HBase分享 | 基于HBase和Spark构建企业级数据处理平台
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase分享 | 基于HBase和Spark构建企业级数据处理平台相关的知识,希望对你有一定的参考价值。
摘要:在中国HBase技术社区第十届Meetup杭州站上,阿里云数据库技术专家李伟为大家分享了如何基于当下流行的HBase和Spark体系构建企业级数据处理平台,并且针对于一些具体落地场景进行了介绍。
演讲嘉宾简介:李伟(花名:沐远),阿里云数据库技术专家。专注于大数据分布式计算和数据库领域,具有6年分布式开发经验,先后研发Spark及自主研发内存计算,目前为广大公有云用户提供专业的云HBase数据库及计算服务。
以下内容根据演讲视频以及PPT整理而成。
本文分享主要围绕以下四个方面:
当前面临的挑战
平台架构及案例
原理及最佳实践
阿里云HBase X-Pack服务
一.当前面临的挑战
众多场景需求
目前,HBase广泛地应用于各个公司的数据处理平台之中。HBase能够解决的问题主要可分为5类,即金融风控、个性化推荐、社交Feeds、时序时空以及大数据等。在以上的各类问题中也都存在诸多场景,比如在金融风控中就有反欺诈系统,而对于反欺诈系统而言,首先需要有数据的实时流入,在数据流入之后需要进行一定的处理,比如事中风控和事后风控等,风控的结果一般是通过HBase来对外提供在线查询能力。HBase能够提供在线查询能力,但是其在流式数据处理以及机器学习算法的分析等方面都比较欠缺。另外一个例子是大数据为中的离线分析场景,HBase是一个在线的数据存储库,数据可以高并发地流入进去,但是如何对这些数据进行分析却成为一个大问题。HBase本身并没有动态资源,因此就需要外部的分布式计算框架来进行数据分析,这样的能力也正是HBase所欠缺的。
HBase的新挑战
面对上述的这些问题,应该如何处理呢?众所周知,HBase之所以能够广泛地应用于企业之中,主要得益于其是一个优秀的在线查询系统。HBase具有很多优秀的特点,比如具有松散表结构,具有较好的随机查询和范围查询能力,具有高吞吐和低延迟能力,能够存储海量数据,并且具有多版本、增量导入和多维删除的能力。但与此同时,HBase在业务场景中也会面临很多的挑战,比如流式以及批量入库需要相应的生态支持,目前难以实现复杂分析、机器学习和图计算等任务,并且需要实现与Redis、MongoDB等大数据生态的融合等。

Why Spark?
为了解决HBase所遇到的上述挑战,首先想到的就是Spark。之所以首先想到Spark,是因为主要有以下的4点原因:
快:通过query的执行优化、Cache等技术,Spark能够对任意数据量的数据进行快速分析。逻辑回归场景比Hadoop快100倍;
一站式:Spark同时支持复杂SQL分析、流式处理、机器学习、图计算等模型,且一个应用中可组合上面多个模型解决场景问题;
开发者友好:同时友好支持SQL、Python、Scala、Java、R多种开发者语言;
优秀的生态:支持与Kafka、HBase、Cassandra、MongoDB、Redis、mysql、SQL Server等配合使用。
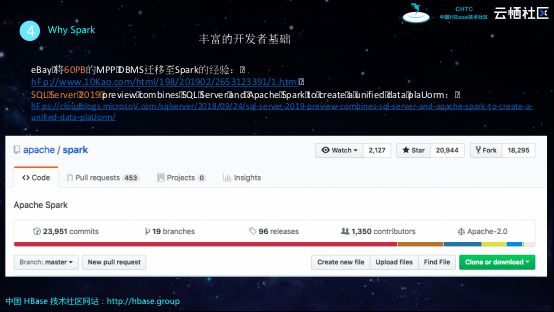
接下来一起看下Spark的流行程度,从下图可以看到,GitHub上Spark项目拥有2万多个Star,1300多个贡献者,并且一直在迭代。这里列举两个业界比较典型的使用Spark的例子,eBay之前基于MPP构建数据仓库,后来却选择将其60PB数据迁移到Spark上进行数据处理;SQL Server这样一个重量级的数据库,在发布其2019版本的时候就将自身与Spark进行了深度融合,这是因为对于SQL Server这样一个传统的数据库而言,其自身也缺乏流式数据入库以及非结构化数据分析、机器学习的能力,因此选择了与Spark进行融合实现互补。同样的,HBase也存在和SQL Server类似的问题,因此阿里云技术团队也在实现HBase和Spark的深度融合。
二.平台架构及案例
当拥有了HBase和Spark这样两个大数据利器之后,如何去构建企业的一站式数据处理平台呢?从下图中的例子可以看到,HBase不再仅仅对外提供在线查询,拥有了Spark的帮助之后,可以通过Spark Streaming来对接Kafka等消息中间件,进而可以实现流式消息入库。同时,Spark也是联邦查询引擎,其拥有一套DataSource的API,因此可以对接MySQL、MongoDB等各种外部数据源,可以通过Spark的作业将外部的数据批量地导入HBase中。当数据沉淀在HBase之后,业务上肯定不会仅对这些数据进行简单的在线查询,可能还需要进行一定的分析和机器学习任务,而Spark支持SQL以及MLlib,因此可以对于数据进行相关的分析,实现业务处理以及数据挖掘,并将处理之后数据回流到HBase里面,对外提供在线查询服务。
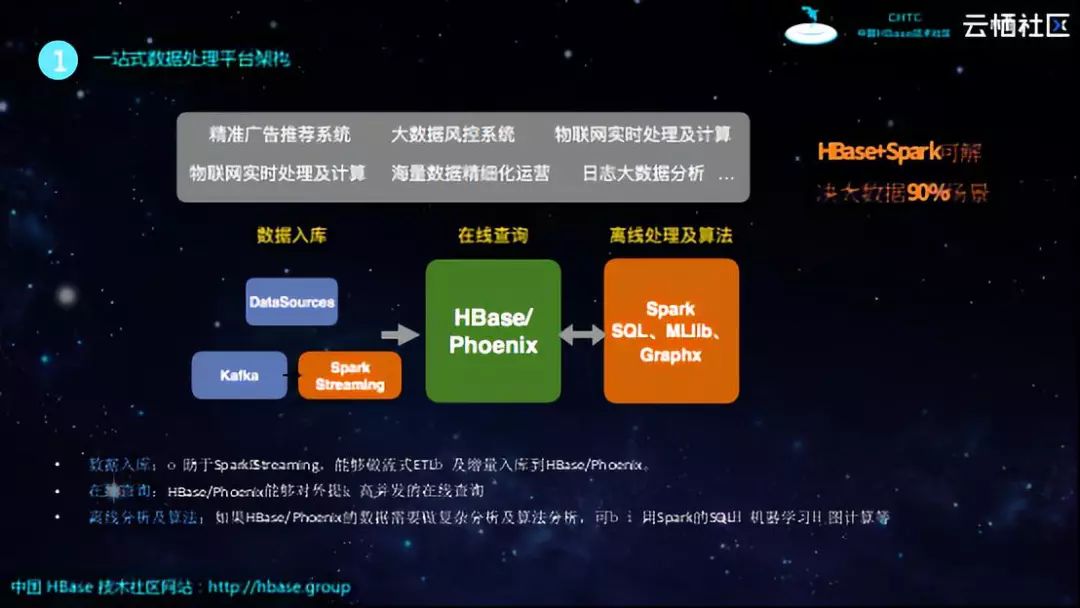
基于上图这样的架构可以非常好地支撑精准的广告推荐系统、大数据风控系统、物联网实时处理及计算、海量数据精细化运营以及日志大数据分析等相关业务场景。HBase+Spark可以解决90%的大数据相关场景,而无需像使用MapReduce、Storm、Pig等一样需要选择太多东西来搭配使用。
典型业务场景:爬虫+搜索引擎
接下来结合一些具体的场景和大家分享阿里云的一些客户是如何使用HBase+Spark来解决业务问题的。第一个场景就是某个用户构建了一个搜索引擎系统,其需要通过一个爬虫集群不断地从抖音、微博等爬取一些帖子和评论等内容,这些消息将会存储在Kafka中,而由于这些消息是非结构化的,并且还需要实时地对外提供服务,就需要接入一个Spark Streaming来消费这些Kafka的日志。Spark Streaming主要做两件事情,一件是将非结构化数据转成系统希望得到的结构,第二件事情就是在Streaming的过程中去反查HBase的维表,进行关联和去重,之后将一条完整的数据流入到HBase里面。目前HBase较为适合点查询,但是由于其需要对外提供检索服务,所以会缺少全文检索能力,因此其所作的事情就是将数据表同步到Solr里面,并基于Solr对外提供全文检索以及复杂查询的能力。与此同时,系统每天每月将HBase数据同步到Spark里面并归档到数据仓库中,并对于数据仓库中的数据做一些复杂的分析。
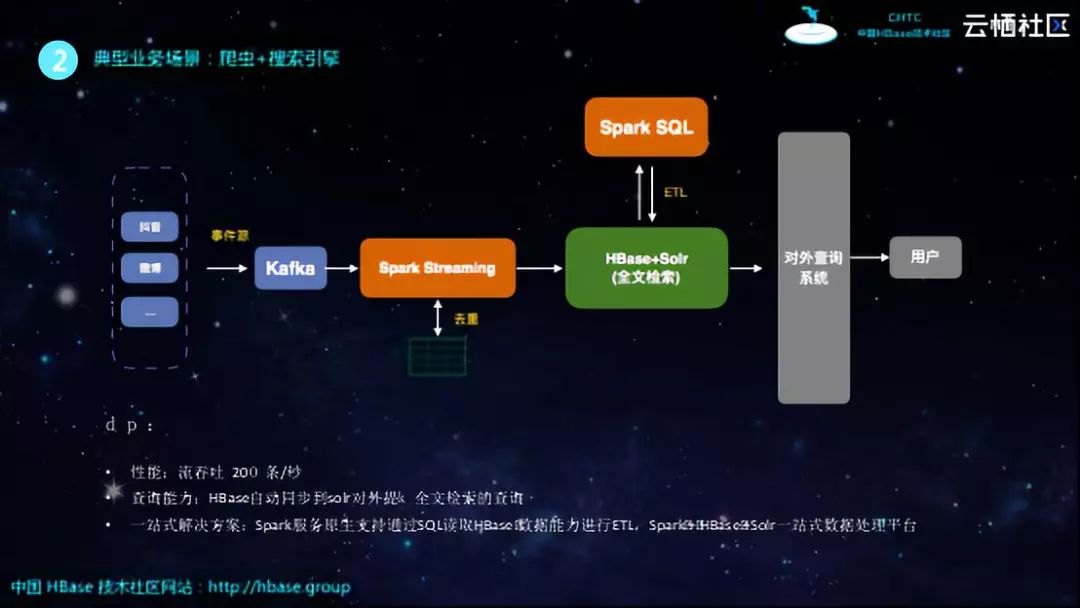
该场景的业务价值在于:基于Spark Streaming流,系统在性能方面,峰值能够达到每秒20万条的吞吐;在查询能力方面,HBase能够自动地同步到Solr对外提供全文检索的查询能力;从整个系统来看,就是基于HBase+Spark+Solr构建了一站式解决方案,从而解决了其业务问题。
典型业务场景:大数据风控系统
第二个比较典型的场景是一个2C的业务,平台需要暴露给外部客户,那么总会出现一些恶意的用户想要攻击系统,比如进行DDoS攻击或者发布恶意消息等,因此企业需要构建自己的风控系统。通过风控系统来识别异常行为,需要将异常行为检测出来并且进行拦截,而且在发现这些行为之后还需要在事后将损失降到最低。
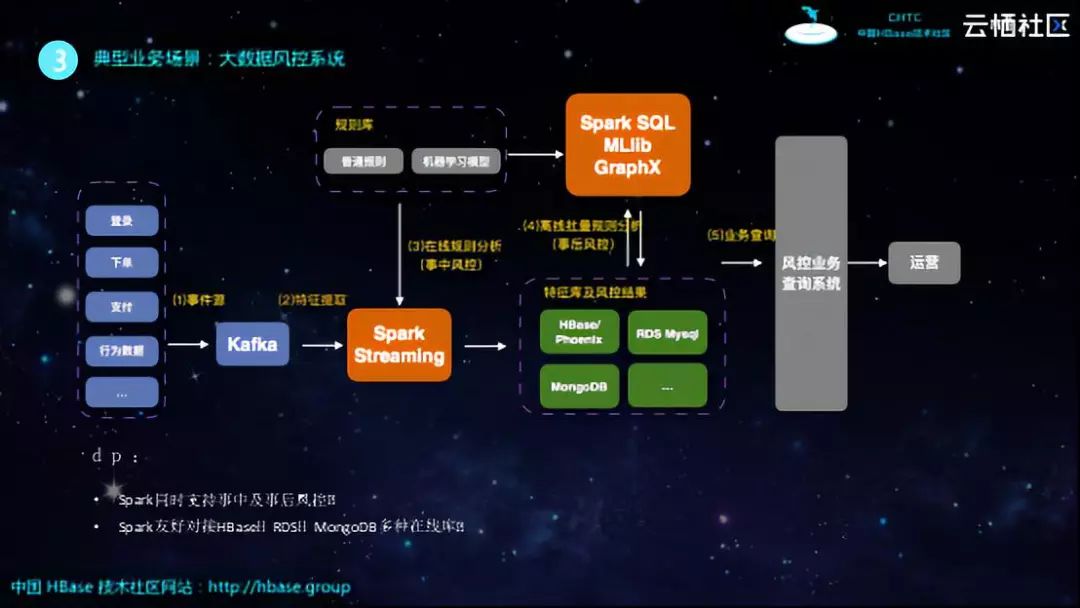
对于风控而言,主要分为事中风控和事后风控。对于如上图所示的系统而言,登录、下单、支付等事件源的数据会流入Kafka,因为Kafka适合于流控,因此可以作为消息中间件,当然这里也可以选择其他的消息中间件。之后Spark Streaming将会消费Kafka里面的数据,在这个过程中会读取之前已经训练好的规则库,基于这些规则以及实时消息可以判断某个行为是否存在问题,因此基于Spark Streaming就可以实现事中风控。当识别出一些不良行为之后,大数据风控系统会提取这些不良数据的特征并将数据写入到HBase里面,之后可以通过Spark SQL查询出在某一段时间内哪些用户发生了不良行为,进而运营人员可以实现针对性的风控处理。另外一部分就是事后风控,由于Spark Streaming是实时的,因此如果处理逻辑比较复杂,就容易造成消息的堆积,因此就需要事后风控。事后风控所做的就是进行全量的计算进而发现不良行为,比如系统每天会将HBase、RDS以及MongoDB等数据全量地同步到Spark里面进行分析,比如像训练Spark MLlib模型也是需要全量数据的,需要读取全量数据库来训练模型并进行全量的分析,分析完成之后对运营提供查询,最终回流到HBase里面。这样的一套架构也是非常典型的,可以基于HBase+Spark实现事中和事后的风控,并且Spark还可以非常友好地对接各种生态和组件。
典型业务场景:构建数据仓库(推荐、风控)
第三个比较典型的场景就是构建数仓。之前构建数仓使用MPP架构基本可以实现,但是当数据量增大之后,MPP的扩展性远不如HBase+Spark。阿里云的一个用户之前基于Greenplum构建数据仓库,但是当数据量增大之后就会遇到很多问题,比如Greenplum运行数据量比较大的Join、Group By等操作会导致集群挂掉,并且集群扩容速度也会变慢。因此,该客户希望通过HBase+Spark构建数据仓库,这样构建之后,客户的数仓不仅降低了成本,还使得性能得以提升。
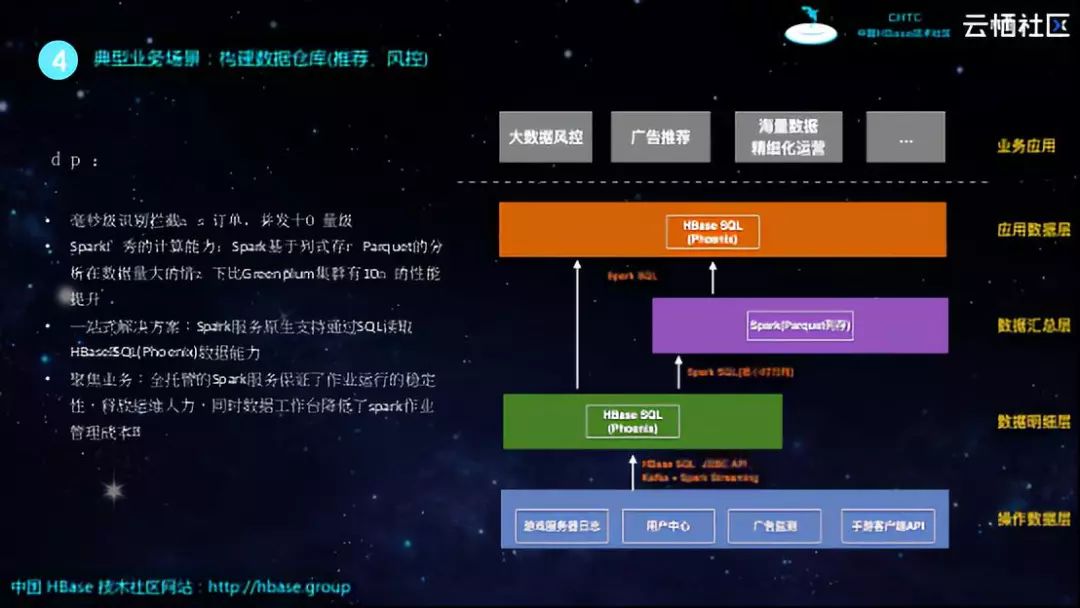
如上图所示的就是比较典型的数仓架构,其总体架构主要分为四层。从下向上来看,最底层是操作数据层,这里存储的是原始的数据,比如服务器日志、用户中心数据、广告监测等。原始的数据进入数仓之后,由于数据往往不够规整,因此需要进行一些ETL操作,在该方案中通过Spark Streaming消费Kafka的数据再写入到Phoenix里面,于是就到了数仓的第二层——数据明细层。所谓数据明细层就是说这些数据还是比较原始的,但是数据格式比较规范,已经可以对外提供查询能力了。在上图中也可以看到,在数据明细层就可以通过HBase直接对外提供业务查询能力。在这之上,实现了更为复杂的Join、Group By等操作和处理之后,就到了数据汇总层,在这一层更加希望数据能够聚合一下,不再是零散的数据,这时候就需要配合Spark SQL来聚合数据进而转换到Spark列存上来,进而实现数据归档。数据汇总层其实就可以看做是一个离线数仓,如果想要制作报表就可以通过这一层的Spark离线数据实现分析,并且可以将数据回流到Phoenix为运营同学提供查询能力,这就可以看做是应用数据层。数据仓库通过以上四层的结构最终为业务应用提供数据能力。
对于客户而言,上图的这套架构所带来的价值就是可以实现毫秒级识别拦截代充订单,并发能够到达十万量级。此外,Spark基于列式存储Parquet的分析在数据量大的情况下能够达到Greenplum集群的10倍性能。因为Spark服务原生支持通过SQL读取 HBase SQL(Phoenix)数据能力,因此提供了一站式解决方案。而全托管的Spark服务保证了作业运行的稳定性,释放运维人力,同时数据工作台降低了Spark作业的管理成本。
三.原理及最佳实践
从上述的几个典型场景可以看出,Spark+HBase能够帮助我们解决很多大数据领域的问题。接下来为大家分享Spark+HBase在大数据应用中的一些痛点、原理以及最佳实践。
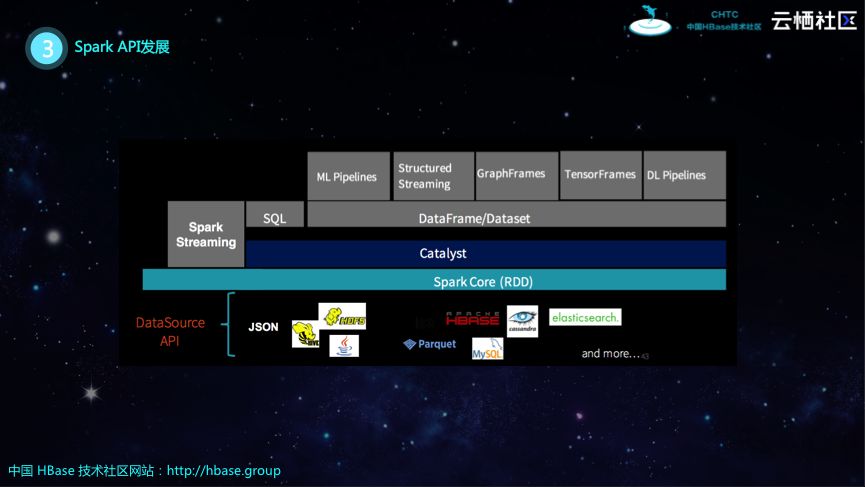
Spark API发展
Spark最开始的API叫做RDD,RDD是不可变的数据集,无法删除和更新,只能做类似于Map、Group By等转换。RDD的优点在于用户可以基于其实现很多任务,但是其缺点就是所有的优化任务都交给了用户,对于不熟悉Spark的用户而言,用起来就会比较困难。因此,Spark在后来就推出了DataFrame,DataFrame对数据增加了Schema,通过Schema可以了解数据具有多少列,每列的类型以及名称等信息。拥有了Schema之后,Spark就可以实现和传统SQL引擎一样的各种优化,比如逻辑优化、执行计划优化等,可以通过引擎帮助用户实现优化,而无需用户自己进行优化。之后,Spark还提供了DataSet,从下图中也可以看出,DataSet所提供的功能是RDD和DataFrame的全集,其需要支持Type-safe以及Encode/Decode等功能,能够在编译阶段发现代码问题,并在Encode和Decode阶段提高效率。
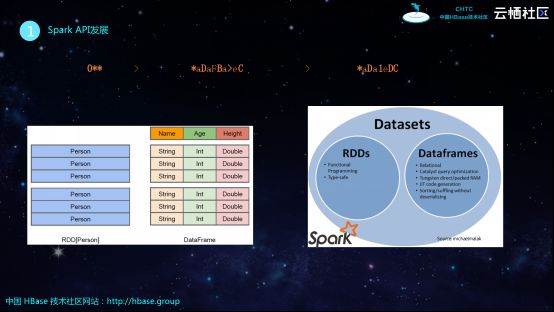
DataFrame和DataSet在性能上的优化
如下图左侧所示的是DataFrame的API,也就是SQL,其含义就是两张表进行join之后在进行filter,其逻辑执行计划是先join再filter,而优化之后生成的物理执行计划则是先filter再join,这样就减少了需要join的数据量,更进一步在物理执行计划中可以将filter推到scan,这就是DataFrame对于Spark带来的优化能力。
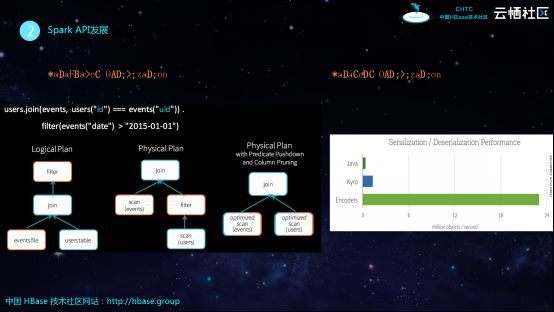
DataSet主要是添加了一套Encode和Decode的机制,从上图中的序列化性能表现对比可以看出,DataSet的序列化能力具有显著提高。Spark在序列化能力上不断进行优化,这样才能更好地解决业务问题,获得更好的开发者基础。
Spark的架构如下图所示,其最底层是RDD,在RDD之上构建了优化器Catalyst,再之上就是DataFrame和DataSet API。目前SQL也是基于Catalyst优化器,在这之上Spark在推进其Structured Streaming、GraphFrames、TensorFrames以及DL Pipelines等上层组件。当然,老的Spark Streaming还是基于RDD的,并且还有很多企业在使用这样的方式。
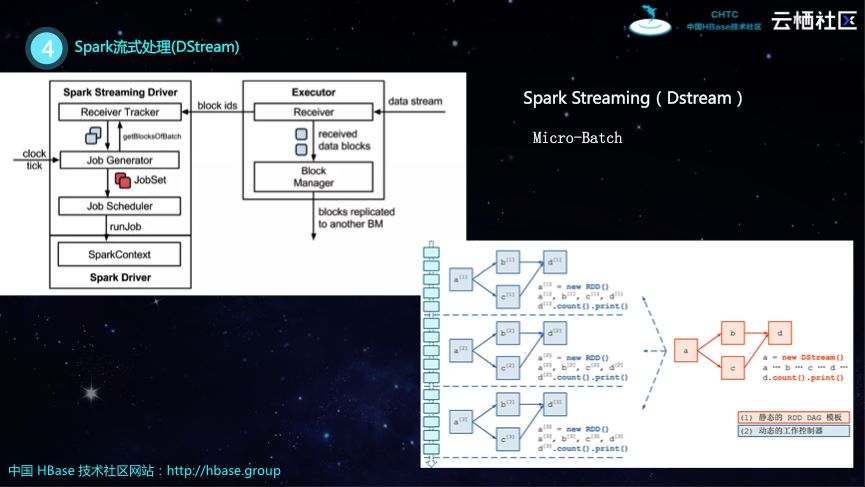
Spark流式处理(DStream)
HBase的实时入库以及ETL都需要依赖Spark Streaming,接下来就为大家分享新老两种Spark Streaming的API。老的Spark Streaming所提供的就是DStream,新的Spark Streaming基于DateFrame构建的Structured Streaming。DStream使用的是Micro-Batch的方式,所谓Micro-Batch就是数据不断地流入的过程中,将数据截断,比如将几秒内的数据组成Spark的一个批处理运行,运行完成之后再将接下来几秒的数据进行处理,如此每次都通过小的批量作业来运行。如下图所示的架构,为了运行批处理,这里设计了Job Generator,通过定时器来设定时间间隔来构建批作业,如果这里的间隔越大,流的吞吐就越高,间隔越小,实时性就会越好。在下图中右侧所示的就是比如有一个Streaming作业,橙色的部分就是基于DStream进行转换,而在DStream底层实际的执行计划还是RDD。
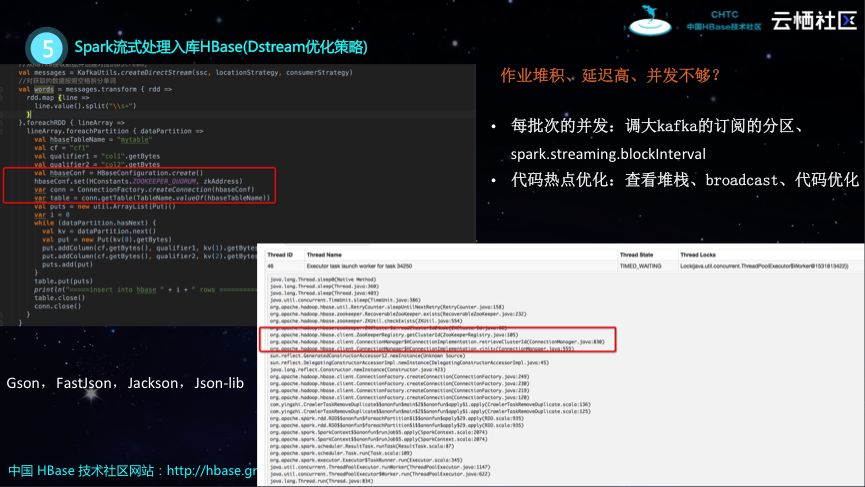
DStream优化策略
在开发DStream的时候会遇到一些问题,比较常见的问题就像作业堆积、延迟高以及并发不够等问题。针对以上这些问题,这里也提供了一些最佳实践。针对于并发问题,一种解决方案将Kafka的Topic订阅的分区调大一些,另外一种就是调整Spark的streaming.blockInterval参数。针对于延迟高问题,或许的确是代码写的有问题,所以需要对于代码热点进行优化,由于Spark Streaming的UI设计比较好,因此在进行排查的时候可以通过查看堆栈等方式发现问题。如下图所示的代码其实可以完成所需功能,但是存在代码热点。
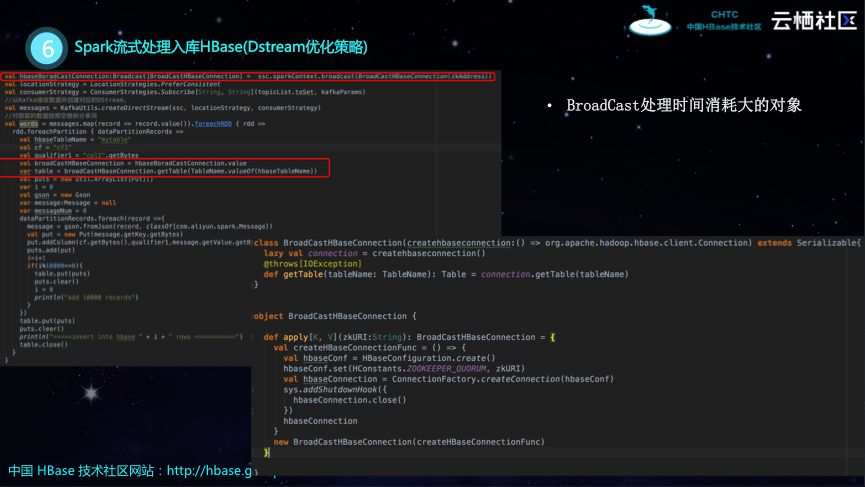
Spark提供了BroadCast能力,因为是并发的,所以可以在Spark的Master端构建一个Collection,然后进行BroadCast,这样的做法大大降低了创建Collection的次数,优化效果非常好。
Spark流式处理入库HBase(Structured Streaming)
Spark目前主推的是Structured Streaming,在之前介绍Spark API的时候也谈到,Spark的API从RDD发展到DataSet。最开始用户无法对于RDD进行优化,但是Spark却希望帮助用户进行优化,简化用户的使用,于是在后来就推出了Structured Streaming,其基于DataSet构建,因此就可以天然地享受Spark的优化。可以认为表的数据不断地流入,Structured Streaming按照表进行数据切分和分析。Structured Streaming具有两种运行模式,分别为Micro-Batch Processing和Continuous Processing,也就是批处理和真正的流处理。根据Spark商业公司DataBrick的测试数据显示,Micro-Batch Processing延迟将近100毫秒,而Continuous Processing的延迟约在1毫秒。
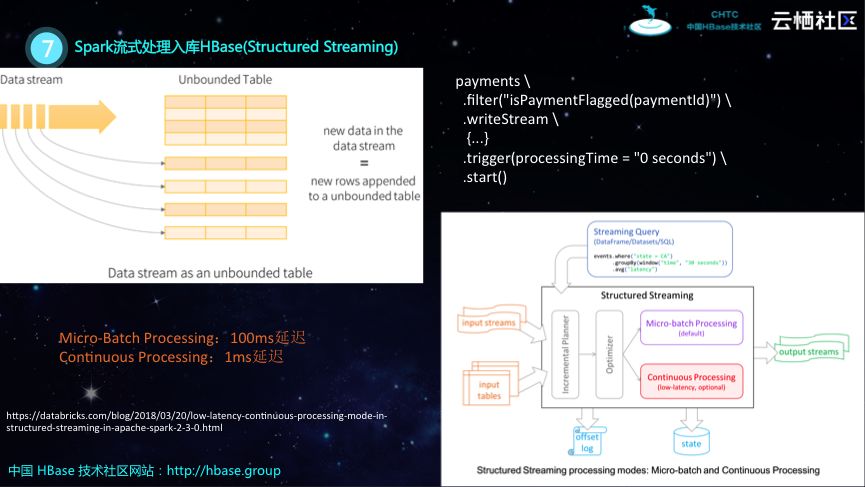
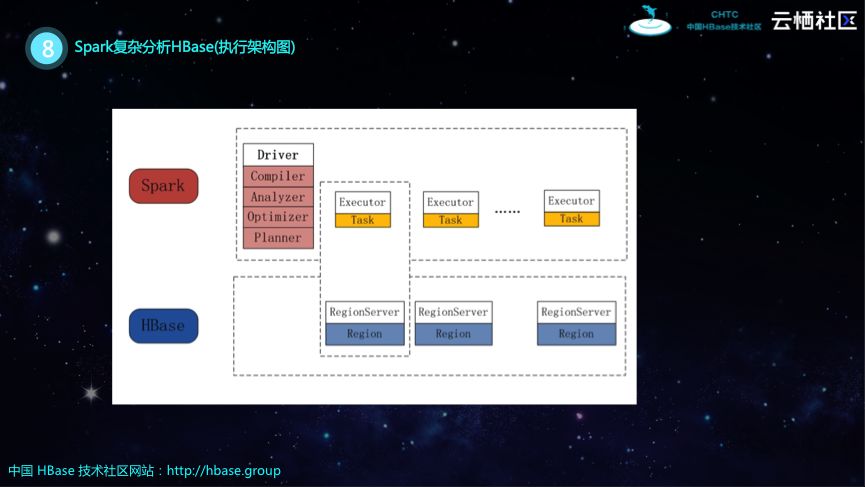
Spark复杂分析HBase
接下来为大家分享Spark可以在HBase的复杂分析上所能够做的事情。如下图所示的就是Spark复杂分析HBase的执行架构图。Spark是一个分布式计算框架,其在实际分析的时候是一个Master/Slave结构,既有Driver也有Executor。Executor上面会并发分布很多Task,每个Task都会去读取HBase Region的某一个片段,这样基于Spark这种外部资源,就可以提高对于HBase的分析能力。
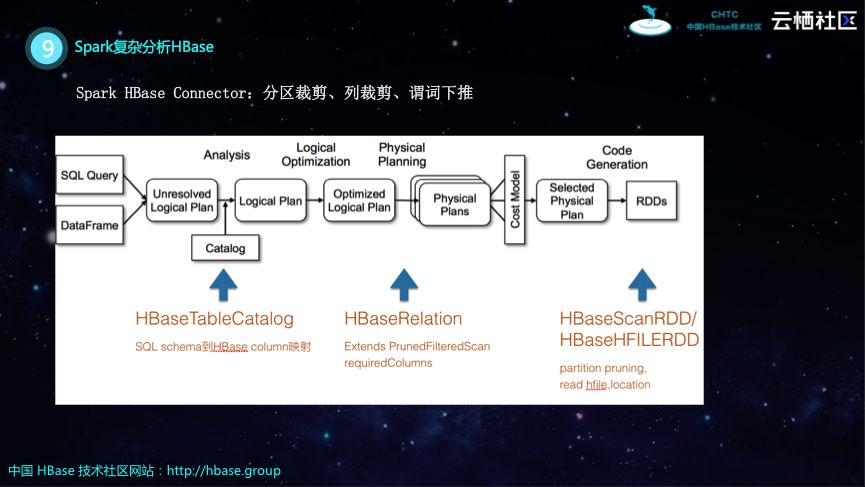
那么在实现方面,如何让Spark具有分析HBase的能力呢?其实Spark提供了一套DataSource的API,很多外部的生态可以基于Data Source实现自己的Collector,然后就可以实现相关的分析优化。在下图中,最左边的一条SQL想要读取HBase的一张表,做一些Map、Group By以及Count等操作,那么首先需要进行Analysis,这里需要基于Catalog类实现HBaseTableCatalog类来做SQL Schema到HBase Column的映射。有了表的优化之后,Spark就会生成逻辑执行计划,进而生成物理执行计划,而在这个过程中会执行一些优化,比如分区裁剪、列裁剪、谓词下推等,实现尽量少地从HBase读取数据。在生成物理执行计划的过程中需要HBaseRelation,HBaseRelation能够实现将逻辑执行计划推到HBase里面,进而使得流出来的数据比较少,这样不仅降低了存储的压力,也降低了Spark分析的压力。在生成物理执行计划级之后,可能需要实现RDD以及之后如何去创建和复用Collection以及如何Scan,Spark对接MongoDB或者Redis都需要做这些事情。
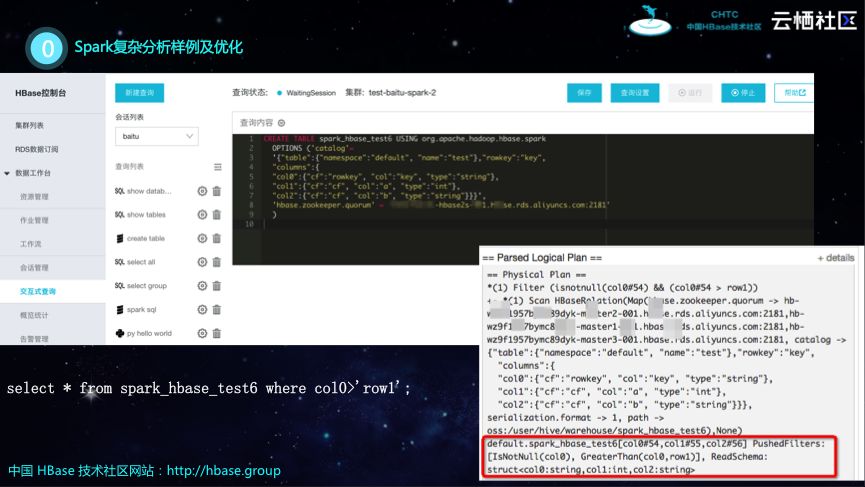
Spark复杂分析样例及优化
接下来通过讲解一个Spark复杂分析样例为大家介绍Spark分析HBase是怎么实现的。如下图上部所示的是一个建表语句,比如在Spark里面需要建一张表,这张表需要指定去关联HBase或者其他数据源。此外,还需要一个映射,将Spark表里面的Schema和HBase如何映射。在完成上述关联之后,只需要执行相应的SQL语句就可以产生下图中所示的逻辑执行计划,从红框里可以看出,Spark构建了HBase的Scan,并且filter条件都已经推移到HBase端了。
以上分享的最佳实践的代码和文档都在GitHub上,大家可以下载并进行实践。

四.HBase X-Pack服务
最后和大家分享关于HBase X-Pack服务的内容。因为HBase+Spark在很多企业中都得到了广泛的应用,很多企业也希望能够使用全托管的HBase+Spark,因此阿里云技术团队就构建了HBase X-Pack服务,能够帮助客户更好地解决业务场景。
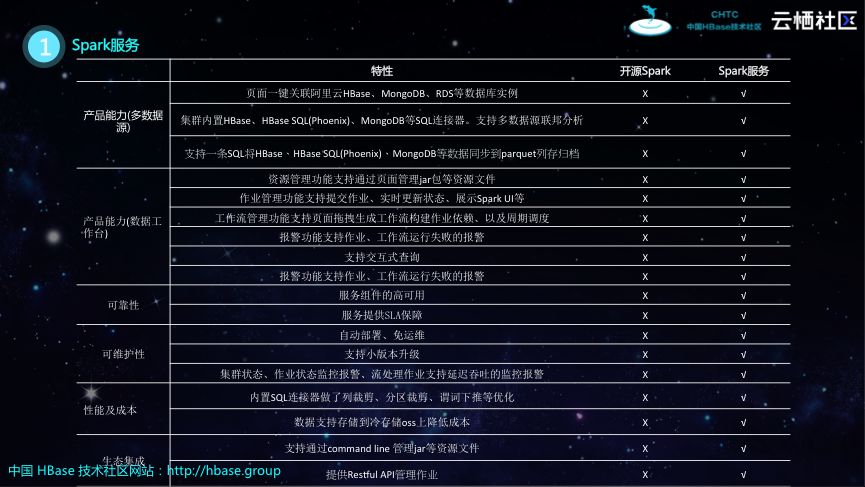
Spark服务
下表对比了阿里云所提供的HBase X-Pack里面Spark和开源的Spark之间的区别,阿里云的HBase X-Pack提供了很多开源版本Spark没有的功能,并且可以实现全托管。
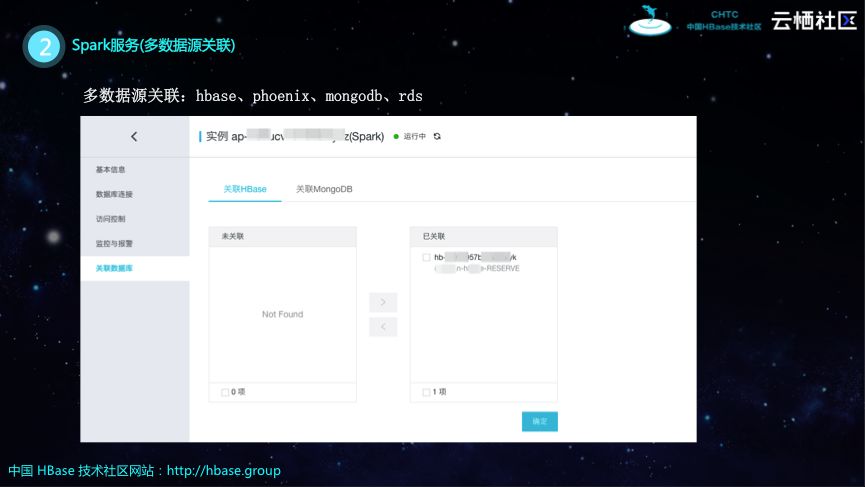
多数据源关联
阿里云HBase X-Pack可以关联多种数据源,比如HBase、Phoenix、MongoDB和RDS等,只需要在阿里云控制台上点击几下按钮就可以实现关联。
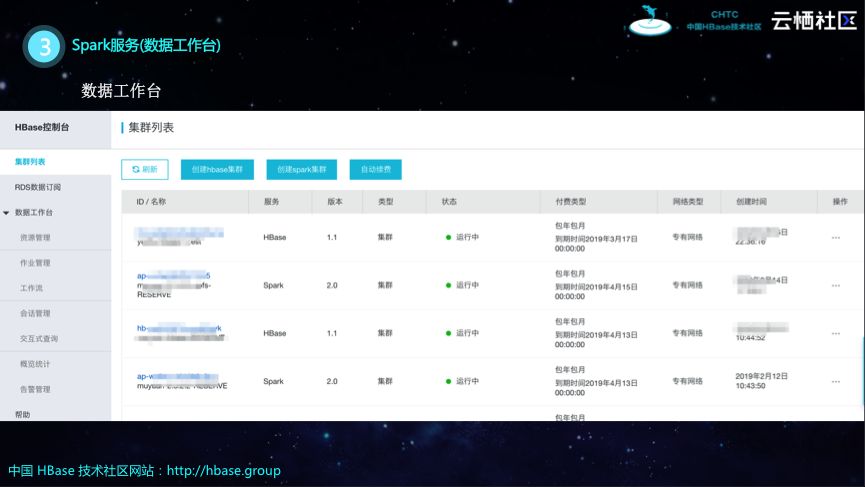
数据工作台
阿里云HBase X-Pack的数据工作台集成资源管理、作业管理、工作流、会话管理、集群管理以及告警等多种功能。
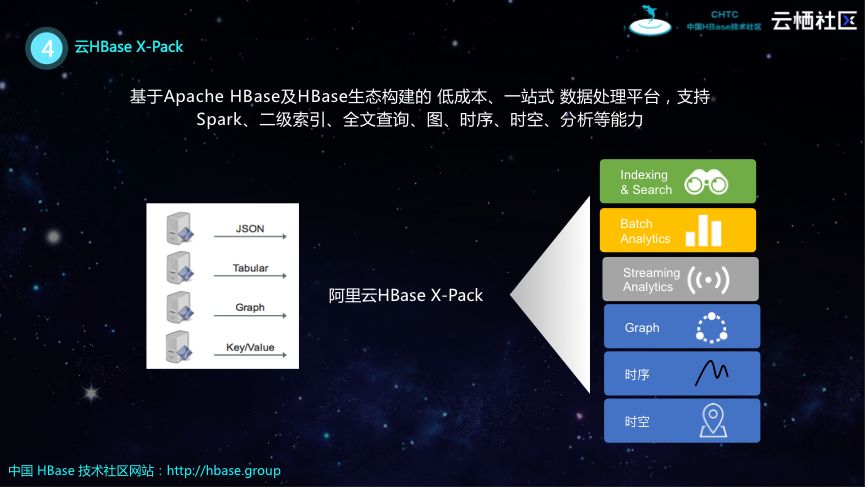
云HBase X-Pack
阿里云HBase X-Pack是基于Apache HBase及HBase生态构建的低成本、一站式数据处理平台,其支持Spark、二级索引、全文查询、图、时序、时空、分析等能力。
如下图所示的是阿里云HBase的架构,其实云上HBase和线下的HBase还是存在一些区别的。比如云上HBase在底层存储方面具有很多选择,可以选择SSD、HDD以及OSS等,可以根据业务的具体需求进行选择。而在阿里云HBase之上还支持了SQL、时序、时空、分析等多种能力。

技术社群
【HBase生态+Spark社区大群】
群福利:群内每周进行群直播技术分享及问答
加入方式1:
https://dwz.cn/Fvqv066s?spm=a2c4e.11153940.blogcont688191.19.1fcd1351nOOPvI
加入方式2:钉钉扫码加入
免费试用
以上是关于HBase分享 | 基于HBase和Spark构建企业级数据处理平台的主要内容,如果未能解决你的问题,请参考以下文章
Spark 操作hbase(构建一个支持更新和快速检索的数据库)
基于hbase-spark实现hive到hbase的数据传输中间件