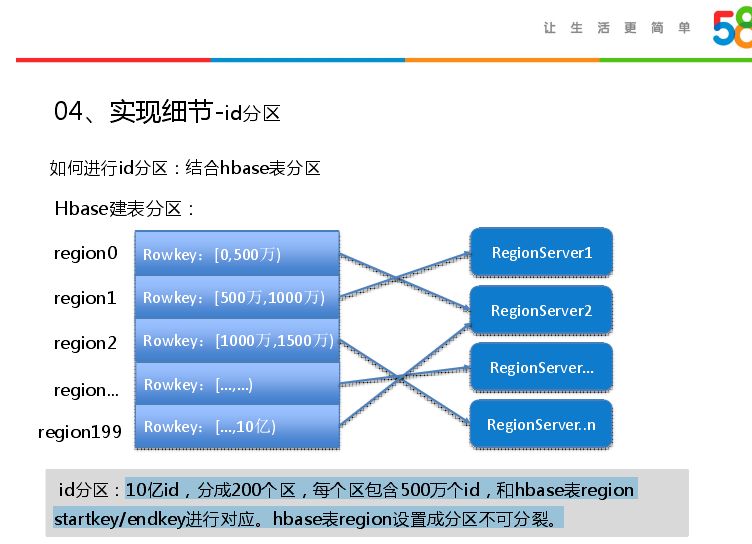
接下来说一下如何进行id分区,id分区用到协处理器,结合hbase表分区实现。如10亿id,分成200个区,每个区包含500万个id,和hbase表region startkey/endkey进行对应。如和region里面的rowkey,0-500万相当于第一个分区,region分区是和hbase分区结合在一起,因此每个region只包含500万个账号。同时我们指定rowkey范围,不需要hbase表进行分裂,将进行关联hbase表region设置成分区不可分裂,在建表的时候预先建好分区。下面是项目中建立表分区代码事例,将十亿数据分为200个分区:create 'index', {METHOD => 'table_att', METADATA=> {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.Disabled Region Split Policy'}},{NAME=>'d',COMPRESSION => 'SNAPPY'}, SPLITS => [‘0005000000’, ‘0010000000’, ‘0015000000’, ‘0020000000’, ‘0025000000’,‘0030000000’, ... ,‘09950000000' , '10000000000']。

建好表后就是如何构建索引,每一个分区对应500万的数据,通过roam构建BitMap时,会输出rowkey和value。将每一个region里面的标签设为key,标签会对应BitMap,region有范围只会生成相应的BitMap。如第一个region,startkey为0,构建的标签为200万,对应的下标是500万,region对应的是500万,存储的是500万-1000万的id,存储时会减去相应范围,因此长度还是固定的。
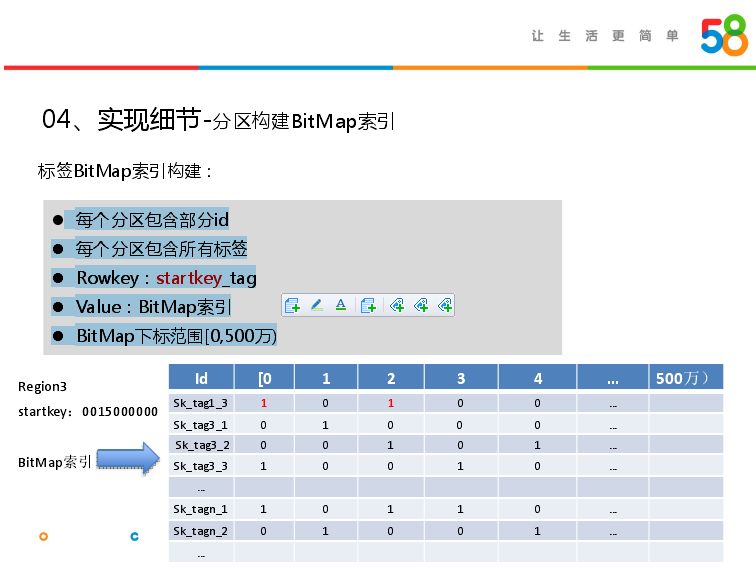
BitMap有几个特点:每个分区包含部分id,每个分区包含所有标签,Rowkey:startkey_tag,Value:Bit Map索引,Bit Map下标范围[0,500万)。在后续分区可能id很大,但是会startkey和id set设置一定偏移量,保证id取值范围永远是0-500万,避免id过大超出整数取值范围,避免用户量过大超出BitMap索引。如在region3里面构建BitMap的例子,startkey是1500万,每一个标签对应一个索引。
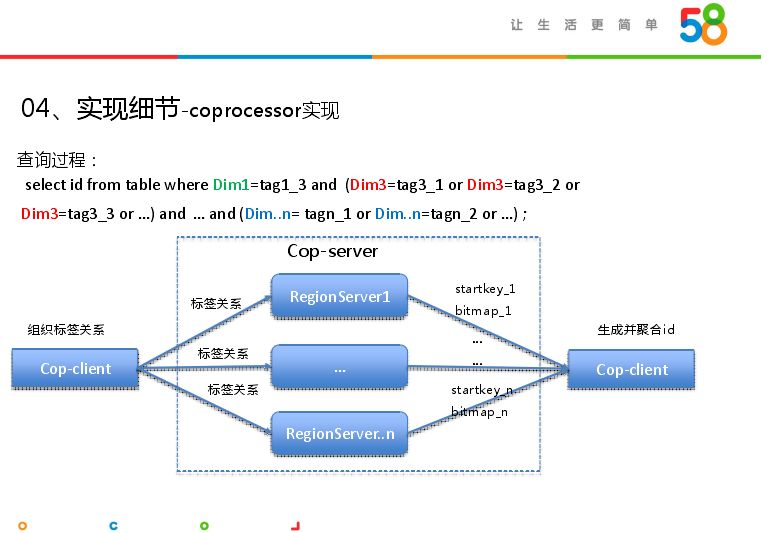
建完索引,接着就是协处理器实现——coprocessor实现,这个其实比较关键,扮演着并行计算的角色。如从很多标签筛选用户,里面可能有很多求交求并关系。协处理器会从客户端通过索引服务解析求交求并的关系,传给region server,传给协处理器的服务端,传入的参数并未发生变化。在region server会自动更新逻辑,会返回匹配到的id。Cop-client会组织标签之间的计算关系,即求交求并关系;将标签关系发送给Cop-server,比如查询select id from table where Dim1=tag1_3 and (Dim3=tag3_1 or Dim3=tag3_2 or Dim3=tag3_3 or …) and … and (Dim..n= tagn_1 or Dim..n=tagn_2 or …) ;用户选择相应维度,返回标签,协处理器客户端会将标签重新组织,变成相关关系tag1_3 and (tag3_1 or tag3_2 or tag3_3 or …) and … and (tagn_1 or tagn_2 or …),发给协处理器服务端。

上图是协处理器服务端完成的任务,首先拿到客户端返回的参数,主要是标签,第一步通过标签+startkey,构建rowkey,根据rowkey在当前region查询BitMap,然后依据标签间关系,对BitMap求交求并计算;最后返回一个BitMap和startkey返回给协处理器客户端。
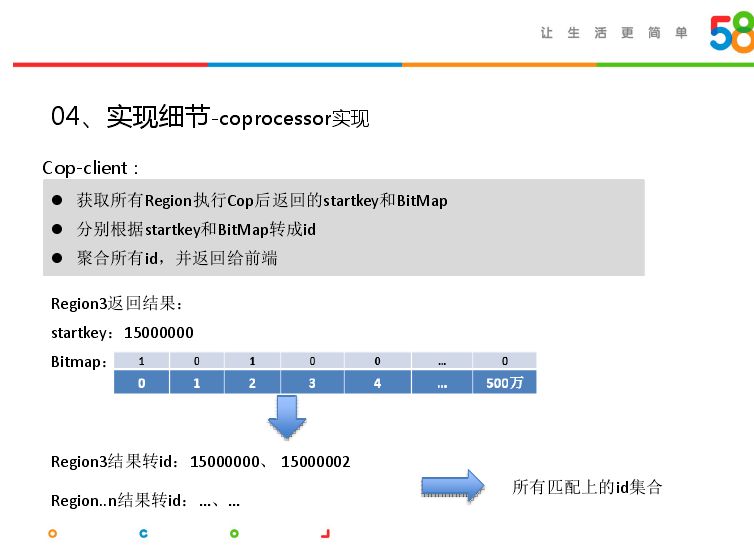
客户端拿到服务端返回的startkey和BitMap,可能有很多组,因此获取所有Region执行Cop后返回的startkey和Bit Map,然后在客户端返回匹配到的id,将所有region返回的结果聚合返回给用户。上图是region3的例子,返回startkey加上BitMap取值为1的下标,就得到查询到的id。
以上是关于HBase实战 | Bit Map在大数据精准营销中的应用的主要内容,如果未能解决你的问题,请参考以下文章