Hbase理论-数据模型
Posted 架构师技术之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hbase理论-数据模型相关的知识,希望对你有一定的参考价值。
Hbase-核心概念
RowKey:表中每条记录的主键
Column Family:列族,将表进行列向切割,后面简称CF;
Column:属于某一个列族,可动态扩展
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义;
Value:数据
Hbase-数据模型:逻辑视图
Table+行
HBase使用时+列+列簇+时间戳实现了数据的多版本支持
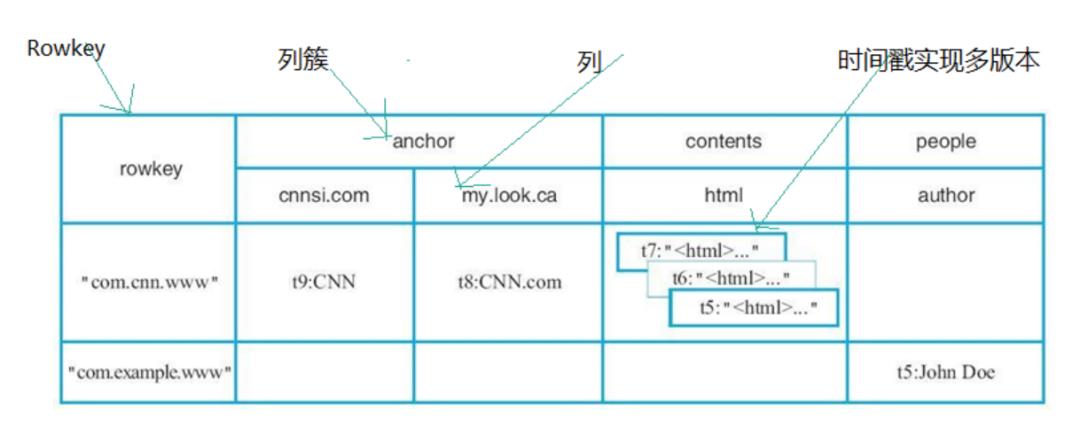
多维稀疏排序Map-物理视图
举个例子,上节逻辑视图中行"com.cnn.www"以及列"anchor:cnnsi.com"对应的数值"CNN"实际上在HBase中存储为如下KV结构

Hbase-数据模型:物理视图
1、与大多数数据库系统不同,HBase中的数据是按照列簇存储的,即将数据按照列簇分别存储在不同的目录中。
2、列簇anchor的所有数据存储在一起形成,不同CF的数据是存在不同的文件里面
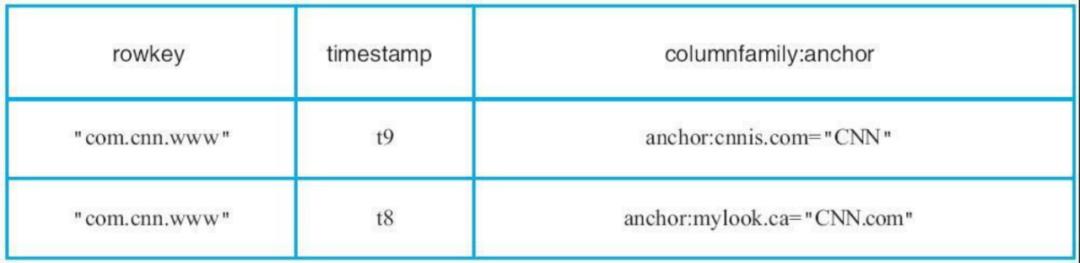
Hbase-数据模型:物理视图
列簇contents的所有数据存储在一起形成
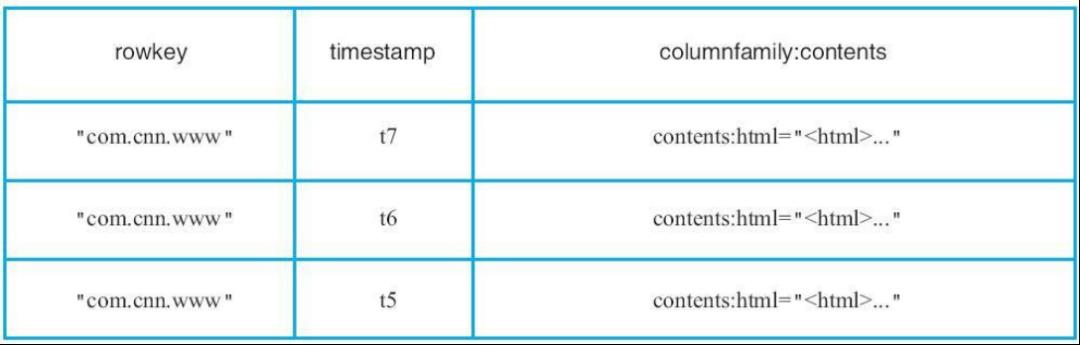
列簇people的所有数据存储在一起形成:

什么是行式存储?
行式存储:行式存储系统会将一行数据存储在一起,一行数据写完之后再接着写下一行,最典型的如mysql这类关系型数据库
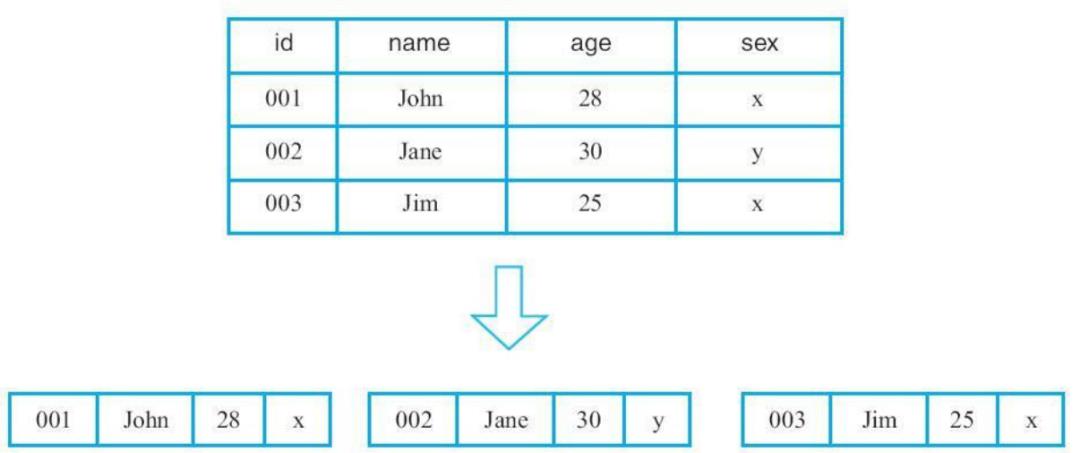
什么是列式存储?
列式存储理论上会将一列数据存储在一起,不同列的数据分别集中存储,最典型的如Kudu、Parquet on HDFS等系统(文件格式),如图所示。
为什么HBase采用列簇存储?
HBase的设计目标是海量,高吞吐存储。数据在底层是基于LSMT那一套的实现(当然分了很多region,支持分布式)。简单来说,要维护一套memstore + 可分裂的filestore的存储
访问的方式不一样。假如:用hbase存储一个产品的信息,比如A列是产品详情。详情数据量大,但不会经常变。而B列是产品的关注次数,会随着用户点击“关注“/“取消关注”而频繁变化。对hbase而言,新数据更新总会进入memstore,然后满了就会写filestore。如果A和B在一个column family,写入的过程是要A和B两列都要写的。但实际A的数据可能就没变,所以A列的写入浪费了IO。如A和B拆到两个column family,那么B的更改只会对自己的filestore写入。
压缩方式不一样。HBase允许为每个column family配置一个compressor。不同数据类型适合的压缩方式不一样。如文本很适合压缩。但如jpg和png图片这中就不适合,它们的数据本身已经是被压缩的了,再压只是浪费CPU而已。但如果不同类型数据在同一个column family,就意味着它们要共享同一个压缩方式。这时也许需要考虑将他们拆开成不同的column family。
权限管理。HBase的ACL控制可以定义每个column family可以定义不同的权限。所以如果有希望一拨人能访问列A、B、C,另外一拨人访问列D、E、F这样的需求,可以考虑使用column family。
从概念上来说,列簇式存储介于行式存储和列式存储之间,可以通过不同的设计思路在行式存储和列式存储两者之间相互切换。很显然这种设计模式就等同于列式存储。
总之,trade off is everything
Hbase-table 操作
------------------------------------------------------
以上是关于Hbase理论-数据模型的主要内容,如果未能解决你的问题,请参考以下文章