转载 | HBase 事务和并发控制机制原理
Posted 创智俱乐部ISA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了转载 | HBase 事务和并发控制机制原理相关的知识,希望对你有一定的参考价值。
点击蓝字关注,创智助你长姿势
作为一款优秀的非内存数据库,HBase 和传统数据库一样提供了事务的概念,只是 HBase 的事务是行级事务,可以保证行级数据的原子性、一致性、隔离性以及持久性,即通常所说的 ACID 特性。为了实现事务特性,HBase 采用了各种并发控制策略,包括各种锁机制、MVCC 机制等。本文首先介绍 HBase 的两种基于锁实现的同步机制,再分别详细介绍行锁的实现以及各种读写锁的应用场景,最后重点介绍 MVCC 机制的实现策略。
HBase 同步机制
HBase 提供了两种同步机制,一种是基于 CountDownLatch 实现的互斥锁,常见的使用场景是行数据更新时所持的行锁。另一种是基于 ReentrantReadWriteLock 实现的读写锁,该锁可以给临界资源加上 read-lock 或者 write-lock 。其中 read-lock 允许并发的读取操作,而 write-lock 是完全的互斥操作。
CountDownLatch
Java 中,CountDownLatch 是一个同步辅助类,在完成一组其他线程执行的操作之前,它允许一个或多个线程阻塞等待。CountDownLatch 使用给定的计数初始化,核心的两个方法是countDown()和await() ,前者可以实现给定计数倒数一次,后者是等待计数倒数到0,如果没有到达0,就一直阻塞等待。结合线程安全的map容器,基于test-and-set机制,CountDownLatch 可以实现基本的互斥锁,原理如下:
1. 初始化:CountDownLatch 初始化计数为 1
2. test 过程:线程首先将临界资源作为 key,latch 作为 value尝试插入线程安全的 map 中。如果返回失败,表示其他线程已经持有了该锁,调用 await 方法阻塞到该 latch 上,等待其他线程释放锁;
3. set 过程:如果返回成功,就表示已经持有该锁,其他线程必然插入失败。持有该锁之后执行各种操作,执行完成之后释放锁,释放锁首先将 map 中对应的 KeyValue 移除,再调用latch 的 countDown 方法,该方法会将计数减1,变为0之后就会唤醒其他阻塞线程。
HBase中行锁的具体实现
HBase 采用行锁实现更新的原子性,要么全部更新成功,要么失败。所有对 HBase 行级数据的更新操作,都需要首先获取该行的行锁,并且在更新完成之后释放,等待其他线程获取。因此,HBase 中对同一行数据的更新操作都是串行操作。
行锁相关数据结构
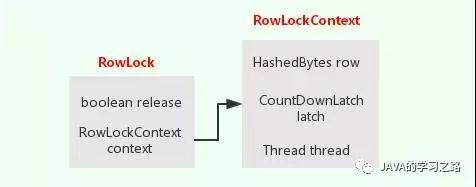
如上图所示,HBase 中行锁相关的主要结构有 RowLock 和RowLockContext 两个类,其中 RowLockContext 类存储行锁相关上下文信息,包括持锁线程、被锁对象以及可以实现互斥锁的 CountDownLatch 对象等等,RowLockContext 是RowLock 的一个属性,除此之外,RowLock 还包含表征行锁是否已经释放的 release 字段。具体字段如下图所示:


更新加锁流程
1. 首先使用 rowkey 以及自身线程对象生成行锁上下文RowLockContext 对象
2. 再将 rowkey 作为 key ,RowLockContext 对象作为value调用 putIfAbsert 方法写入全局 map 中。key 的唯一性,保证map中最多只有一个 RowLockContext 。putIfAbsent 方法会返回一个 existingContext 对象,该对象表示 key 插入前 map中对应该 key 的 value 值,根据 existingContext 是否为 null、是否是自身线程创建,可以分为如下三种情况:
(1)existingContext 对象为 null ,表示该行锁没有被其他线程持有,可以根据创建的上下文对象持有该锁
(2)existingContext 是自身线程创建,表示自身线程已经再创建RowLockContext 对象,直接使用存在的RowLockContext 对象持有该锁。这种情况会出现在批量更新线程中,一次批量更新可能前前后后对某一行数据更新多次,需要多次持有该行数据的行锁,在 HBase 中是被允许的。
(3)existingContext 是其他线程创建,则该线程会阻塞在此上下文所持锁上,直至所持行锁被释放或者阻塞超时。如果所持行锁释放,该线程会重新竞争写全局 map ,一旦竞争成功就持有该行锁,否则继续阻塞。而如果阻塞超时,就会抛出异常,不会再去竞争该锁。
释放流程
在线程更新完成操作之后,必须在 finnally 方法中执行行锁释放操作,即调用 rowLock.release ()方法,该方法主要执行如下两个操作:
1. 从lockedRows 这个全局map中将该row对应的RowLockContext 移除
2. 调用 latch.countDown() 方法,唤醒其他阻塞在 await 上等待该行锁的线程
HBase中读写锁的使用
HBase 中除了使用互斥锁实现行级数据的一致性之外,也使用读写锁实现store级别操作以及 region 级别操作的并发控制。比如:
1. Region 更新读写锁:HBase在执行数据更新操作之前都会加一把 Region 级别的读锁(共享锁),所有更新操作线程之间不会相互阻塞;然而,HBase 在将 memstore 数据落盘时会加一把 Region 级别的写锁(独占锁)。因此,在 memstore数据落盘时,数据更新操作线程(Put 操作、Append 操作、Delete 操作)都会阻塞等待至该写锁释放。
2. Region Close 保护锁:HBase 在执行 close 操作以及 split操作时会首先加一把 Region 级别的写锁(独占锁),阻塞对region 的其他操作,比如 compact 操作、flush 操作以及其他更新操作,这些操作都会持有一把读锁(共享锁)
3. Store snapshot 保护锁:HBase 在执行 flush memstore 的过程中首先会基于 memstore 做 snapshot ,这个阶段会加一把 store 级别的写锁(独占锁),用以阻塞其他线程对该memstore 的各种更新操作;清除 snapshot 时也相同,会加一把写锁阻塞其他对该 memstore 的更新操作。
HBase中MVCC机制的实现
如上文所述,HBase 分别提供了行锁和读写锁来实现行级数据、Store 级别以及 Region 级别的并发控制。除此之外,HBase 还提供了 MVCC 机制实现数据的读写并发控制。MVCC ,即多版本并发控制技术,它使得事务引擎不再单纯地使用行锁实现数据读写的并发控制,取而代之的是,把行锁与行的多个版本结合起来,经过简单的算法就可以实现非锁定读,进而大大的提高系统的并发性能。HBase 正是使用行锁 + MVCC 保证高效的并发读写以及读写数据一致性。
MVCC机制简介
在了解 HBase 如何实现 MVCC 之前,我们首先需要了解当前仅基于行锁实现的更新操作对于读请求有什么影响。下图为HBase 基于行锁实现的数据更新时序示意图:
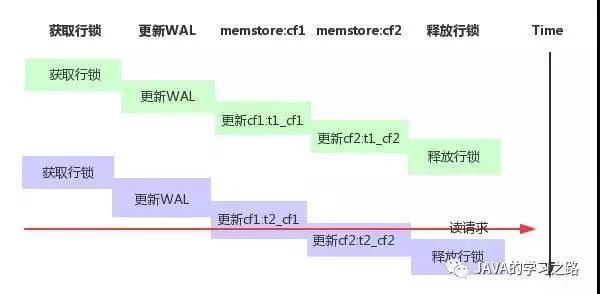
上图中简单地表述了数据更新流程(后续文章会对 HBase 数据写入进行深入的介绍),简单来说,数据更新可以分为如下几个阶段:获取行锁、更新 WAL 、数据写入本地缓存memstore 、释放行锁。
如上图所示,前后分别有两次对同一行数据的更新操作。假如第二次更新过程在将列簇 cf1 更新为 t2_cf1 之后中有一次读请求进来,此时读到的第一列数据将是第二次更新后的数据t2_cf1 ,然而第二列数据却是第一次更新后的数据 t1_cf2 ,很显然,只针对更行操作加行锁会产生读取数据不一致的情况。最简单的数据不一致解决方案是读写线程公用一把行锁,这样可以保证读写之间互斥,但是读写线程同时抢占行锁必然会极大地影响性能。
为此,HBase 采用 MVCC 解决方案避免读线程去获取行锁。MVCC 解决方案对上述数据更新操作时序和读操作都进行了一定的修正,主要新增了一个写序号和读序号,其实就是数据的版本号。修正后的更新操作时序示意图为:
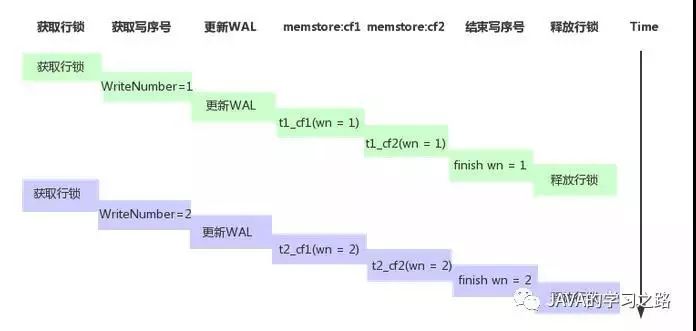
如上图所示,修正后的更新操作主要新增了‘获取写序号’和’结束写序号’两个步骤,并且每个 cell 数据写 memstore 操作都会携带该写序号。那读请求需要经过什么样的修正呢?HBase 的做法如下:
(1)每个读操作开始时都会分配一个读序号,称为读取点
(2)读取点的值是所有的写操作完成序号中的最大整数
(3)一次读操作的结果就是读取点对应的所有cell值的集合
如下图所示,第一次更新获取的写序号为 1,第二次更新获取的写序号为 2。读请求进来时写操作完成序号中的最大整数为 wn=1,因此对应的读取点为 wn=1,读取的结果为 wn=1所对应的所有 cell 值集合,即为 t1_cf1 和 t1_cf2 ,这样就可以实现以无锁的方式读取到一致的数据。
HBase 中 MVCC 实现
HBase 中,MVCC 的具体实现类为 MultiVersionConsistencyControl ,该类维护了两个 long 型的变量、一个 WriteEntry 对象和一个 writeQueue 队列:
1. long memstoreRead :记录当前全局的读取点,读请求进来之后首先会获取该读取点
2. long memstoreWrite :记录当前全局的写序号,根据它为下一个更新线程分配新的写序号
3. writeEntry :记录更新操作的写序号对象,主要包含两个变量,一个是 writeNumber,表示写序号;一个是布尔类型的 completed ,表示该次更新是否完成
4. writeQueue :当前所有更新操作的写序号对象集合
获取写序号
根据上文中更新数据时序图可知,更新线程获取行锁之后就需要获取写序号,对应的方法为 beginMemstoreInsert ,该方法将 memstoreWrite 加1,生成 writeEntry 对象并插入到队列writeQueue ,返回 writeEntry 对象。Note :生成的writeEntry对象中包含写序号 writeNumber,更新线程会将该writeNumber 设置为cell数据的一个属性。
结束写序号
数据更新完成之后,释放行锁之前,更新线程会调用 completeMemstoreInsert 方法更新writeEntry 对象以及 memstoreRead 变量,具体分为如下两步:
1. 首先将该 writeEntry 对象标记为’已完成’,再将全局读取点memstoreRead 尽可能多地往前移。前移算法为遍历队列writeQueue 中所有的 writeEntry 对象,移除掉已经标记为’已完成’的 writeEntry 直至遇到未完成的 writeEntry ,最后将memstoreRead 变量更新为最新已完成的 writeNumber 。
2. 注意上述 memstoreRead 变量有可能并不等于当前更新线程的 writeNumber ,这种情况下该更新线程对数据的更新操作对用户并不可见。为了实现更新完成之后更新结果即对用户可见,需要等待 memstoreRead 变量前移到当前更新线程的 witeNumber 。因此它会阻塞当前线程,等待其他线程对应的 writeEntry 对象标记为’已完成’,直至 memstoreRead 等于当前线程的 writeNumber 。
总结
HBase 提供了各种锁机制和 MVCC 机制来保证数据的原子性、一致性等特性,其中使用互斥锁实现的行锁保证了行级数据的原子性,使用JDK提供的读写锁实现了 Store 级别、Region 级别的数据一致性,同时使用行锁 +MVCC 机制实现了在高性能非锁定读场景下的数据一致性。
原文链接:
https://mp.weixin.qq.com/s/FPWnzTZovEiyqrqhExK45w
创智俱乐部
微信:sziitlSA
一个让你涨姿势的社团
长按二维码关注
以上是关于转载 | HBase 事务和并发控制机制原理的主要内容,如果未能解决你的问题,请参考以下文章