HBase基础 | 图数据库HGraphDB介绍
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase基础 | 图数据库HGraphDB介绍相关的知识,希望对你有一定的参考价值。
图无处不在,社交和电商领域每天都会产生大量的实体连接数据,而描述图的方式往往是使用包括顶点和边以及丰富的属性的属性图来展现。在如今的2018年,社交网络和电商数据往往能够形成非常大的实体图,包括数十亿顶点和百亿条边这样的数据量。而面对这样巨大的数据量,传统关系型数据库往往难以处理。
谈到为什么会出现图数据库,这就要谈到关系型数据表达能力远远不够的问题了。SQL表达非常复杂,往往需要多张表进行级联查询,而使用图数据结构则会更加贴近于真实世界。
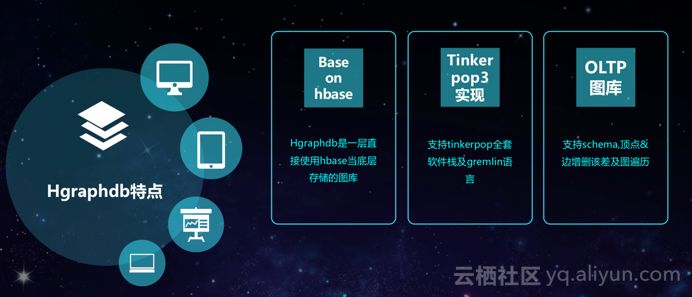
HGraphDB底层基于HBase进行数据存储,方便进行水平扩展。其次,HGraphDB基于Tinker pop3实现,因此支持集成Tinker pop3全套软件栈以及Gremlin语言。此外,HGraphDB是一个OLTP图库,支持schema以及顶点和边的增删改查还有图的遍历。
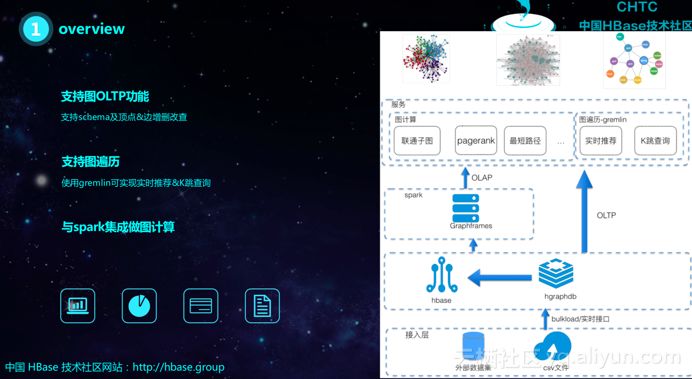
HGraphDB支持底层的数据接入,可以通过文件以及实时的对外接口访问到HGraphDB的数据层。其底层的持久化是在HBase上,通过Gremlin的图片里实现实时的推荐和K跳查询。而还可以通过与Spark的集成直接分析HBase数据库实现诸如PageRank、联通子图等常用的图计算。
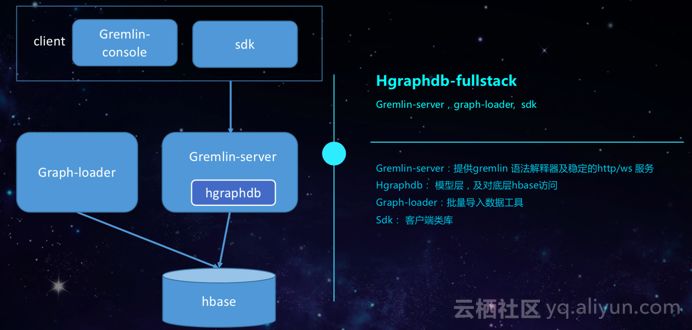
对于HGraphDB的全栈而言,因为偏向于OLTP,因此其核心在于Gremlin-server上,其内部包含HGraphDB的核心驱动层,其是底层的数据模型,主要负责底层对于HBase的数据访问。而因为很多用户往往携带数据使用HGraphDB产品,因此Graph-loader就可以做一些文件格式的解析,进而将数据批量导入到HBase数据库里面。Gremlin-server还能够提供HTTP和Web Socket服务,因此在客户端里面可以通过SDK、HTTP以及Web Socket来访问图数据库。同时,也可以通过命令行实现图的遍历以及计算等操作。
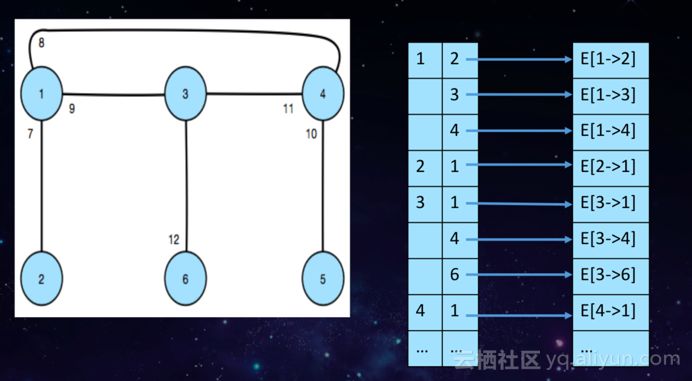
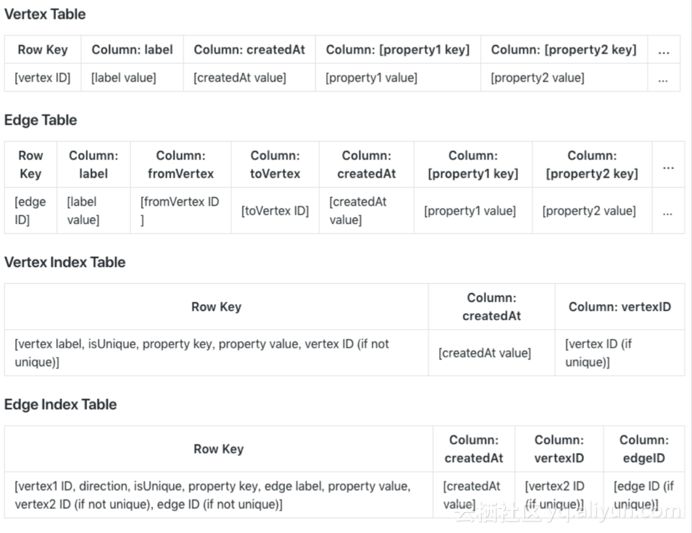
数据模型-全局有序索引表
因为HGraphDB提供的是属性图,因此包括顶点和边以及属性,而因为HBase是一个Key-Value的表格系统,因此很容易实现订单和边的属性集的持久化存储。但是在图里面,一跳二跳相对而言比较麻烦,对于此采用了全局有序索引表来解决,通过二级索引进一步找到全部属性集。
如下图所示的是底层表格存储的真实的Schema格式,可以看到能够将顶点相关的In和Out这些边紧密地放在一起,只需要进行一次运算就可以拿到所有的相关顶点和边的数据。而对于Vertex表和Edge表而言,其RowKey分别是其ID,属性则通过宽列或者宽表的方式表现出来。
Gremlin是一种类SQL的方言,如下图所示的就是Gremlin的DSL,也就是领域特定语言,而在Tinker pop中包含了Gremlin的解释器。
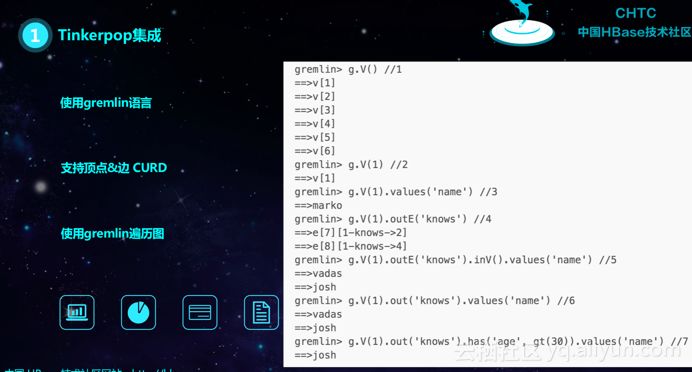
Gremlin执行引擎的执行计划如下所示,三个步骤会形成一个Pipeline,采用懒迭代方式,而底层会对于HBase数据表进行访问,并且其执行效率是非常高的。

仅有了图数据库的OLTP能力是远远不够的,还需要进行图分析,这一点是通过Spark graphframes实现的。Spark graphframes可以实现常见的分析,比如filter/agg计算、以及count和sum等。这些计算在底层可以转化成基于Graphx的图计算,进而可以实现pagerank、最短路径。实施推荐、最小生成树、联通分量以及kcore等计算。Spark graphframes既可以满足进行常规汇总统计的需求,也满足测试和机器学习相关的迭代计算需求。
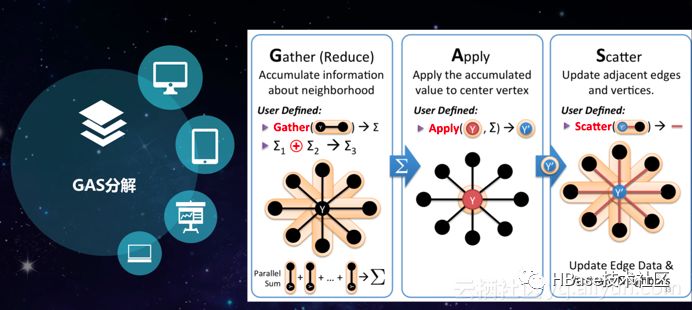
HGraphDB支持图计算的编程框架——GAS分解。GAS分解类似于MapReduce思想,其主要是面向顶点的编程思想,其包含了计算引擎在内,因此只需要编写想要实现的内容即可。也就是将程序拆解成三部分:Gather、Apply和Scatter。HGraphDB里面有很多分区,一个顶点会有多个不同的Partition,每个Partition里面先去做计算,之后将计算的值汇总到Master中,因此第一步叫做Gather。第二步叫做Apply,也就是改变Master节点的值。当将值修改完之后,Scatter步骤会将当前值分发到镜像顶点,将镜像顶点的值也更新完毕,同时通知邻接顶点重新进行计算。
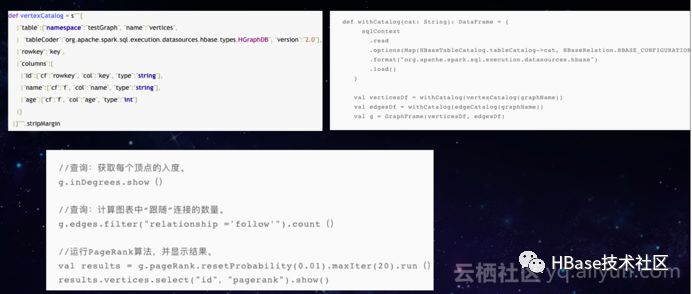
如下图所示的是使用Spark graphframes进行图分析计算的示例。
目前,HGraphDB产品已经开放到了阿里云上。而在实现HGraphDB的过程中也做了不同的技术选型,比如与比较热门的janusgraph进行了对比和评测。之所以选择基于HGraphDB,是因为其代码量比较小,功能比较明确,可以基于其进行重写和二次开发,但是janusgraph在做数据导入的时候可能无法导入或者效率极低,在数据量大的时候,性能也会急剧下降。而HGraphDB支持用户指定ID,而janusgraph无法实现。对于数据导入而言,janusgraph导入边数据困难,效率极低,而由于janusgraph需要支持底层所有表格存储系统,而HGraphDB直接基于HBase进行了优化。此外,janusgraph做了一层抽象,将HBase完全当成黑盒,因此性能表现不佳。

主要使用场景
用户360:因为HGraphDB提供的是属性图,因此可以很容易地拿到用户属性的子图。
个性化推荐:基于图能够很容易地实现个性化推荐。
欺诈检测:可以人工标注一些黑产顶点,如果和这个顶点太近,就可能存在问题。
未来改进方向
HGraphDB是Gremlin的DSL的一种标准实现,而Gremlin提供了很多钩子让用户自己实现执行器的优化,但是现在的HGraphDB目前传输的数据量比较大,并且自身的计算能力有限,因此做全表扫描比较吃力,所以在执行器上具有较大优化空间。此外,还可以将词聚合等算子下推,以及能够增强图分析能力,将Spark作为内嵌分析引擎,实现Tinker pop OLAP规范。
感想:在如今的2018年,社交网络和电商数据往往能够形成非常大的实体图,面对这样巨大的数据量,传统关系型数据库往往难以很好地处理,因此就需要图数据库来帮助解决。而HGraphDB底层基于HBase实现,支持Tinker pop3的全套软件栈以及Gremlin语言,并且支持OLTP等,是解决图计算问题一个非常优秀的工具。
以上是关于HBase基础 | 图数据库HGraphDB介绍的主要内容,如果未能解决你的问题,请参考以下文章