第四章 动态规划:理论
Posted 人工智能之强化学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四章 动态规划:理论相关的知识,希望对你有一定的参考价值。
上一章介绍了强化学习的数学模型-马尔科夫决策过程,接下来介绍求解强化学习的几种方法,这一章先来介绍有模型情况下的求解方法-动态规划。文章分为四个部分:什么是动态规划、为什么要用动态规划、有哪些动态规划算法、如何使用。
一 什么是动态规划
动态规划:是一种通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。每次决策都依赖于当前状态, 又随即引起状态转移。一个决策序列就是在变化的状态中产生出来的, 所以, 这种多阶段的最优化决策解决问题的过程就称为动态规划(DP)。
能采用动态规划求解的问题的一般要具有3 个性质:
最优原理: 如果问题最优解所包含的子问题的解也是最优的, 那么就称该问题具有最优子结构, 即满足最优化原理。
无后效性: 即某阶段状态一旦确定, 之后下一个阶段状态的求解就不受这个状态以后决策的影响。
具有重叠子问题性质: 即子问题之间是不独立的,一个子问题在某一阶段决策中可能被多次使用到。(该性质并不是DP算法适用的必要条件, 但如果没有这条性质, DP算法与其他算法相比就不具备优势)DP算法将原来具有指数级时间复杂度的搜索算法改进优化成了具有多项式时间复杂度的算法。其中关键在于解决数据的冗余, 这是DP算法的根本目的与精髓。DP算法实质上是一种以空间换时间的技术, 它在实现的过程中, 不得不存储产生过程中的各种状态, 所以它的空间复杂度要大于其它的算法。
二 为什么要用动态规划
动态规划和强化学习的关系可以从贝尔曼方程中得到:
首先,马尔可夫决策过程满足上述性质:
贝尔曼方程提供了递归分解的结构;
价值函数可以保存和重复使用递归时的结果。
其次,从这个式子看出,可以定义出子问题求解每个状态的状态价值函数,同时这个式子又是一个递推的式子, 意味着利用它,我们可以使用上一个迭代周期内的状态价值来计算更新当前迭代周期某状态s的状态价值。意味着可以使用动态规划问题解决马尔科夫决策模型。
可见,使用动态规划来求解强化学习问题是比较自然的。
三 有哪些动态规划算法
如图所示,动态规划包含同步动态规划和异步动态规划
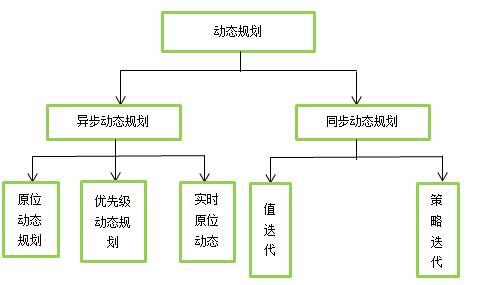
异步动态规划算法:每一次迭代并不对所有状态的价值进行更新,而是依据一定的原则有选择性的更新部分状态的价值。常见的异步动态规划算法有三种。
第一种是原位动态规划,不会另外保存一份上一轮计算出的状态价值。而是即时计算即时更新。这样可以减少保存的状态价值的数量,节约内存。代价是收敛速度可能稍慢。
第二种是优先级动态规划,该算法对每一个状态进行优先级分级,优先级越高的状态其状态价值优先得到更新。通常使用贝尔曼误差来评估状态的优先级,贝尔曼误差即新状态价值与前次计算得到的状态价值差的绝对值。这样可以加快收敛速度,代价是需要维护一个优先级队列。
第三种是实时动态规划,实时动态规划直接使用个体与环境交互产生的实际经历来更新状态价值,对于那些个体实际经历过的状态进行价值更新。这样个体经常访问过的状态将得到较高频次的价值更新,而与个体关系不密切、个体较少访问到的状态其价值得到更新的机会就较少。收敛速度可能稍慢。
同步动态规划算法:每轮迭代会计算出所有的状态价值并保存起来,在下一轮中,使用这些保存起来的状态价值来计算新一轮的状态价值。本文主要讲述这种动态规划算法。
四 如何使用
同步动态规划包含两种方法:一个是值迭代,另一个是策略迭代。不论是值迭代还是策略迭代都有两个步骤:策略评估、策略改进。
(1)值迭代
策略评估
当模型已知时,策略的评估问题转化为一种动态规划问题,即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,再求解每个状态的两步累积奖赏,一直迭代逐步求解出每个状态的T步累积奖赏。
每次迭代过程中,用所有状态s的第k次迭代得到的 来计算第k+1次的
来计算第k+1次的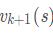 的值。经过这种方法的反复迭代,最终是可以收敛到最优的 。迭代的公式如下:
的值。经过这种方法的反复迭代,最终是可以收敛到最优的 。迭代的公式如下:

该方法的前提是策略π从一开始就没有改变(如一直保持随机策略),只是通过不断地迭代计算 的值,直到最后 收敛才停止迭代。
策略改进
我们的目标是要得到最优策略,所以在迭代到V值收敛后,我们可以进行策略改进(策略 π 表示在一个状态s下,agent接下来可能会采取的任意一个action的概率分布)。可以使用贪婪算法(在每一步总是做出在当前看来是最好的选择)来进行策略改进,将策略选择的动作改为当前最优的动作。即:

上述过程就是从最优化值函数的角度出发,即先迭代收敛得到最优值函数,再来计算如何改进策略,这便是值迭代算法
(2)策略迭代
如果说值迭代是发现最优策略,那么策略迭代则是如何提高一个策略性能
策略迭代和上面的值迭代不同就在于,策略评估与策略改进不是分隔开的,而是反复交替的。
给定一个策略π:
策略评估:在当前的策略下计算
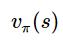 的值:
的值:
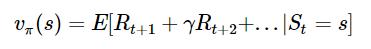
策略改进:利用策略评估得到的
来通过贪婪算法进行策略改进:
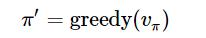
然后继续重复策略评估、策略改进,直到最后收敛到最优策略。
总结
值迭代是一开始不改变策略,一直迭代计算
的值,直到最后
收敛得到最优值函数,这时候再根据贪婪算法改进策略;
策略迭代则是每计算一次 的值,就改进一次策略,然后利用改进的策略再继续计算 的值,不断迭代直到策略收敛,策略迭代在每次改进策略后都要对策略进行重新评估。
以上是关于第四章 动态规划:理论的主要内容,如果未能解决你的问题,请参考以下文章