动态规划算法梳理(上)
Posted 清世传习录
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动态规划算法梳理(上)相关的知识,希望对你有一定的参考价值。
起源、定义与来自学院派的第一个例子
上世纪五十年代,美国科学家贝尔曼受雇为兰德公司做事。贝尔曼更想做点偏向于应用数学相关的研究,但是毕竟他不是给高校研究所工作(“公司养你是为了让你赚钱的好吗”),于是想了想,不如起一个骗骗外行的名字好了(放到现在也能考虑搞个“红芯”啊、新能源汽车什么的赚钱吧),于是就叫它开发的这种算法"dynamic programming”,国内现在通译作“动态规划”。
网上说了一大堆相关的内容,都有些不着边际,这样起名的主要含义,ucsd的教授用一段话说的很明白:
在贝尔曼的年代(上世纪五十年代),“programming”(现在我们往往把它理解作“编程”)一般只是被理解为“planning”,也就是做计划,而我们理解的”computer programming”(电脑编程)在当时还是一门很神秘的学科,极少有人研究相关的内容,因而也没有人给这样的行为起名字。
因此,dynamic programming当时只是用于表示这样的意思:最优地计划多阶段的过程(optimally plan multi-stage processes)。
有了上面这段引子,引用一下维基百科的定义可能就有助于理解了:(如果还是不理解,可以直接全部跳过本节,先看后文如何引入,最后再看定义;定义就像是一个“谜语”一样——知道谜底的人,才能对谜语记忆的更加深刻)
一种常用于数学、管理学、计算机科学、经济学和生物信息学的方法,通过把原问题分解为相对简单的子问题来求解复杂问题的方法。
对于算法问题,分治法、图算法、贪心算法,针对特定问题可能有一定好处;但是对于一些更为一般的问题,使用dynamic programming 有时可以发挥更好的效果。正如波利亚在《如何解题》中告诉我们的:解决一个更一般的问题,有时并不一定比解决一个更具体的问题更困难。(其实现代科学体系中的很多问题和学科,都是这样诞生的)
虽然学院派的坏处是有点晦涩,好处是理解之后,对问题的理解的层次与抽象度会好很多。与以往的过度通俗的讲法不同的是,ucsd教授的理解是:我们可以把动态规划问题看作一个已经被按照线性顺序拓扑排序之后的“有向无环图”(不会的话,请复习一下图论,或者干脆无视这段定义,我们将在下文以更轻松的方法引出这个问题)。
于是他是这样对动态规划问题下定义的:动态规划是一种高效的算法范式:在这个范式中,一个问题是如此被解决的:对于一个大问题,首先定义一个子问题的合集(并隐式地把它们视为一个连接的有向无环图,英文简写作DAG),然后按如下顺序一个接一个解决他们:先解决小问题,然后用已经解决的小问题的答案来帮助算出更大的问题的答案,直到所有的子问题被解决。(如果解决问题B要让我们用到问题A的答案,那么我们可以隐式地生成一个从A到B的“(概念性的)边”,这样,我们也可以根据这样的边,对包含A、B在内的所有子问题进行一个排序)
. 学院派的例子--最长上升子序列(longest increasing subsequences)
本题也是leetcode 300,更多的实例可以从那里找到。
给定一个普通的数组 ,一个子序列指的是按增序取出的部分数字,以 为形式,其中 的形式出现。一个上升子序列指的是其中数字都是递增的子序列。
举个例子,对于一个序列5, 2, 8, 6, 3, 6, 9, 7;2, 3, 6, 9就是一个上升子序列,且正好也是最长的上升子序列:
实际上,对于这个例子,全部的上升子序列都是可以用图G = (V, E)的形式表达出来的:

因而,不难根据数组的索引(index)对其进行定义,顶点就是每个数字,边就是存在的上升序列的路径。设L(j)是第j个元素处拥有的最长序列的长度。根据定义,可以找到这个函数的关系,也就是这样一个递推公式:

这样的关系就是说,如果存在从i到j的路径,那么j的最大路径长度应该至少等于从i的最大路径长度加一(i是不唯一的,所以j从中取一个最大值)。
核心的伪代码是这样的:
于是问题重新变为以下的算法:
1for j = 1, 2, ... , n:
2 L[j] = 1 + max{L[i] : (i, j) belongs to E}
3return max_i L[i]
根据这样的关系,写出java代码还是不难的:
1class Solution {
2 public int lengthOfLIS(int[] nums) {
3 if(nums == null || nums.length == 0) return 0;
4 // 初始化
5 int[] dp = new int[nums.length];
6 Arrays.fill(dp, 1);
7 for(int i = 0; i < nums.length; i++){
8 for(int j = i + 1; j < nums.length; j++){
9 if(nums[j] > nums[i]){
10 // 如果存在路径,套用上述公式
11 dp[j] = Math.max(dp[j], 1 + dp[i]);
12 }
13 }
14 }
15 // 从保存的结果中找最大值
16 int max = 0;
17 for(int num : dp){
18 max = Math.max(max, num);
19 }
20 return max;
21 }
22}
. 学院派例子的进一步分析——原理的归纳
上述的题目并不算很复杂,但是抽象出的关系并不是题目这么简单,作者从中提炼出了满足动态规划需求的一类问题的性质:
只要能找到这样一组子问题的集合{L(j) : 1 <= j <= n},且集合满足以下性质D:
子问题集合存在一个序(ordering),且存在一个关系来展示如何从一些“更小的”子问题(也可以认为是按序在当前问题之前的那些子问题)来解决一个新的子问题。
There is an ordering on the subproblems, and a relation that shows how to solve a subproblem given the answers to “smaller” subproblems, that is, subproblems that appear earlier in the ordering.
那么,借助动态规划,这个问题可以只通过一次遍历(one-pass)就可解决。
其实也不复杂,比如说,对于一个长度为5的序列,就可以画出类似于下面的递归树:

如果我们从下向上看这张图,有了1就可以求出2,有了2就可以求出3,…,颇有一种“道生一,一生二,二生三,三生万物”的意思了。
当然,动态规划的意思绝不是让人去递归,那样维数就爆炸了,ucsd的作者也在书中用了“Recursion, No thanks”(递归?免了吧!/递归?不了不了,这伤身体)这样的标题来讽刺这样的想法。
在动态规划类问题中,如果还使用递归,往往会使得问题指数爆炸,即使使用memorization(记忆化搜索)方法,也要浪费保存的空间以及压栈弹栈的时间,所以不推荐,最好还是使用tabulation(自下而上)的方法。
那么,为什么在divide-and-conquer(分治法)中,使用递归来表达子问题可以接受呢?主要因为分治法中,子问题通常是表达为原问题更小规模的问题,往往来说是n/2的大小,由于问题规模迅速减小,递归树深度往往只有logn级别,节点数依旧在polynomial(多项式)个,可以接受。
相比之下,动态规划类问题,往往子问题的大小是O(n - 1),几乎没有减少,会导致问题几乎变大了,深度变成O(n),而节点个数达到了exponential(指数)个,这就往往不可接受了。
根据上述的分析,我们可以归纳出动态规划的主要适用范围,即需要满足以下三个条件:(还是同理,不建议死记硬背,理解后能有所感悟就好)
最优子结构:如果问题的最优解包含的子结构也是最优,那么这就提供了一个很重要的线索。(譬如修身、齐家、治国、平天下——中国人的政治最优)
无后效性:子问题的解一旦确定,则不再改变,与更大问题的求解无关
子问题重叠性质:指的是用递归算法自顶向下对问题进行求解时,每次产生的子问题不影响新问题,因此可以将子问题保存在表格中,当需要再次计算子问题时,可直接查询结果。
告别学院派——简单粗暴引出记忆化搜索与动态规划
学院派的特点就是:抽象、归纳、推理、分析,从而有可能通过严密的分析更好地求得最优、更好地处理边界条件、抽象出一般的公理以推广到其他问题上等等。不过的确对于一般的工程人员来说,“扯那么多有什么用呢“?这一节我们将直接以更直观更注重解题的方法引出动态规划的理论。
. 从斐波那契数列引出必要内容
斐波那契数列可以说是大家从初中甚至小学就耳熟能详的东西了(什么?你说你不知道?那你赶紧回去给你以前的数学老师道歉吧,马上!),对于它的求法,最简单最暴力的就是用递归写法了:
用最暴力的递归计算,递归树如下:
1public int fib(int N) {
2 if (N == 0 || N == 1) return 1;
3 return fib(N - 1) + fib(N - 2);
4}
这样写的话,会出现一层一层的递归,如果替它画一个递归树,可能就是这样的(以n = 10为例):
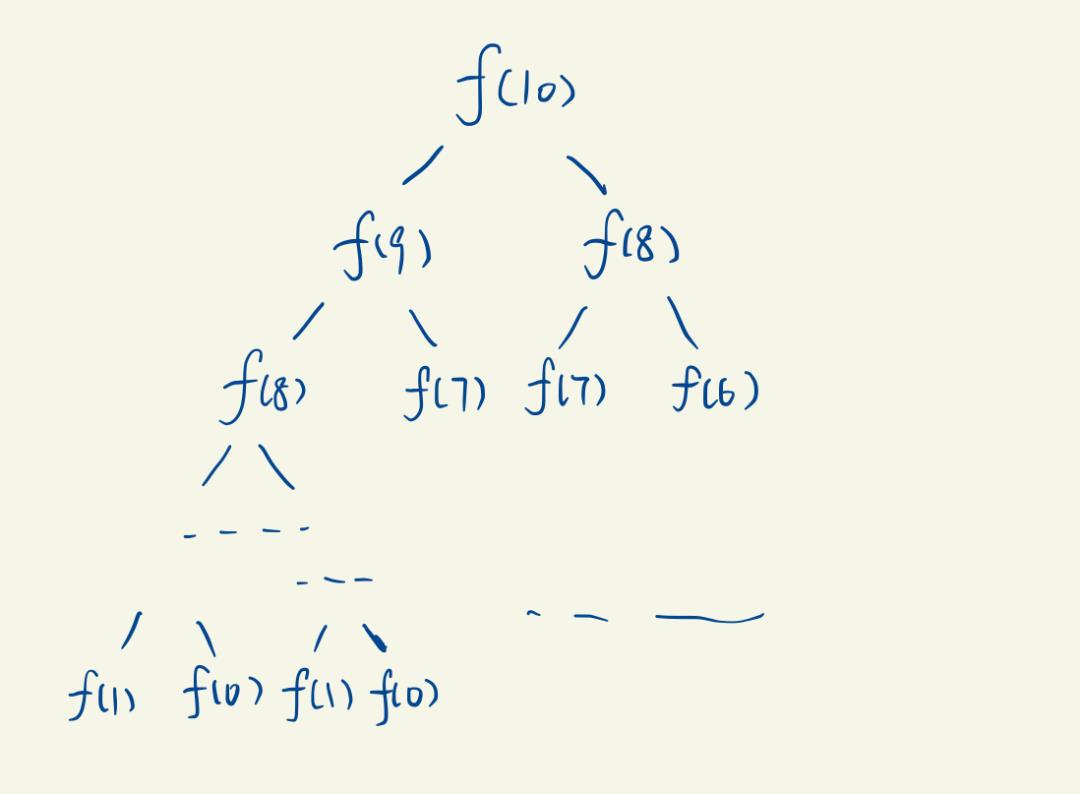
这张图展示出了这种递归暴力求法的时间复杂度,是O(2^n),要知道,int型变量最多也就保存2的32次方个数字,像这样计算,时间空间的负担都是很大的。
它的问题在哪呢?
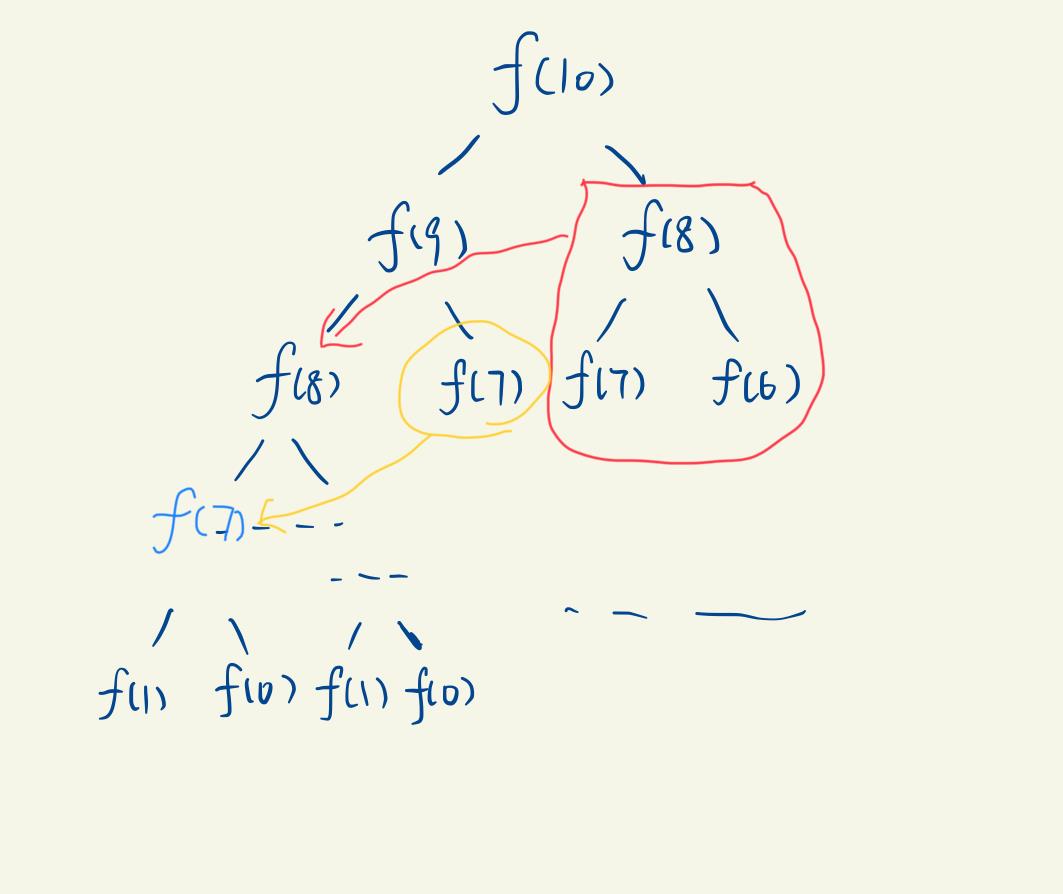
其实我们在算f(9)的时候,早就把f(8),甚至f(7)等等都算过了,但是算完了只用于计算了f(9),没有保存相应的结果,因而在算递归树第二第三层的f(8)、f(7)时,又得重新进入递归。
一个合理的办法就是用某种数据结构来保存相关的结果,这就是所谓的记忆化搜索了:
1class Solution {
2 // 用于保存计算之后的结果
3 HashMap<Integer,Integer> cache = new HashMap();
4 public int fib(int N) {
5 if(N == 0 || N == 1){
6 return N;
7 }
8 // 如果已经保存,直接读取保存的结果
9 if(cache.containsKey(N)){
10 return cache.get(N);
11 }
12 // 如果没有保存,计算并保存
13 int result = fib(N - 1) + fib(N - 2);
14 if(!cache.containsKey(N)){
15 cache.put(N,result);
16 }
17 return result;
18 }
19}
当然,这个例子里,我们用的是hashmap来进行保存,实际上倒也不用这么复杂,由于保存的内容是有规律的,直接用一个数组进行保存也是可以的。(相当于hash函数是自己设计的,调用hashmap相当于让数据结构本身代替完成hash函数的设计)
所以记忆化搜索完成的计算就是一个”自上而下“的计算,

从中我们可以找到规律:每个数字仅仅依赖其前面的两个数字,那么一旦给定了f(0)跟f(1),我们完全可以反过来把所有的数字算出来(其实我们中学也是这么算的就是了):
这就是一个典型的动态规划了,如果把这个过程用数组来储存,那么代码就是这样的:
1public int fib(int N){
2 int[] dp = new int[N];
3 dp[0] = dp[1] = 1;
4 for(int i = 2; i <= N; i++){
5 dp[i] = dp[i - 2] + dp[i - 1];
6 }
7 return dp[N - 1];
8}
动态规划“自底而上”:先解决规模最小的问题,然后再向大问题归并,因此,动态规划脱离了递归,往往靠迭代循环完成计算。
当然,斐波拉契数列问题实际上还能进一步优化,因为f(n) = f(n - 1) + f(n - 2),所以实际上只需要保存前两个结果即可:
1public int fib(int N){
2 if(N == 0 || N == 1) return 1;
3 int prev = 1, curr = 1;
4 for(int i = 2; i <= N; i++){
5 int sum = curr + prev;
6 prev = curr;
7 curr = sum;
8 }
9 return curr;
10}
由此我们可以总结出动态规划的必要的四个步骤:
明确问题中的”状态“(也就是不同的情况、子问题:在本题中就是可以分解为f(0), f(1),f(2), …, f(n))
定义dp数组的含义
明确下一步是如何通过处理之前的结果获得的(也就是理清公式、关系)
确定并初始化一些情况,即所谓的base case(比如说本题中的f(0)与f(1),都是初始条件,不能直接用公式推得)
利用这样的想法,解决leetcode 198也是很容易的:
这一题不要想太复杂,简单利用数学归纳法来推理就行了:n = 1, n = 2是base case,从n = 3开始即可归纳出公式:
1class Solution {
2 public int rob(int[] nums) {
3 // f(k) = max{f(k - 2) + nums[k], f(k - 1)}
4 if(nums == null || nums.length == 0) return 0;
5 if(nums.length == 1) return nums[0];
6 if(nums.length == 2) return Math.max(nums[0], nums[1]);
7 int[] dp = new int[nums.length];
8 dp[0] = nums[0];
9 dp[1] = Math.max(nums[0], nums[1]);
10 for(int i = 2; i < nums.length; i++){
11 dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
12 }
13 return dp[nums.length - 1];
14 }
15}
不过,实际上本题只保留了最近的两个结果,实际上也可以类似地做一点优化,代码这里就不贴了,有兴趣的朋友自己可以试试看。
不知不觉又写了不少了,虽然想表述的内容还有很多,不过姑且做这样的介绍吧,下一篇文章,我们将结合更多的例题分别从简单粗暴的实用角度与学院派的角度做出更多的解读。
以上是关于动态规划算法梳理(上)的主要内容,如果未能解决你的问题,请参考以下文章
详细实例说明+典型案例实现 对动态规划法进行全面分析 | C++