HBase二级索引方案
Posted 数说故事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase二级索引方案相关的知识,希望对你有一定的参考价值。

01 HBase简介
HBase是一个构建在HDFS之上,用于海量数据存储分布式列存储系统。
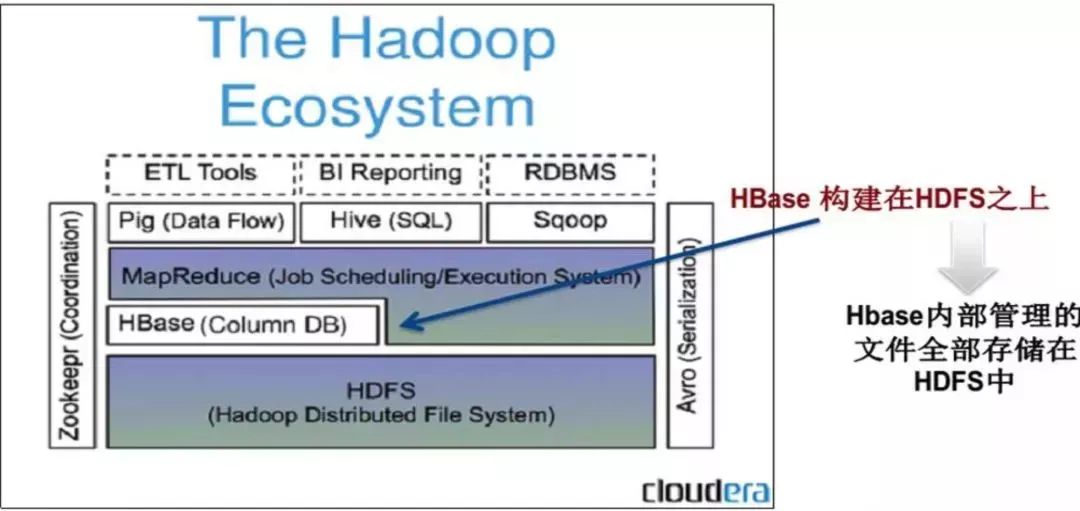
参见下图,由于在HBase中:
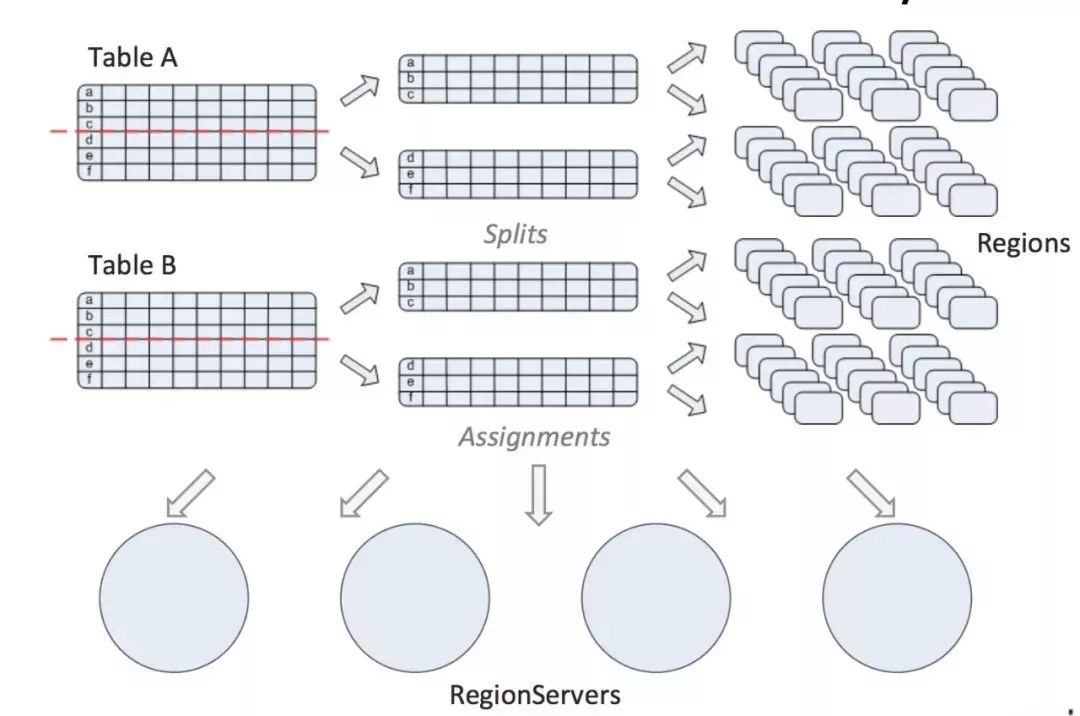
表的每行都是按照RowKey的字典序排序存储
表的数据是按照RowKey区间进行分割存储成多个region
所以HBase主要适用下面这两种常见场景:
适用于基于rowkey的单行数据快速随机读写
适合基于rowkey前缀的范围扫描
02 为什么需要HBse二级索引
HBase里面只有rowkey作为一级索引, 如果要对库里的非rowkey字段进行数据检索和查询, 往往要通过MapReduce/Spark等分布式计算框架进行,硬件资源消耗和时间延迟都会比较高。
为了HBase的数据查询更高效、适应更多的场景, 诸如使用非rowkey字段检索也能做到秒级响应,或者支持各个字段进行模糊查询和多字段组合查询等, 因此需要在HBase上面构建二级索引, 以满足现实中更复杂多样的业务需求。
03 HBse二级索引方案
基于Coprocessor方案
1、官方特性
其实从0.94版本开始,HBase官方文档已经提出了hbase上面实现二级索引的一种路径:
基于Coprocessor(0.92版本开始引入,达到支持类似传统RDBMS的触发器的行为)
开发自定义数据处理逻辑,采用数据“双写”(dual-write)策略,在有数据写入同时同步到二级索引表
2、开源方案:
虽然官方一直也没提供内置的支持二级索引的工具, 不过业界也有些比较知名的基于Coprocessor的开源方案:
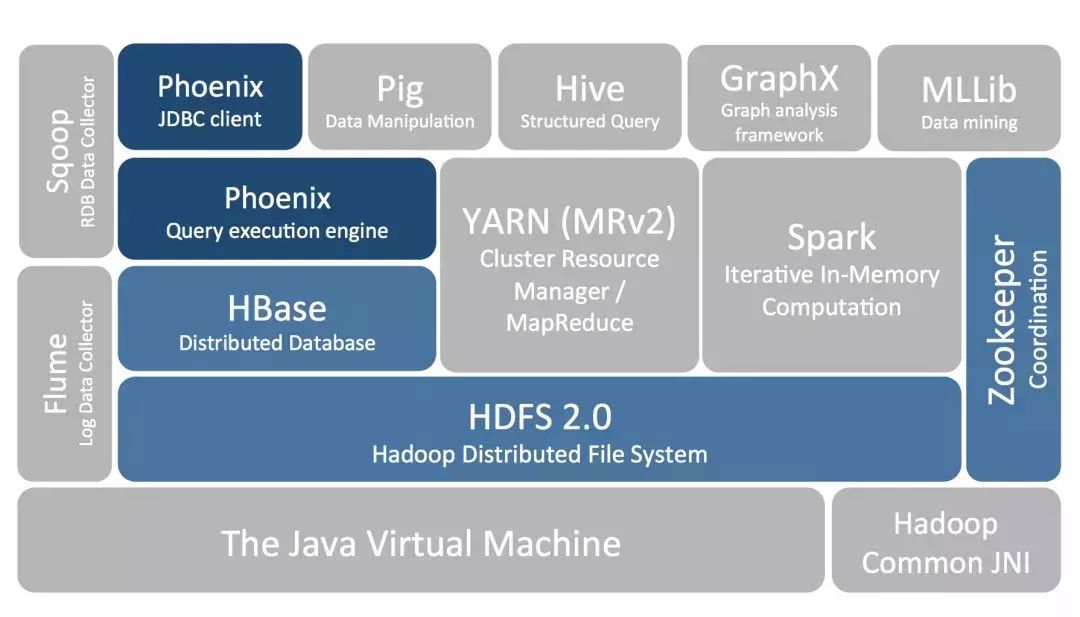
Apache Phoenix: 功能围绕着SQL on hbase,支持和兼容多个hbase版本, 二级索引只是其中一块功能。 二级索引的创建和管理直接有SQL语法支持,使用起来很简便, 该项目目前社区活跃度和版本更新迭代情况都比较好。
ApachePhoenix在目前开源的方案中,是一个比较优的选择。主打SQL on HBase , 基于SQL能完成HBase的CRUD操作,支持JDBC协议。 Apache Phoenix在Hadoop生态里面位置:
3、Phoenix二级索引特点:
Covered Indexes(覆盖索引) :把关注的数据字段也附在索引表上,只需要通过索引表就能返回所要查询的数据(列), 所以索引的列必须包含所需查询的列(SELECT的列和WHERE的列)。
Functional indexes(函数索引): 索引不局限于列,支持任意的表达式来创建索引。
Global indexes(全局索引):适用于读多写少场景。通过维护全局索引表,所有的更新和写操作都会引起索引的更新,写入性能受到影响。 在读数据时,Phoenix SQL会基于索引字段,执行快速查询。
Local indexes(本地索引):适用于写多读少场景。 在数据写入时,索引数据和表数据都会存储在本地。在数据读取时, 由于无法预先确定region的位置,所以在读取数据时需要检查每个region(以找到索引数据),会带来一定性能(网络)开销。
其他的在网上也很多自己基于Coprocessor实现二级索引的文章,大体都是遵循类似的思路:构建一份“索引”的映射关系,存储在另一张hbase表或者其他DB里面。
4、方案优缺点:
优点: 基于Coprocessor的方案,从开发设计的角度看, 把很多对二级索引管理的细节都封装在的Coprocessor具体实现类里面, 这些细节对外面读写的人是无感知的,简化了数据访问者的使用。
缺点: 但是Coprocessor的方案入侵性比较强, 增加了在Regionserver内部需要运行和维护二级索引关系表的代码逻辑等,对Regionserver的性能会有一定影响。
非Coprocessor方案
选择不基于Coprocessor开发,自行在外部构建和维护索引关系也是另外一种方式。
常见的是采用底层基于Apache Lucene的Elasticsearch(下面简称ES)或Apache Solr ,来构建强大的索引能力、搜索能力, 例如支持模糊查询、全文检索、组合查询、排序等。
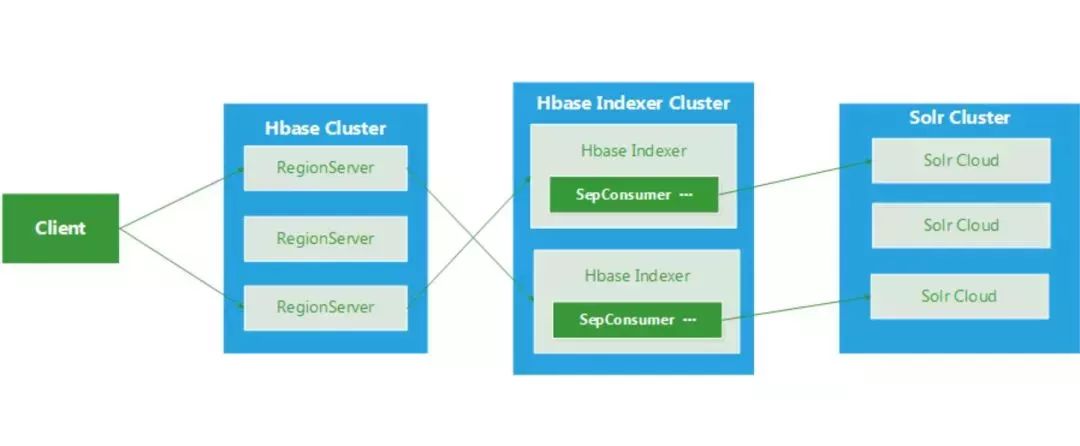
1、Lily HBase Indexer:
LilyHBase Indexer(也简称 HBase Indexer)是国外的NGDATA公司开源的基于solr的索引构建工具, 特色是其基于HBase的备份机制,开发了一个叫SEP工具, 通过监控HBase 的WAL日志(Put/Delete操作),来触发对solr集群索引的异步更新, 基本对HBase无侵入性(但必须开启WAL ), 流程图如下所示:
2、CDH Search:
CDHSearch是Hadoop发行商Cloudera公司开发的基于solr的HBase检索方案,部分集成了Lily HBase Indexer的功能。
下面是CDH search的核心组件交互图, 体现了在单次client端查询过程中,核心的zookeeper和solr等的交互流程:
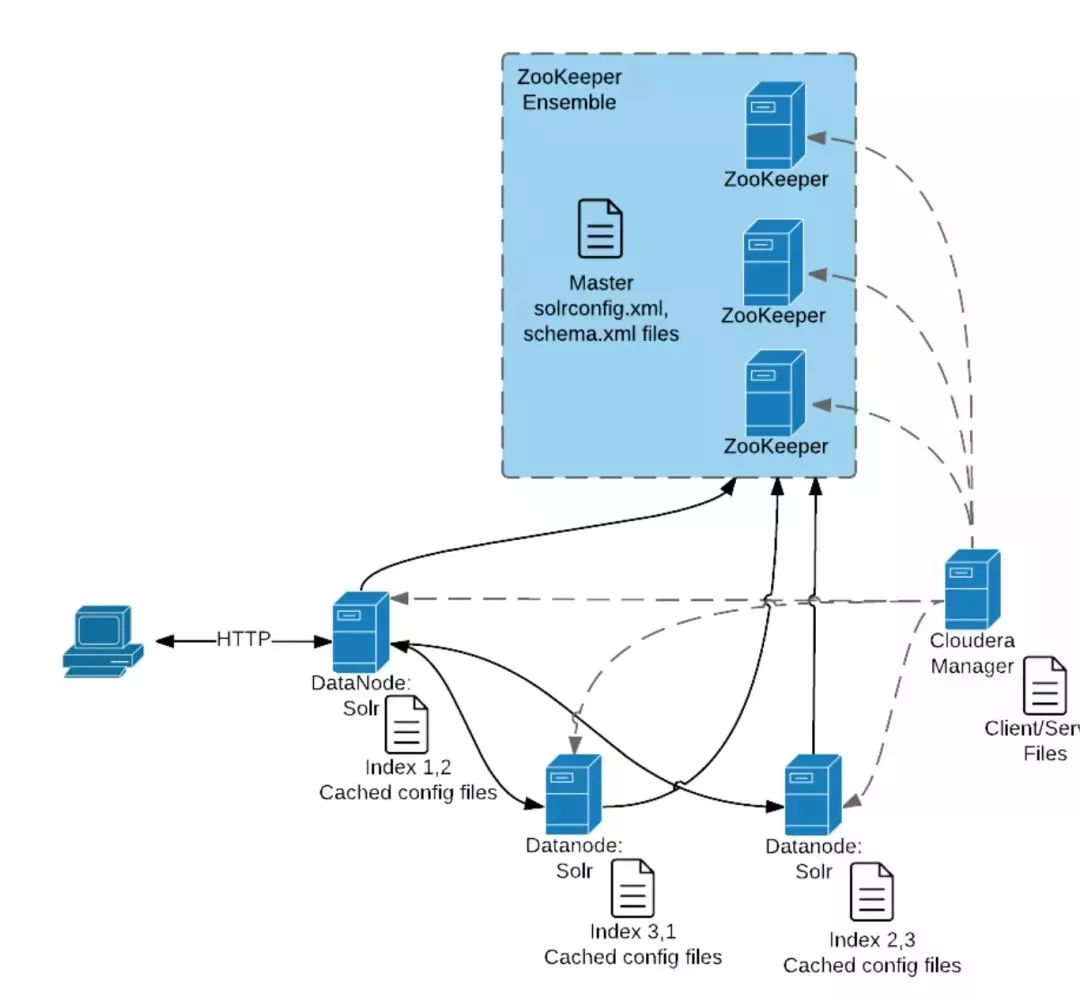
3、CDH 支持构建索引方式:
批量索引:
使用 Spark :CDH自带 spark 批量index工具
使用MapReduce :集成Lily Indexer、自带MR index等工具
近实时索引(增量场景):
使用 Flume 近实时(NRT)索引
集成Lily NRT Indexer
基于Solr REST API自定义索引场景
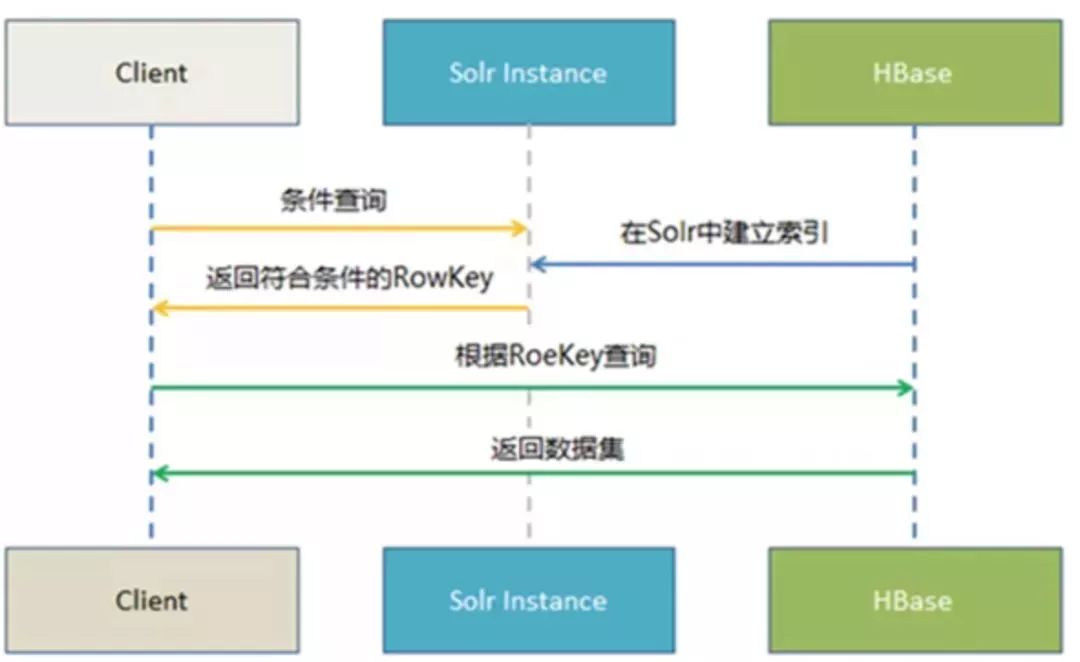
4、CDH Solr 索引查询流程示意图:
04 DataStory二级索引方案介绍
其实对于在外部自定义构建二级索引的方式, 有自己的大数据团队的公司一般都会针对自己的业务场景进行优化,自行构建ES/Solr的搜索集群。 例如数说故事企业内部的百亿级数据全量库,就是基于ES构建海量索引和检索能力的案例。 主要优化点包括:
对企业的索引集群面向的业务场景和模式定制,对通用数据模型进行抽象和平台化复用
需要针对多业务、多项目场景进行ES集群资源的合理划分和运维管理
查询需要针对多索引集群、跨集群查询进行优化
共用集群场景需要做好防护、监控、限流
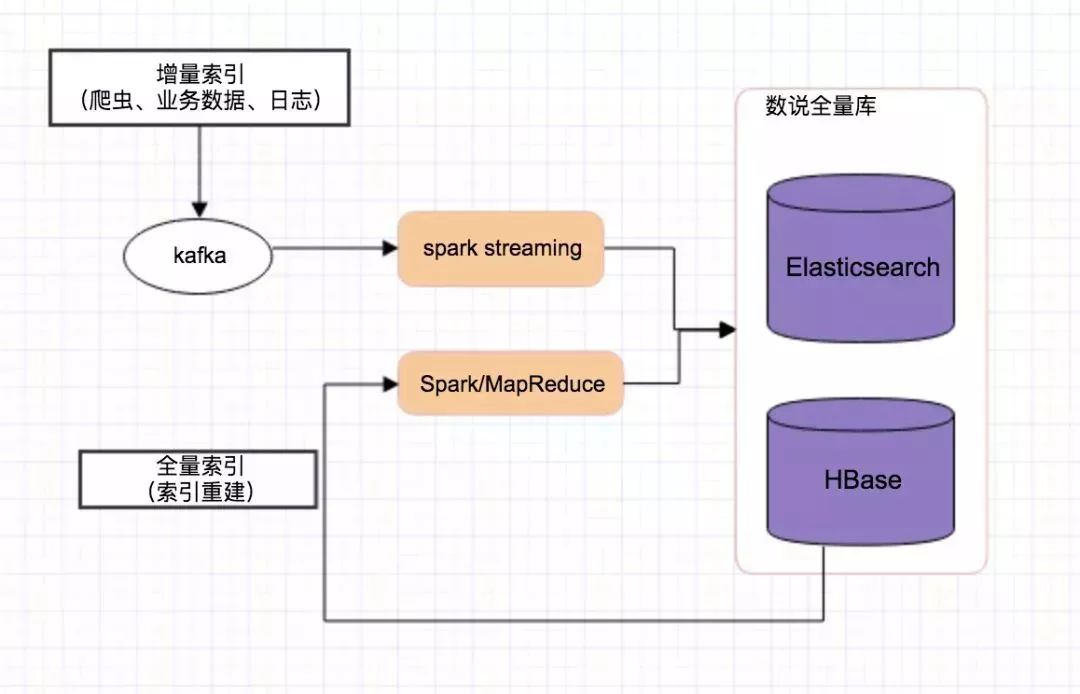
下面显示了数说基于ES做二级索引的两种构建流程,包含:
增量索引: 日常持续接入的数据源,进行增量的索引更新
全量索引: 配套基于Spark/MR的批量索引创建/更新程序, 用于初次或重建已有HBase库表的索引
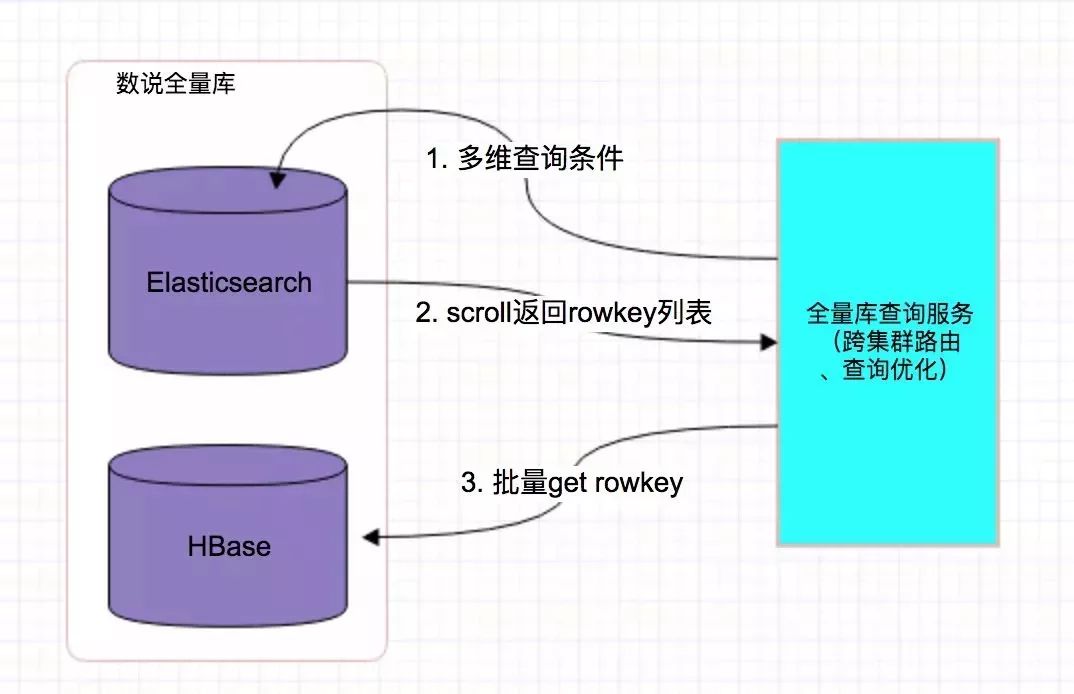
数据查询流程:
Datastory在做全量库的过程中,还是有更多遇到的问题要解决,诸如数据一致性、大量小索引、多版本ES集群共存等, 会在后续进行更细致的介绍和分享。
参考资料:
HBase coprocessor:
https://blogs.apache.org/hbase/entry/coprocessor_introduction
Cloudera Search:
https://www.cloudera.com/documentation/enterprise/5-14-x/topics/search.html
Apache Phoenix Secondary indexing:
https://phoenix.apache.org/secondary_indexing.html
NGDATA Lily HBase Indexer:
https://github.com/NGDATA/hbase-indexer/wiki
https://www.ngdata.com/the-hbase-side-effect-processor-and-hbase-replication-monitoring/
深入理解HBase Indexer:
https://blog.csdn.net/d6619309/article/details/51500368
华为hindex:
https://github.com/Huawei-Hadoop/hindex

了解市场趋势,做规划不烧脑
“行业数据报告”送给大家
扫描二维码获取

点击标题可查看报告节选:
(原付费报告,优惠价 980元)
........
覆盖手机、美妆、服装、食品、饮料、汽车、娱乐、营销等行业超过16份报告
DataStory(数说故事)是国内领先的大数据服务提供商,长期致力于海量互联网数据的深耕与商业价值的挖掘。从数据采集处理分析到商业化场景应用,DataStory成功构建了以市场和消费者为向导、以“数据—洞察—连接”为核心理念的一站式大数据品牌建设体系,帮助企业实现数据价值与业务深度融合,在营销、研发、生产等各大应用场景更科学地决策,促进最大化效果提升。发展至今,已成功为亨氏、伊利、美的、腾讯、联想、屈臣氏等数百品牌企业提供大数据商业应用解决方案,全方面覆盖快消、零售、地产、出行、医药、3c等二十多个细分行业。
▼点击阅读原文查看往期报告
以上是关于HBase二级索引方案的主要内容,如果未能解决你的问题,请参考以下文章