终于把动态规划与策略迭代值迭代讲清楚了
Posted 深度学习与先进智能决策
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了终于把动态规划与策略迭代值迭代讲清楚了相关的知识,希望对你有一定的参考价值。
以爱与青春为名,陪你一路成长
上一节我们说了,它是对完全可观测的环境进行描述的,也就是观测到的内容完整决定了决策所需要的特征。马尔可夫决策过程可以用方程组求解简单问题,但是对于复杂一点的问题,一般通过迭代的思想对其进行求解。动态规划是非常有效的求解马尔可夫决策过程的方法。
动态规划初步理解
动态规划求解的大体思想可分为两种:1. 在已知模型的基础之上判断策略的价值函数,并在此基础上寻找最优的策略和最优的价值函数。这种方法我们通常称其为值迭代;2. 或者直接寻找最优策略和最优价值函数,这种方法称为策略迭代。
什么是动态规划
-
动态规划算法,是解决复杂问题的一个方法,将复杂问题分解为子问题,通过求解子问题来得到整个问题的解。
-
在解决子问题的时候,其结果通常需要存储起来,用来解决后续复杂的问题。
什么样的问题,可以考虑使用动态规划来求解
-
一个复杂问题的最优解由数个小问题的最优解构成,可以通过寻找子问题的最优解来得到复杂问题的最优解;
-
子问题在复杂问题内重复出现,使得子问题的解可以被存储起来重复利用。
马尔可夫决策过程(MDP)具有上述两个属性:
贝尔曼方程把问题递归为求解子问题,价值函数就相当于存储了一些子问题的解,可以复用,因此可以使用动态规划来求解MDP。
这一节是整个强化学习内容的核心入门知识点。
如何使用动态规划求解
动态规划算法是用来求解一类被称为规划的问题。规划指的是,在了解整个马尔可夫决策模型的基础上来,求解最优策略。也就是在已知模型结构的基础上(包括状态-动作空间转移概率和奖励函数),求解最优策略。
主要是预测(prediction)和控制(control):
-
Prediction:
预测是指:给定一个MDP和策略
,要求输出基于当前策略
的价值函数。具体的数学描述为:给定一个MDP
和一个策略
,或者给定一个MRP
,要求输出基于当前策略的value function
。
-
Control:
控制是指:给定一个MDP,要求确定最优价值函数和最优策略。给定一个MDP,要求确定最优价值函数和最优策略。具体的数学描述为:输入一个MDP
,输出optimal value function
和 optimal policy
。
策略评估
那迭代法策略评估如何求解呢?策略评估(Policy Evaluation)指的是求解给定的策略下的值函数,也就是预测当前策略下所能拿到的值函数问题。把这个计算当前的状态值函数的过程,称为--策略评估(Policy Evaluation)。解决方案是应用Bellman期望方程进行迭代。
具体方法:在 次迭代中,使用 更新计算 ,其中 是 的后继状态,此种方法通过反复迭代最终将收敛 。
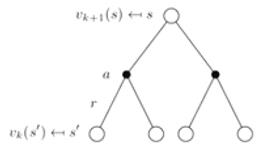
其数学语言描述如下:
用直白一点的语言描述:基于一种策略
,不断地对state value迭代。比如:你当前在清华大学计算机系读博士,你的state-value是什么?是你对以后进入大厂、以后工资、生活条件有一个较好的预期。如上公式所述,当前的state-value是由对后继状态的state-value估计所构成。
或者用策略(Policy)直接与环境互动就可以得到它的值函数,数学表达形式如下:
策略评估步骤
那更具体策略评估(Policy Evaluation)的步骤是什么样子的呢?我们看一下算法伪代码:
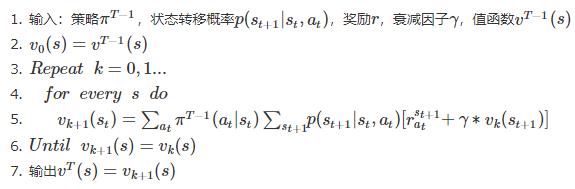
这里就是拿着一个策略一直进行迭代,直到值函数收敛。
策略迭代
策略迭代法(Policy Iteration method)是动态规划中求最优策略的基本方法之一。它借助于动态规划基本方程,交替使用“求值计算”和“策略改进”两个步骤,求出逐次改进的、最终达到或收敛于最优策略的策略序列。
我们发现如果想知道最优的策略,就需要能够准确估计值函数。然而想准确估计值函数,又需要知道最优策略,数字才能够估计准确。所以实际上这是一个“鸡生蛋还是蛋生鸡”的问题。
一般的策略迭代法的思路可总结为以下三个步骤:
-
以某种策略 开始,计算当前策略下的值函数 。 -
利用这个值函数,更新策略,得到 。 -
再用这个策略 继续前行,更新值函数,得到 ,一直到 不在发生变化。
第一步就是上文说的策略评估(Policy Evaluation)
第二步是如何更新策略的呢?
大体思想是在当前策略的基础上,贪婪地选取行为,使得后继状态价值增加最多。Improve the policy by acting greedily with respect to 。
这个计算最优策略的过程,称为--策略提升(Policy Improvement)
策略迭代步骤
那更具体策略迭代法(Policy Iteration method)的步骤是什么样子的呢?我们看一下算法伪代码:
这里是将策略评估(Policy Evaluation)和策略提升 (Policy Improvement)结合起来,进行迭代,直到策略收敛。
策略迭代有点缺点,策略迭代的主要时间都花费在策略评估上,对一个简单的问题来说,在策略评估上花费的时间不算长;但对复杂的问题来说,这个步骤的时间实在有些长。一个最直接的想法就是,我们能不能缩短在策略评估上花的时间呢?有,就是价值迭代
值迭代
理解价值迭代原理的思路,可以从策略迭代的缺点出发。
-
策略迭代的策略评估需要值函数完全收敛才进行策略提升的步骤,能不能对策略评估的要求放低,这样如果可以实现的话,速度会有所提升。
-
我们在策略迭代中关注的是最优的策略,如果说我们找到一种方法,让最优值函数和最优策略同时收敛,那样我们就可以只关注值函数的收敛过程,只要值函数达到最优,那策略也达到最优,值函数没有最优,策略也还没有最优。这样能简化了迭代步骤。
我们的问题是寻找最优策略 ,值迭代的解决方案是:使用贝尔曼最优方程,将策略改进视为值函数的改进,每一步都求取最大的值函数。具体的迭代公式如下所示:
上面这个公式与策略迭代相比,没有等到状态价值收敛才去调整策略,而是随着状态价值的迭代,及时调整策略,这样就大大减少了迭代的次数。
也就是说从初始状态值函数开始同步迭代计算,最终收敛,整个过程中没有遵循任何策略。
上述公式的理解可以参考下面这个推导:
由于策略的调整,我们现在的价值每次更新。倾向于贪婪法寻找到最优策略对应的后续的状态价值。这样收敛的速度会更快。
在值迭代过程中,算法不会给出明确的策略,迭代过程其间得到的价值函数不对应任何策略。
异步动态规划
异步动态规划有几个研究的点:
-
In-place dynamic programming
原位动态规划,所谓的原位动态规划指的是原地更新下一个状态的状态值,而不像同步迭代那样存储新的状态值。在这种情况下,按何种次序更新状态价值有时候会更有意义。
-
Prioritised sweeping
重要状态优先更新,对那些重要的状态优先更新,一般使用td-error(反映的是当前的状态价值与更新后的状态j价值差的绝对值)来确定哪些状态是比较重要的。误差越大越需要优先更新。
-
Real-time dynamic programming
实时动态规划,更新那些仅与个体关系密切的状态。同时使用个体经验来指导更新状态的选择,有些状态理论上存在,但是在现实生活中基本上不会出现,利用已有的现实经验,对于那些个体实际经历过的状态进行价值更新。这样个体经常访问过的状态得到较高品质的更新。个体较少访问的状态,其价值更新的机会就比较少,收敛速度会相对慢一点。
动态规划总结
-
预测问题:就是指在给定策略下,迭代计算价值函数。预测问题的求解主要是通过
Bellman Expectation Equation进行Iterative或者Policy Evaluation。 -
控制问题-策略迭代:是指策略迭代,寻找最优策略问题。在先给定策略,或随机策略下计算状态价值函数,根据状态函数,采用贪婪算法来更新策略,多次反复找到最优策略。主要是通过
Bellman Expectation Equation和Greedy Policy Improvement进行Policy Iteration。 -
控制问题-值迭代:单纯的使用价值策略,全程没有策略参与,也可以获得最优策略。但是我们需要知道状态的转移矩阵。通过
Bellman Optimal Equation进行Value Iteration。
基于state-value function(
)每一次Iteration的 Complexity为
,其中
表示action space,
表示state space。
基于state-action value function (
)每一次Iteration的 Complexity为
,其中
表示action space,
表示state space。
以上是关于终于把动态规划与策略迭代值迭代讲清楚了的主要内容,如果未能解决你的问题,请参考以下文章