浅谈HBase的数据分布
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈HBase的数据分布相关的知识,希望对你有一定的参考价值。
数据分布问题简述
分布式产生的根源是“规模”,规模可理解为计算和存储的需求。当单机能力无法承载日益增长的计算存储需求时,就要寻求对系统的扩展方法。通常有两种扩展方式:提升单机能力(scale up),增加机器(scale out,水平扩展)。限于硬件技术,单机能力的提升在一个阶段内是有上限的;而水平扩展在理论上可以是无限的,同时,也更廉价、更容易落地。水平扩展可以通过快速、简单的“加机器”,有效解决业务快速增长的问题,这几乎是现代分布式系统必备的能力。对于爆发式增长的业务,水平扩展似乎是唯一可选择的方案。
对于存储系统而言,原本存储在一台机器上的数据,现在要存放在多台机器上。此时必须解决两个问题:分片,复制。
数据分片(sharding),又称分区(partition),将数据集“合理的”拆分成多个分片,每台机器负责其中若干个分片。以此来突破单机容量的限制,同时也提升了整体的访问能力。另外,分片也降低了单个分片故障的影响范围。
数据复制(replica),也叫“副本”。分片无法解决单机故障丢数据的问题,所以,必然要通过冗余来解决系统高可用的问题。同时,副本机制也是提升系统吞吐、解决热点问题的重要手段。
分片和副本是正交的,这意味着我们可以只使用其中一种或都使用,但通常都是同时使用的。因为分片解决的是规模和扩展性的问题,副本解决可靠、可用性的问题。对于一个生产可用的系统,二者必须同时具备。
从使用者/客户端的角度看,分片和副本可以归结为同一个问题:请求路由,即请求应该发送给哪台机器来处理。
读数据时,能通过某种机制来确保有一个合适的分片/副本来提供服务
写数据时,能通过同样的机制来确保写到一个合适的地方,并确保副本的一致性
无论客户端的请求是直达服务端(如HBase/cassandra),还是通过代理(如公有云上的基于gateway的访问方式),请求路由都是分布式系统必须解决的问题。
无论是分片还是副本,本质上都是数据分布的体现。下面我们来看HBase的数据分布模型。
HBase的数据分布模型
HBase的数据分片按表进行,以行为粒度,基于rowkey范围进行拆分,每个分片称为一个region。一个集群有多张表,每张表划分为多个region,每台服务器服务很多region。所以,HBase的服务器称为RegionServer,简称RS。RS与表是正交的,即一张表的region会分布到多台RS上,一台RS也会调度多张表的region。如下图所示:
“以行为粒度”,意思是行是region划分的最小单位,即一行数据要么属于A region,要么属于Bregion,不会被拆到两个region中去。(对行进行拆分的方式是“垂直分库”,通常只能在业务层面进行,HBase是水平拆分)
HBase的副本机制是通过通过底层的HDFS实现的。所以,HBase的副本与分片是解耦的,是存储计算分离的。这使得region可以在RS之间灵活的移动,而不需要进行数据迁移,这赋予了HBase秒级扩容的能力和极大的灵活性。
对于单个表而言,一个“好”的数据分布,应该是每个region的数据量大小相近,请求量(吞吐)接近,每台机器调度的region数量大致相同。这样,这张表的数据和访问能够均匀的分布在整个集群中,从而得到最好的资源利用率和服务质量,即达到负载均衡。当集群进行扩容、缩容时,我们希望这种“均衡”能够自动保持。如果数据分布未能实现负载均衡,则负载较高的机器很容易称为整个系统的瓶颈,这台机器的响应慢,可能导致客户端的大部分线程都在等待这台机器返回,从而影响整体吞吐。所以,负载均衡是region划分和调度的重要目标。
这里涉及到3层面的负载均衡问题:
数据的逻辑分布:即region划分/分布,是rowkey到region的映射问题
数据的物理分布:即region在RS上的调度问题
访问的分布:即系统吞吐(请求)在各个RS上的分布问题,涉及数据量和访问量之间的关系,访问热点等。
可见,一行数据的分布(找到一行数据所在的RS),存在2个层级的路由:一是rowkey到region的路由,二是region到RS的路由。这一点是HBase能够实现灵活调度、秒级扩容的关键。后面我们会详细讨论。本文仅讨论前面两个问题,第三个问题放在后续的文章中讨论。
基于rowkey范围的region划分
首先,我们来看数据的逻辑分布,即一张表如何划分成多个region。
region划分的粒度是行,region就是这个表中多个连续的行构成的集合。行的唯一标识符是rowkey,所以,可以将region理解为一段连续分布的rowkey的集合。所以,称这种方式为基于rowkey范围的划分。
一个region负责的rowkey范围是一个左闭右开区间,所以,后一个region的start key是前一个region的end key。注意,第一个region是没有start key的,最后一个region是没有end key的。这样,这个表的所有region加在一起就能覆盖任意的rowkey值域。如下图所示:
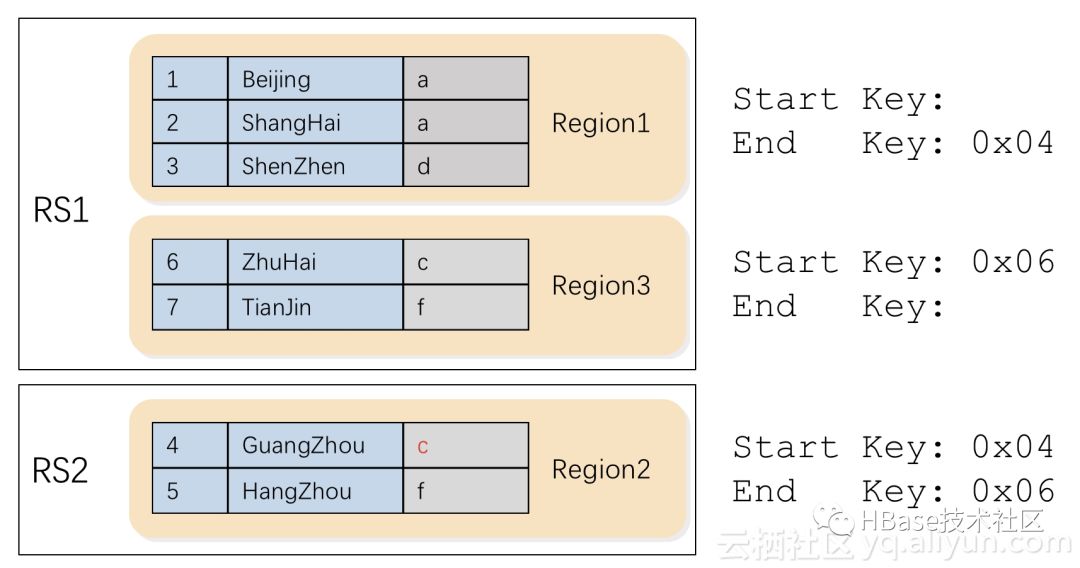
上图中,region1是第一个region,没有startKey,region3是最后一个region,没有endKey。图中的region分布是比较均匀的,即每个region的行数是相当的,那么,这个分布是怎么得到的呢?或者说,region的边界是如何确定的?
一般来说,region的生成有3种方式:
建表时进行预分区:通过对rowkey进行预估,预先划分好region
region分裂:手工分裂,或达到一定条件时自动分裂(如region大小超过一个阈值)
region合并:手工合并
建表时如果未显式指定region分布,HBase就会只创建一个region,这个region自然也只能由一台机器进行调度(后面会讨论一个region由多个RS调度的情况)。那这个region的吞吐上限就是单机的吞吐上限。如果通过合理的预分区将表分成8个region,分布在8台RS上,那整表的吞吐上限就是8台机器的吞吐上限。
所以,为了使表从一开始就具备良好的吞吐和性能,实际生产环境中建表通常都需要进行预分区。但也有一些例外,比如无法预先对rowkey范围进行预估,或者,不容易对rowkey范围进行均匀的拆分,此时,也可以创建只有一个region的表,由系统自己分裂,从而逐渐形成一个“均匀的”region分布。
比如一张存储多个公司的员工信息的表,rowkey组成是orgId + userid,其中orgId是公司的id。由于每个公司的人数是不确定的,同时也可能是差别很大的,所以,很难确定一个region中包含几个orgId是合适的。此时,可以为其创建单region的表,然后导入初始数据,随着数据的导入进行region的自动分裂,通常都能得到比较理想的region分布。如果后续公司人员发生较大的变化,也可以随时进行region的分裂与合并,来获得最佳分布。
字典序与rowkey比较
上一节我们提到region的rowkey范围是一个左闭右开区间,所有落在这个范围的rowkey都属于这个region。为了进行这个判断,必须将其与这个region的起止rowkey进行比较。除了region归属的判断,在region内部,也需要依赖rowkey的比较规则来对rowkey进行排序。
很多人都会认为rowkey的比较非常简单,没有什么讨论的必要。但正是因为简单,它的使用才能灵活多样,使得HBase具备无限的可能性。可以说,rowkey的比较规则是整个HBase数据模型的核心,直接影响了整个请求路由体系的设计、读写链路、rowkey设计、scan的使用等,贯穿整个HBase。对于用户而言,深入理解这个规则及其应用有助于做出良好的表设计,写出精准、高效的scan。
HBase的rowkey是一串二进制数据,在Java中就是一个byte[],是一行数据的唯一标识符。而业务的主键可能是有各种数据类型的,所以,这里要解决2个问题:
将各种实际使用的数据类型与byte[]进行相互转换
保序:byte[]形式的rowkey的排序结果与原始数据的排序结果一致
rowkey的比较就是byte[]的比较,按字典序进行比较(二进制排序),简单说,就是c语言中memcmp函数。通过下面的示例,我们通过排序结果来对这一比较规则以及数据类型转换进行理解。
(1)ascii码的大小比较
1234 -> 0x31 32 33 34
5 -> 0x35
从ascii码表示的数字来看,1234 > 5, 但从字典序来看,1234 < 5
(2)具有相同前缀的ascii码比较
1234 -> 0x31 32 33 34
12340 -> 0x31 32 33 34 00
在C语言中,字符串一般是以0自己结尾的。本例的两个字符串虽然前缀相同,但第二个末尾多了0字节,则第二个“较大”。
(3)正数与负数的比较
int类型的100 -> 0x00 00 00 64
int类型的-100 -> 0xFF FF FF 9C
100 > -100,但其二进制表达中,100 < -100
我们可以将这个比较规则总结如下:
从左到右逐个字节进行比较,以第一个不同字节的比较结果作为两个byte[]的比较结果
字节的比较是按无符号数方式进行的
“不存在”比“存在”小
常见的rowkey编码问题:
有符号数:二进制表示中,有符号数的首bit是1,在字典序规则下,负数比正数大,所以,当rowkey的值域同时包含正数和负数时,需要对符号位进行反转,以确保正数比负数大
倒序:通常用long来描述时间,一般都是倒排的,假设原始值是v,则v的倒序编码是Long#MAX_VALUE - v。
下面通过一个前缀扫描的案例来体会一下这个比较规则的应用。
示例:前缀扫描
HBase的rowkey可以理解为单一主键列。如果业务场景需要多列一起构成联合主键(也叫多列主键,组合主键,复合主键等等),就需要将多列拼接为一列。一般来说,直接将二进制拼接在一起即可。例如:
rowkey组成:userId + ts
为了简单,假设userid和ts都是定长的,且只有1个字节。例如:
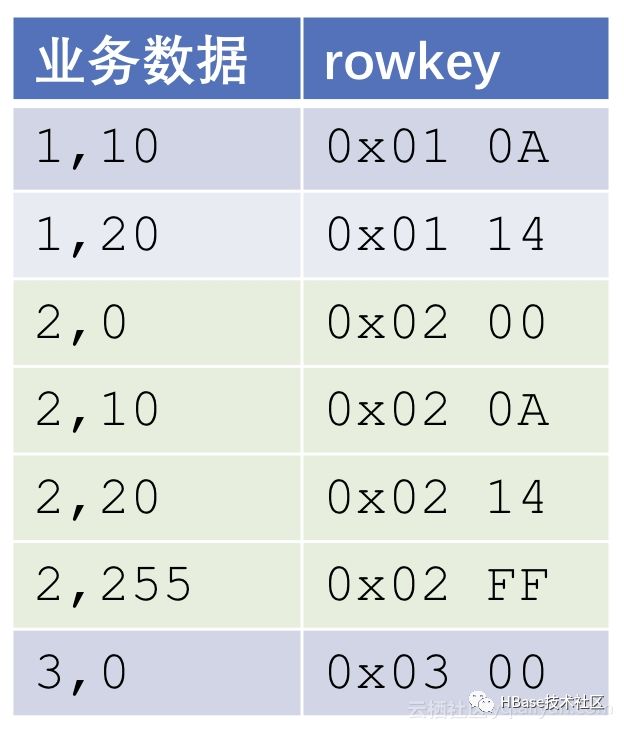
现在,我们要做的事情是,查找某个userid = 2的所有数据。这是一个典型的前缀扫描场景,我们需要构造一个Scan操作来完成:设置正确扫描范围[startRow, stopRow),与region的边界一样,scan的范围也是一个左闭右开区间。
一个直接的思路是找到最小和最大的ts,与userid = 2拼接,作为查询范围,即[0x02 00, 0x02 FF)。由于scan是左臂右开区间,则0x02 FF不会被作为结果返回。所以,这个方案不可行。
正确的scan范围必须满足:
startRow:必须必任何userId = 2的rowkey都小,且比任何userId = 1的rowkey都大
stopRow:必须必任何userId = 2的rowkey都大,且比任何userId = 3的rowkey都小
那如何利用rowkey的排序规则来“找到”这样一个扫描范围呢?
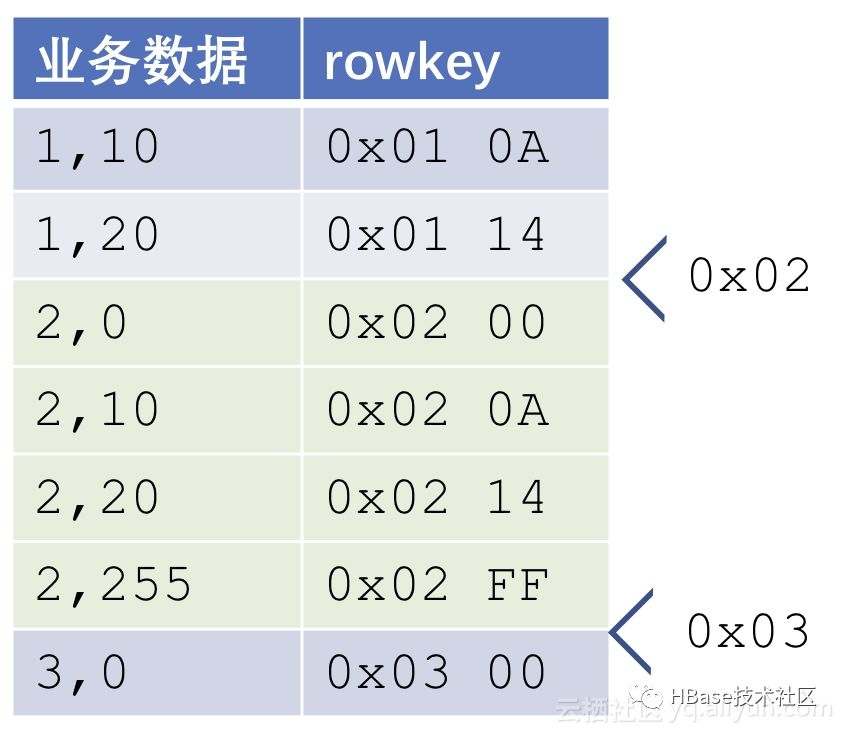
正确的扫描范围是[0x02, 0x03)。
0x02比任何userid = 2的行都小。因为ts这一列是缺失的。同理,0x03比任何userid = 2的行都大,又比任何userId = 3的行都小。可见,要实现前缀扫描,只根据前缀的值就可以得到所需的startRow和stopRow,而不需要知道后面的列及其含义。
请读者仔细体会这个例子,然后思考下面几个场景该如何构造startRow和stopRow(答案见文末)。
where userid = 2 and ts >= 5 and ts < 20
where userid = 2 and ts > 5 and ts < 20
where userid = 2 and ts > 5 and ts <= 20
where userid > 2 and userid < 4
还有下面这些组合场景:
where userid in (3, 5, 7, 9)
where userid = 2 and ts in (10, 20, 30)
现在,已经可以感受到使用scan的难点和痛点所在了。在上面的例子中,只有两个定长的列,但在实际业务中,列可能是变长的,有各种各样的数据类型,各种丰富的查询模式。此时,构造一个正确、高效的scan是有难度的。那为什么会有这些问题呢?有没有系统性的解决方案呢?
从形式是看,这是一个“如何将业务查询逻辑转换为HBase的查询逻辑”的问题,本质上是关系表模型到KV模型的映射问题。HBase仅提供了KV层的API,使得用户不得不自己实现这两个模型之间的转换。所以,才会有上面这么多的难点问题。不仅是HBase,所有的KV存储系统在面临复杂的业务模型时,都面临相同的困境。
这个问题的解法是SQL on NoSQL,业界这类方案有很多(如Hive,presto等),HBase之上的方案就是Phoenix。此类方案通过引入SQL来解决NoSQL的易用性问题。对于传统的关系型数据库,虽然有强大的SQL和事务支持,但扩展性和性能受限,为了解决性能问题,mysql提供了基于Memcached的KV访问方式;为了解决扩展性问题,有了各种NewSQL的产品,如Spanner/F1,TiDB,CockroachDB等。NoSQL在做SQL,支持SQL的在做KV,我们可以想象一下未来的存储、数据库系统会是什么样子。这个话题很大,不在本文的讨论范围内,这里就不展开了。
region的元数据管理与路由
前面我们讨论了将一张表的行通过合理的region划分,可以得到数据量大致接近的region分布。通过合理的运维手段(region的分裂与合并),我们可以通保证在系统持续运行期间的region分布均匀。此时,数据在逻辑上的拆分已经可以实现均匀。本节中我们看一下region如何分布在RS上,以及客户端如何定位region。
因为region的rowkey范围本身的不确定性或者主观性(人为拆分),无法通过一个数学公式来计算rowkey属于哪个region(对比一致性hash的分片方式)。因此,基于范围进行的分片方式,需要一个元数据表来记录一个表被划分为哪些region,每个region的起止rowkey是什么。这个元数据表就是meta表,在HBase1.x版本中表名是“hbase:meta”(在094或更老的版本中,是-ROOT-和.META.两个元数据表)。
我们从Put操作来简要的了解region的定位过程。
ZK上找meta表所在的RS(缓存)
到meta表上找rowkey所在的region及这个region所在的RS(缓存)
发Put请求给这个RS,RS根据region名字来执行写操作
如果RS发现这个region不在自己这里,抛异常,客户端重新路由
无论读还是写,其定位region的逻辑都是如此。为了降低客户端对meta表的访问,客户端会缓存region location信息,当且仅当缓存不正确时,才需要访问meta表来获取最新的信息。所以,HBase的请求路由是一种基于路由表的解决方案。相对应的,基于一致性Hash的分片方式,则是通过计算来得到分布信息的。
这种基于路由表的方式
优点:region的归属RS可以任意更换,或者说,region在RS上的调度是灵活的、可人工干预的。
缺点:meta表是一个单点,其有限的吞吐限制了集群的规模和客户端数量
region的灵活调度,结合存储计算分离的架构,赋予了HBase极其强大的能力。
秒级扩容:新加入的RS只需要移动region即可立即投产,不依赖数据的迁移(后续慢慢迁)
人工隔离:对于有问题的region(如热点,有异常请求),可以手工移动到一台单独的RS上,进行故障域的快速隔离。
这两点,是众多基于一致性hash的分片方案无法做到的。当然,为了获得这种灵活性,HBase所付出的代价就是复杂的meta表管理机制。其中比较关键的问题就是meta表的单点问题。例如:大量的客户端都会请求meta表来获取region location,meta表的负载较高,会限制获取location的整体吞吐,从而限制集群的规模和客户端规模。
对于一个拥有数百台机器,数十万region的集群来说,这套机制可以很好的工作。但当集群规模进一步扩展,触及到meta表的访问上限时,就会因meta表的访问阻塞而影响服务。当然,绝大多数的业务场景都是无法触达这个临界规模的。
meta表的问题可以有很多种解决思路,最简单的方式就是副本。例如TiDB的PD服务,获取location的请求可以发送给任何一台PD服务器。
region的调度
下面我们讨论region调度问题:
region在RS之间的负载均衡
同一个region在多个RS上调度
对于第一个问题,HBase的默认均衡策略是:以表为单位,每个RS上调度尽可能相同数量的region。
这个策略假设各个region的数据量分布相对均匀,每个region的请求相对均匀。此时,该策略非常有效。这也是目前使用最多的一种。同时,HBase也提供了基于负载的调度(StochasticLoadBalancer),会综合考虑多种因素来进行调度决策,不过,暂时缺少生产环境使用的案例和数据。
对于第二个问题,region同一时间只在一台RS上调度,使得HBase在请求成功的情况下提供了强一致的语义,即写成功的数据可以立即被读到。其代价是region的单点调度,即region所在的服务器因为各种原因产生抖动,都会影响这个region的服务质量。我们可将影响region服务的问题分为两类:
不可预期的:宕机恢复,GC,网络问题,磁盘抖动,硬件问题等等
可预期的(或人为的):扩容/缩容导致的region移动,region split/merge等。
这些事件发生时,会对这个region的服务或多或少产生一些影响。尤其在宕机场景,从ZK发现节点宕机到region的re-assign,split log,log replay,一些列步骤执行完,一般都需要1分钟以上的时间。对于宕机节点上的region,意味着这段时间这些region都无法服务。
解决方案依然是副本方案,让region在多个RS上调度,客户端选择其中一个进行访问,这个特性叫“region replia”。引入副本必然带来额外的成本和一致性问题。目前这个特性的实现并未降低MTTR时间,内存水位的控制、脏读,使得这个特性仍未在生产中大规模使用。
总结
HBase的数据分布与region调度问题,放大到整个分布式系统中,是任务的拆分与调度问题,这个话题的内涵大到足以写几本书。本文只是从HBase这个切面来对数据分片这个话题进行一些讨论,希望能够加深读者对HBase rowkey和region概念的思考和理解,无论是数据库的用户还是开发,都能够从这个讨论中有所收获。
附录
正文中一些查询场景所对应的scan range:
where userid = 2 and ts >= 5 and ts < 20: [0x02 05, 0x02 14)
where userid = 2 and ts > 5 and ts < 20: [0x02 06, 0x02 14)
where userid = 2 and ts > 5 and ts <= 20: [0x02 06, 0x02 15)
where userid > 2 and userid < 5: [0x03, 0x05)

长按下面的二维码加入HBase技术社区微信群
以上是关于浅谈HBase的数据分布的主要内容,如果未能解决你的问题,请参考以下文章