HBase赠书 | 阿里云HBase SQL一站式解决复杂查询难题
Posted HBase技术社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase赠书 | 阿里云HBase SQL一站式解决复杂查询难题相关的知识,希望对你有一定的参考价值。
社区福利
《HBase原理与实践》
↓
参与方式
截止到2019.08.23 00:00
留言点赞量排名前三
获赠
《HBase原理与实践》电子书
一.背景概述
HBase作为海量在线存储引擎,被广泛应用于推荐、风控、物联网、画像、表单等大数据场景。Phoenix作为HBase的SQL层,极大降低了用户使用门槛,并且实现了二级索引、加盐表、动态列等大量实用功能。HBase底层存储基于LSM,LSM能将业务的随机写转为顺序写,能有效提升写吞吐,但是其查询只适合于Rowkey的前缀匹配,查询模式单一;Phoenix二级索引,底层是跟原表关联的索引表,同样也是前缀匹配,一个表可以有多个索引,这样可以增加查询范式,但是索引数目不能太多,否则写放大的问题会比较严重。对于更加复杂的查询场景,比如表单、日志查询里面的模糊查找,用户画像里面的随机条件组合等等,HBase + Phoenix的组合就不能支持。该问题是基于LSM的NoSQL数据库的通用问题,除了HBase,Cassandra、LevelDB、RocksDB、MongoDB的Wired Tiger引擎等都有相同的问题。
当前用户常见的解决方法就是给主存储引擎搭配检索引擎,比如Lucene、ElasticSearch、Solr。该方案实际使用过程中十分复杂:
用户学习成本double,门槛提高;
用户要解决数据同步,数据同步又分批量离线同步和增量实时同步,用户要选择不同的解决方案,比如用mr作业批量同步,分析wal日志或者双写的方式实时同步;
同步过程中有数据一致性问题,比如写入检索引擎跟写入存储引擎的数据顺序不一致,这个很难在应用层完全保证;
数据延迟问题,两个引擎的写入吞吐不一致,往往存储引擎要比检索引擎快很多,容易导致数据堆积,甚至带来稳定性问题。
阿里云HBase团队设计并实现了Search Index功能,一站式解决这些问题,并且支持SQL,用户通过DDL、DQL就可以进行复杂索引操作。
二.方案实现
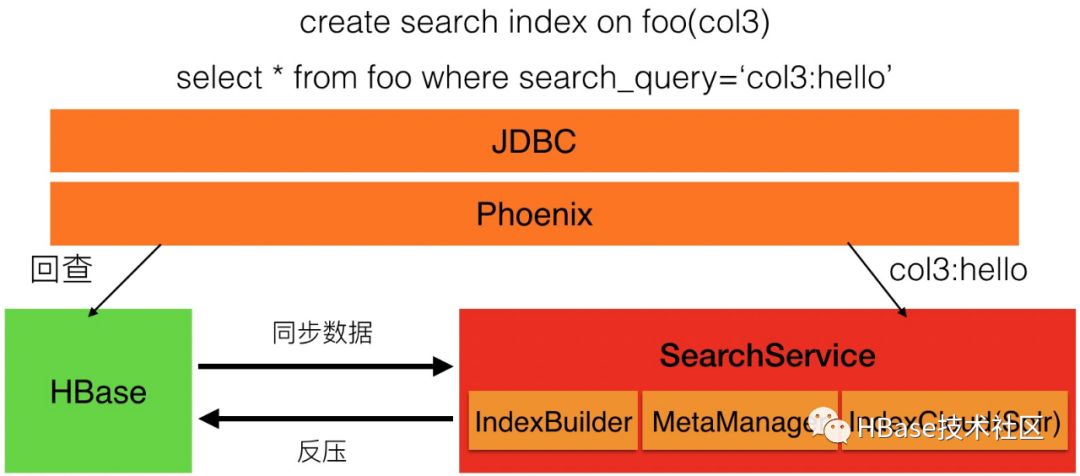
SearchIndex架构如图所示,Phoenix会同时支持全文引擎(Solr)和KV引擎(HBase),并且提供管理和查询索引相关的SQL表达。我们目前基于Solr自研了SearchService服务,涵盖了所有索引管理,数据同步,元数据管理等方面的功能。下面结合图中的Create语句和Select语句对架构设计进行比较深入的说明。
create语句在执行的时候,可分为以下步骤:
Phoenix会解析SQL语句,确定Solr中Collection的存储格式,并生成从Phoenix表到Solr Collection的映射关系;
在IndexCloud(Solr)中创建Collection;
开启从Phoenix表到Solr Collection的实时数据同步;
启动分布式作业将存量数据同步到Solr中;
映射的时候,Phoenix默认只在Solr中存储索引,原始数据不需要存储,这样可以节省存储开销。创建成功后,用户可以直接使用Phoenix Upsert语句往Phoenix里面插入数据,后台会将做自动实时同步。为了解决Solr中数据延迟的问题,我们还实现了反压机制,数据可见时间可配置,比如10s,那么Solr中数据比HBase中数据可见最大间隔会由系统保证在10s左右。
Select语句在执行的时候,可分为以下步骤:
Phoenix解析SQL语句,识别哪些请求需要下发到Solr,哪些需要去HBase中执行;
将1中识别到的请求发给Solr,拿到返回的RowKey列表;
根据2中拿到的RowKey列表,回查HBase,拿到最终的返回结果。
除了Create、Select,其他DDL和DQL语法请参考文档:SearchIndex用户文档
https://help.aliyun.com/document_detail/122594.html
三.用法示例
SearchIndex可以很好地满足表单、用户画像、日志等场景的复杂查询需求,本章以表单查询为例说明SearchIndex的用法,在表单查询场景中,大部分查询可以通过前缀匹配的方式解决,但是会对表单详情数据进行模糊查找。
--创建表
create table items(col1 integer primary key, name varchar, content varchar, addr varchar);
--插入数据
upsert into items values(1, 'zhangsan', 'hello world!', 'hangzhou')
--创建索引,存量数据默认会同步导入
create search index on items(content{analyzer=standard})
--插入数据,会通过异步方式实时增量导入
upsert into items values(2, 'lisi', 'Xihu is a beautiful place.', 'hangzhou')
--查询表单
select name, addr from items where search_query='CONTENT:hello';
--删除索引
drop search index on items;
四.总结与展望
本文介绍了SearchIndex解决的用户问题,SearchIndex当前的实现逻辑,以及SearchIndex解决表单查询场景的简单示例。用户可以同时享受到KV引擎带来的高并发、高吞吐的读写能力,和全文引擎带来的在线复杂查询能力,并且提供SQL的统一表达,极大提升了产品易用性。通过SearchIndex的一站式产品能力,用户可以更加灵活高效地解决业务问题。
后续我们团队会对SearchIndex持续优化升级。比如,1. 目前用户还需要自己识别那些字段在Search Index中,然后编写Search Query,后续我们会支持native SQL,用户只需要按照普通的SQL语法写Query语句就可以了;2. 第一版本中还只支持条件组合,全文等查询语法,对于分组聚合、排序的加速还不支持,在后续版本中也会增强该功能;3. 数据同步和查询性能也会持续优化。


本群为HBase+Spark技术交流讨论,整合最优质的专家资源和技术资料会定期开展线下技术沙龙,专家技术直播,专家答疑活动。点击链接钉钉入群:
https://dwz.cn/Fvqv066s或扫码进群

本群为Cassandra技术交流讨论,整合最优质的专家资源和技术资料会定期开展线下技术沙龙,专家技术直播,专家答疑活动。Cassandra 社区钉钉大群:
https://c.tb.cn/F3.ZRTY0o或扫码进群
以上是关于HBase赠书 | 阿里云HBase SQL一站式解决复杂查询难题的主要内容,如果未能解决你的问题,请参考以下文章
HBase解读 | 阿里云HBase SQL(Phoenix)服务深度解读
15位阿里RedisMongoDBHBase大咖分享,深度解析数据库技术!(文末有赠书福利)
在阿里云用Flink Sql同步polardb数据到hbase