HBase迁移 | HBase金融大数据乾坤大挪移
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase迁移 | HBase金融大数据乾坤大挪移相关的知识,希望对你有一定的参考价值。
随着最后一台设备的退还,标志着整个10P+的HBase数据迁移完成。目前新集群已经在新机房平稳运行2个月,从监控图明显反应出新集群查询耗时更低,更稳定。从消费的曲线来看,也更平滑,基本不会有大量毛刺的情况出现。一颗心也落了地。终于可以腾出时间,来好好梳理一下这次数据大迁移的过程。
第一次主导HBase大数据的数据迁移,由于缺乏类似的实战经验,迁移期间战战兢兢、如履薄冰。幸亏有老司机的协助,才得以顺利完成。总结一下整个项目的过程以及遇到的问题,吸取经验和教训,以便后面能做得更好。同时也为其他运维HBase的技术朋友提供一个成功的案例参考。
项目背景
某日,收到资源测的通知:机房即将裁撤,需要尽快将机房所有的业务都迁移到新机房,这里面涉及到自己刚接手的HBase集群,集群存储有近10P的金融数据,这个集群承担着每秒上百万次的数据写入,存储的都是重要的金融数据。很多关键流程都依赖HBase服务,比如退款、历史订单查询、证书查询、客服系统等,这些重要业务都是不能出现中断的。
概括一下需求:2个多月的时间里,需要将近10P的金融数据平滑迁移到新机房,并且中间不能出现数据丢失和业务中断。
项目挑战
这个项目面临的蛮大的挑战,主要的挑战简单概括日下:
1.数据量巨大,涉及10P+的数据
2.不能停业务,只能平滑迁移
3.金融数据数据不能丢,不能错
4.缺乏大规模数据的迁移经验,只能摸着石头过河
瞬间感觉压力巨大,因为之前一直做mysql相关的工作,这次要处理的是分布式数据库HBase的数据迁移。从最近的学习来看,HBase(底层存储用的HDFS)的运维本身要比MySQL的运维要难得多,加上这个项目面临的几个大挑战,不免临事而惧,只能沉下心来好好规划,详细地去测试验证。从方案选型、到方案的测试、验证和实施,每个步骤都需要做到心中有数。先来介绍方案的选型。
迁移方案
考察了所有的HBase的数据迁移方案,以及各个方案适用场景,这里可以参考如下两个KM文章针对不同数据迁移方式的讨论:
链接1:
https://www.jianshu.com/p/8d091591d872(玩转HBase快照)
链接2:
https://www.cnblogs.com/ballwql/p/hbase_data_transfer.html(HBase数据迁移方案介绍)
也参考了其他公司在数据迁移方案上经验,比如Snapshot和CopyTable的讨论可以参见:
http://hbase-help.com/?/question/35
最终选择了Snapshot+Bulkload+集群双写的方案
如下图所示的迁移方案:
大致方案为:开启双写后,使用SnapShot技术对集群A的表做好快照,然后通过Export snapshot将快照传输到集群B,并使用BuldLoad在B集群进行导入,从而使得集群数据一致。
具体步骤如下:
1.在集群A和集群B开启双写
备注:需要特别注意B集群delete标记参数(hbase.hstore.time.to.purge.deletes)的配置,因为从在A集群做快照到Export snapshot传输到B集群在到使用BuldLoad在B集群完成导入是需要时间的,尤其是如果一个表很大,需要的时间更久,甚至可能超过好几个小时。因此必须保证B集群的hbase.hstore.time.to.purge.deletes参数大于最大的表迁移时间,否则可能会导致删除的数据又“奇迹”般地出现在B集群中。
2.迁移表结构
3.针对表创建Snapshot
备注:Snapshot相关的知识可以参考:
https://www.jianshu.com/p/8d091591d872(玩转HBase快照)
4.通过Export Snapshot将快照传输到B集群
5.使用BulkLoad将数据导入到B集群
6.对迁移的表进行集群间对账,确认数据是否一致
7.灰度切换表的查询到B集群
统筹规划
在数据迁移之前,我们考虑了之前集群存在的问题,根据这些问题我们对新集群做了非常多的优化,这是系统思维在运维过程中比较好的运用了。这些问题主要体现在:
1.版本比较旧(HBase 0.98 HDFS 2.2),对于新功能不支持,比如异构存储;性能也不如新版本号;
2.group比较多,导致机器相对比较分散
3.表的region数量设计不太合理,部分表数量比较小,region数量很多
4.有的表没有开启布隆过滤器,性能比较差
5.部分参数没有优化(由于重启整个集群成本比较高,部分参数一直没有优化)
6.全链路监控未完全打通,有的问题无法快速发现
针对这部分问题,在迁移集群就顺便做了优化,从目前新集群的运行情况来看,优化效果还是非常好的。
具体优化分类如下:
1.版本升级优化
HBase 0.98 ---> 1.26
HDFS 2.2 ---> 2.7
备注:兼容性评估和测试未发现异常
2.硬件层面优化
a.充分利用TSC10自带的一个SSD盘,HDFS的异构存储将WAL日志写入到SSD盘,充分利用资源的同时提升性能;
备注:关于异构存储实战相关的知识,可以访问:
https://www.jianshu.com/p/167d7677a050(HDFS异构存储实战)
b.将regionserver的配置从24G调整到48G,因为TSC10的内存为64G
3.运营层面优化
a.统筹各个类型表的历史数据情况,重新调整表的region数,减少必须要的元数据空间损耗
b.减少集群group数量,从原来的7个变成5个,减少机器分散;
备注:关于group的相关知识可以访问:
https://www.jianshu.com/p/04d56a2c8b5c(HBase隔离方案实战)
c.对集群进行本地化优化,历史数据全量进行major_compact
4.参数优化
建表参数优化:
a.hbase.hstore.compaction.min 调整为3,提升自动合并效率
b.BLOOMFILTER => 'ROW' ,提升查询性能
HBase参数优化
a.hbase.ipc.server.callqueue.read.ratio 指定读的所占比率,保证读操作顺利进行
b.hbase.wal.storage.policy 确定hbase写WAL的策略,提升写WAL的性能,充分利用资源
HDFS参数优化
这里主要是减少机器故障后给整个集群带来的性能冲击。
a.dfs.namenode.replication.interval 减少副本计算频率
b.dfs.namenode.replication.work.multiplier.per.iteration 减少每次迁移的block数
5.监控层面优化
a.增加了全链路的监控上报和告警(DBSYNC、TDSORT),快速发现机器负载异常、表不存在、region未上线、RegionServer超时等问题;
b.增加了采集容灾调整,对发现只配置了单台采集机器但实例本身有多台备机的问题进行配置改造;
c.增加了采集延迟场景的监控,用于快速发现切换到跨机房导致的采集延迟问题;
遇到问题
迁移过程中,遇到了很多的问题,分别总感觉如下:
1.dfs.datanode.du.reserved参数引起的WAL无法写入SSD的问题
原因是因为我们配置了dfs.datanode.du.reserved为200G,意思是HDFS数据盘保留200G的空间,而我们的SSD盘(规划用来存储WAL的盘也只有200G,加上系统保留5%的空间,总计可用空间还不足200G),因此在写SSD之前空间少于200G,因此WAL也写入到了SATA盘,导致SSD使用率为0。解决办法具体的场景查阅文章:
https://www.jianshu.com/p/508449d8f12c
2.使用Mapreduce传输快照文件的各类异常
在使用Mapreduce将快照文件Export到新集群的时候,出现过各种异常,包括搭建以及调试的时候的异常,问题都总结在了下面的两篇文章中,有兴趣的可以自行了解:
MR相关问题排查思路:
https://www.jianshu.com/p/ebd469da07d2
HBase混布MapReduce集群学习记录:
https://www.cnblogs.com/ballwql/p/9278389.html
3.配置WAL写SSD后,很快发现SSD被用光
在之前的规划统计中,WAL日志应该在5T以内,折算到每台机器为55G左右。如果都写SSD,我们为WAL分配了120G的空间,因此正常情况下每台机器的WAL使用率为55%~60%之间,为什么会使用率为99%呢?经过追踪namenode的日志,发现有大量的非WAL数据也写入到了SSD中,因此导致SSD很快耗尽。根本原因是版本bug导致的获取盘的时候把SSD也当做普通的存储处理,版本修复后,正常。这里涉及到需要将已经写入到SSD的数据迁移到SATA中,在HDFS异构存储实战中已有详细的描述,有兴趣的可以阅读这篇文章,《HDFS异构存储实战》:
https://www.jianshu.com/p/167d7677a050
4.BulkLoad出现文件不存在的异常
在检查BulkLoad结果的时候,有的时候回出现文件不存在的exceptions,访问频繁的表尤其容易出现,异常日志如下:
org.apache.hadoop.io.MultipleIOException: 6 exceptions [java.io.FileNotFoundException: File does not exist: /hbase/archive/data/default/t_tcpay_list_201611/c520120e9b6cd2f49851931ff68ad97a/I/ccb7414cc0054c25aeb8da63c4bf2bda
在去老集群也找不到对应的region,后来跟踪文件并模拟线上个环境重现确认是compact操作导致Hfile移动到了archive目录下,而程序中是逐个读取archive目录下对应的Hfile,因为BulkLoad导入大表需要比较长的时间,大概率会遇到compact的情景,导致读取文件列表的时候文件存在,到真正导入的时候,该文件已经被清理掉了。其实这个并不影响数据准确性,调整异常捕获的关键字并通过对账来解决。
5.数据冗余问题
在迁移完数据进行核对和业务灰度的时候,发现有部分记录出现冗余,具体表现为记录有两台,一条是新数据一条是老数据,如下图:

初步怀疑是迁移过程中delete标记丢失导致,目前在测试环境无法重现该问题,已记录tapd持续跟进中。已经通过程序修复冗余数据。
迁移过程中遇到太多的问题,这里就不一一列举出来,有兴趣的同学可以访问Fit HBase专门的K吧,我们遇到的问题都会整理到这个K吧中Fit HBase专门的K吧,
http://km.oa.com/group/34126?kmref=km_header,希望能和更多的同行交流HBase中遇到的问题和使用心得。
运营质量
这里从接入业务的查询HBase的成功率和平均延时来确定HBase运营质量的改善情况:
1.HBase订单可用性和延迟情况
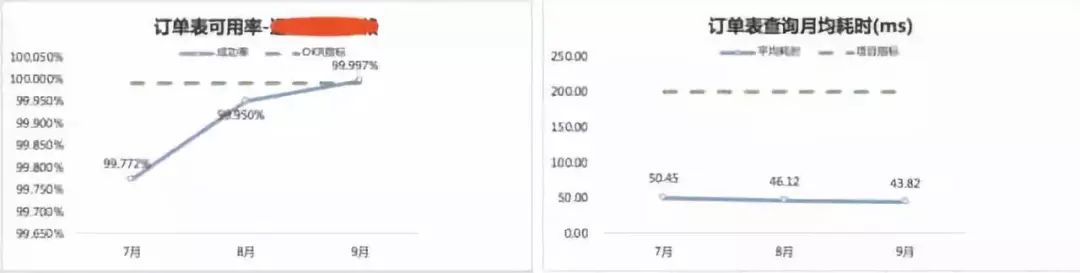
2.HBase交易单可用性和延迟情况
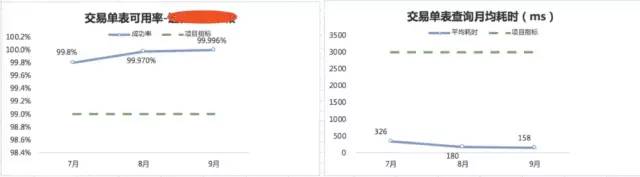
感谢
回顾整个数据迁移的过程,从集群搭建、参数调优、方案制定、方案测试、问题解决、业务切换,再到最后的设备退还,整个过程痛苦而漫长。这几个月来每天都要面对大量没有遇到过的问题和场景,每天思考最多的就是如何快速的学习,快速地解决问题。一路走来,跌跌撞撞,但收获巨大。从对Hadoop和HBase懵懵懂懂,到对HBase集群运维逐步得心应手,心中已了无恐惧,因为我的背后站着一个非常棒的团队,有idavidjiang(姜老师)和steven老大强力支持,还有TEG强大的老司机们护航,还有很多同事的默默支持,。总之,特别的感谢大家,有了你们的支持,才能实现HBase集群的无缝迁移。

技术社群
【HBase生态+Spark社区大群】
群福利:群内每周进行群直播技术分享及问答
加入方式1:
https://dwz.cn/Fvqv066s?spm=a2c4e.11153940.blogcont688191.19.1fcd1351nOOPvI
加入方式2:钉钉扫码加入
免费试用
以上是关于HBase迁移 | HBase金融大数据乾坤大挪移的主要内容,如果未能解决你的问题,请参考以下文章