HBase感悟 | 这两年跟HBase相爱相杀的一些感悟
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase感悟 | 这两年跟HBase相爱相杀的一些感悟相关的知识,希望对你有一定的参考价值。
接下来因为工作调整的原因,可能以后都不会怎么接触HBase了。但是自从2017年4月走进极光科技以来,就开始接触HBase,这两年也主要负责跟它相关的业务设计、开发与维护。在资源不算多的情况下,保证公司算是比较大的数据稳定运行,也算是有点经验了吧。把自己对HBase的一些看法写下来,希望能够提供给以后从事与之相关工作的朋友参考。
感悟一.非结构化的列式数据库or行式数据库or最结构化的行式数据库
相信到目前为止,仍然有很多人认为HBase是非结构化的列式数据库。那就先看看什么是列式、什么又是行式吧。首先几乎任何一条数据都会不只有一个字段(就比如描述一个人,有年龄、身高、体重、性别等等),而且几乎每一条数据都会有一个唯一标识符(同样描述一个人,绝大多数情况下可以用身份证最为唯一标识符,虽然由于历史原因身份证跟人不是一一对应的关系,这里暂时不考虑那些特殊情况吧)。
行式数据库的存储方式,往往是对唯一标识符做索引,然后将这条数据相关的字段与唯一标识符一起存储,就比如下面的图:
行式存储
同样的数据,换成列式存储就是下面的样子了,字段不在以每条记录的唯一标识符组织在一起,而是将同一个字段的数据放在一起
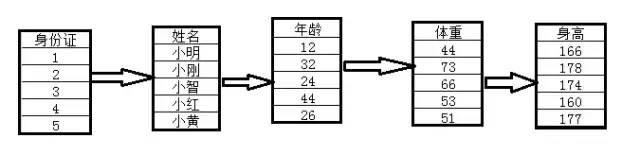
列式存储
行式跟列式各有优劣,就比如需求就是需要根据身份证查出这个人所有的信息,这种需求只查询一条记录,那么行式数据库可能更适用;如果需求是分析全国所有人的平均年龄,那么列式存储更合适,只需要读取年龄字段就够了。区别行式跟列式,可以看看字段是否是根据唯一标识符组合起来的,唯一标识符一样的数据,物理位置在一起,这样的存储叫做行式;根据字段组织在一起的叫做列式。
上述数据在HBase中是按照如下形式组织起来的(有一定简化)。不难看出唯一标识符(这里是身份证)一样的数据,物理位置还是相邻的,应该将HBase划分为行式存储才更合理。加上身份证号码是1的小明可能考过6级、而身份证为5的小黄也可能没考过,所以在原来的基础上在小明身高后面又加入了一个字段表示小明考过六级并且拿了515分,但是小黄没有这种记录;所以现在有很多人开始将HBase称为非结构化的行式数据库。
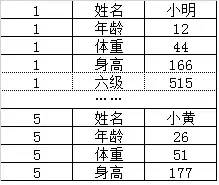
HBase存储格式
但是如果我们现在假设有一张表有三个字段,分别叫做身份证、属性名、属性值,其中“身份证”+“属性名”可以视为唯一标识符,属性值可以是姓名、年龄、体重、身高、六级中的任意一个,那么上面这张表是不是可以看成一张只有三个列的结构化的关系型数据库的表呢?HBase里面的基本数据就可以这么来看,不过字段复杂一些,一个HFlie(不考虑tags)的数据可以视为Rowkey/Family/Column/Timestamp/Type
/Value/MVCC这七个字段组成的关系型数据库的表(虽然只对前三列做了索引;而且笔者更喜欢把MVCC放在value前面看,理由这里不详细解释),唯一标识符由除Value之外的六个字段组成,HBase把一条这七个字段组合起来的数据称为Cell。所以在笔者眼里HBase是最结构化的行式数据库,我们通常说的Rowkey在这种模式下不是唯一标识符(即主键)而是一种分区键。
感悟二.关于LSM树
在这里不想过多的介绍LSM树,以前的技术文章里面有写过(可以看看https://www.jianshu.com/p/23dfd99227b0),到是想说说自己对跟LSM树相关的Split跟Compact的理解。
先说说Compact,正如上面所说,一个HFile可以看成是一个最结构化的关系表,但是LSM树这种系统决定了,几乎不可能说一个Region下只有一个HFile。就当我们可以保证HFile的索引部分跟布隆过滤器部分都放在内存中,一个根据Rowkey的最简单查询也是跟文件个数成正比的,因此需要通过类似归并排序的方式将HFile进行Compact。虽然有人说Compact是为了删除delete mark之类的数据,但是个人感觉、默认已经存储3个副本,通常delete的情况也不多,这点delete mark以及可以连带删除的数据真的不算什么,而且也存在完全不会delete的系统,比如一个物流订单系统。所以Compact更重要的原因,起码在笔者看来,是为了减少OLTP场景下的随机磁盘IO。HBase的Compact模块已经做得很不错了,但是个人觉得以后的版本可以提供一种API,让HBase管理员可以自己手动指定想要对哪些文件进行合并。
再说说Split,大家都觉得Split可以提高性能,但是有多少想过为什么呢?起码在笔者看来,Split对于性能最大的好处在于它可以减少单个Region在Compact需要处理的数据,Compact过程理论上只用原来的一半。虽然整体的时间不会变短,但是起码保证了部分数据可以在更短的时间内完成合并,提供更好的读取性能。
感悟三.关于QPS与TPS
先说QPS吧,在其他条件不是太大的瓶颈下(例如GC),依照个人经验,HBase的QPS与磁盘能够提供的IOPS有很大关系(能够把数据完全放入内存的情况就不考虑了)。在大部分情况下,布隆过滤器以及索引段完全放入内存不是太大的问题,主要就是对数据段在磁盘上的读取操作影响了整体性能。笔者通常会将Minor Compact调整的非常容易触发,同时轮询所有Region做Major Compact,通常保证一个Region(通常也是有一个Family)下不会超过4个文件,单次查询需要的磁盘io控制在2~3次。比如一个系统可以有10000磁盘IOPS用于查询,那么最好将QPS控制在10000/3=3333到10000/2=5000之内。当然如果说情况已经糟糕到内存小到无法保留布隆过滤器以及索引,那么单次查询需要的IO大概是(3~4)*文件数(布隆过滤器的中间层、布隆过滤器数据块、索引中间层、数据块可能都要从磁盘读取,而且每个文件都是这样)。
再说说TPS,这里TPS以Cell为单位。写入时,TPS跟Cell大小、HFile压缩率(这里HLog通常默认不压缩)、副本数以及网络磁盘能够承受的最大IO相关。假设Cell大小为x,TPS为y,HFile压缩率为z、副本数为n,并且调整一些必要参数完全禁止Compact,那么网络以及磁盘需要承受的IO大致如下:

IO消耗
在GC与CPU压力不算太大的情况下,主要就看磁盘跟网络那边先到性能极限。起码就笔者在测试环境中设置x=0.1k、y=360k、z=1、n=3的测试结果来看,磁盘跟网络IO消耗差不多都对的上,但是CPU已经使用超过50%了,所以也就没接着压。
感悟四.关于一致性问题
每个管HBase的人应该都被HBase一致性问题困扰过,我也不例外。但是就个人总结来看,之所以会有一致性问题,无非是zk、hbase:meta、hdfs目录、服务器内存四者之间元数据对不上。而导致对不上往往是因为gc或者网络原因导致只操作了一部分元数据,其他的部分没有操作,类似于分布式事务原子性没有得到保证。
个人解决这个问题主要是朝着两个思路出发,一是缓解GC,二是减少元数据操作(例如Split、Merge、Create、Drop)。对于GC,自己也不敢说自己有多精通(在这里真的是不得不说那些看了几小时博客,就觉得自己精通GC的各位是不是有点太轻视这个问题了),笔者觉得缓解GC最靠谱的方法无非这几条
不用java
少用内存
少创建对象
及时释放大的对象(close方法、或者引用设置为Null)
第三第四点,在这不做展开讨论,第一点短期内也不可能指望HBase改过来,主要说说第二点。起码就笔者在数据量不小的测试环境结果来看,将测试表的BlockCache参数设置为false(这样可以尽量少用内存缓存不怎么可能经常访问的数据块、而是用来存储比较少的索引与布隆过滤器)与使用堆外内存处理请求的情况相比,前者GC时间更少,而且访问延迟也不高。
再来说说元数据操作,笔者在自己的公司出于各种原因,控制Move(balancer)、Split、建表与删表,Merge操作也几乎不会存在。减少元数据操作次数,可以直接减少一致性出现的可能性。
如果说各位的HBase系统真的不幸出现了一致性问题而且hbck也解决不了了,笔者可以提供一种虽然不怎么好,但是比较通用的方法解决(平时做好分区起始键备份)。
1)关闭HBase服务端与前台读写服务;
2)将HFile、WAL移动到别的目录下;
3)清空hbase:meta,HBase目录(通常是/hbase),以及zk里面的信息;
4)重启HBase(这个时候差不多就是搭建了一个新的集群了);
5)根据平时导出的分区起始键生成新的表;
6)用bulkload功能,将步骤2里面的HFile bulkload到新的系统;
7)结合MR的API将WAL的数据转化为HFile并导入;
8)开启前台读写服务。
总结
其实HBase整体代码写的非常不错,目录结构和文件结构也比较清晰,推荐大家多看看源码,一步一步慢慢来吧。也希望HBase发展的更好。
转载自链接:https://www.jianshu.com/p/a8319511cd02

技术社群
【HBase生态+Spark社区大群】
群福利:群内每周进行群直播技术分享及问答
加入方式1:
https://dwz.cn/Fvqv066s?spm=a2c4e.11153940.blogcont688191.19.1fcd1351nOOPvI
加入方式2:钉钉扫码加入
免费试用
以上是关于HBase感悟 | 这两年跟HBase相爱相杀的一些感悟的主要内容,如果未能解决你的问题,请参考以下文章