强化学习入门系列二:从贝尔曼方程到动态规划
Posted 三岁学技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习入门系列二:从贝尔曼方程到动态规划相关的知识,希望对你有一定的参考价值。
"在看"和“关注”都是满满的爱!
前文讲到了贝尔曼方程,本节继续深入,从贝尔曼方程开始介绍动态规划。回顾一下上一节的内容。上一节主要介绍了马尔科夫链、马尔科夫决策过程、数学期望和贝尔曼方程。再看一下这几幅图:
马尔科夫链
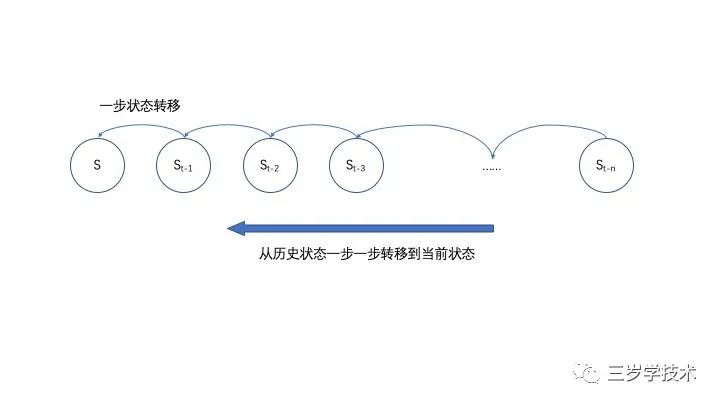
如图所示,当前状态是S,它的右边有历史状态,从
一步一步移动过来,每一次的状态转移,都只和前一次的状态相关,而跟历史上其他状态无关。当然,每一次状态的转移都有一个概率,称之为状态转移概率。基于这种结构搞决策,就是马尔科夫决策过程。在此基础上,如果每一个状态都会得到相应的“奖励”R,就可以给出数学期望:
数学期望
其中E就是数学期望,等式右边R就是奖励,p就是状态转移概率。这个公式的含义就是在表达由于状态转移而得到的回报的一个“均值”。当然,这是概率均值,不同于普通的算术平均值。在此基础上我们就给出了贝尔曼方程:
贝尔曼方程
这个公式中V就是状态s下的一个数学期望,也就是预期中得到奖励的一个概率均值。等式的右边E就是表达这个概率均值。R就是奖励。值得注意的是,这个公式表达的是一个递推关系,当前状态下“预期奖励”,也取决于下一个状态下的“预期奖励”V(st+1)。层层递进,才能累加出最后的总奖励。
上面的等式中,对于未来的预期过于完美,所以,就给未来的预期加上一个“折扣因子”,于是有了下面的式子:
等式中原理和含义跟贝尔曼方程没有区别。但是加上了γ这个折扣因子,用来给未来的预期打折。我们还提到,虽然这个“折扣因子”通常是0~1的一个实数,但是有的时候为了夸大未来的预期,也可以取大于1的实数,用来表达未来的回报会很多。
到这里,就可以开始这一节的内容。先要把贝尔曼方程进一步细化一下,引入“动作”这个概念。
动作,Action
这个概念不复杂,就是在某一个状态S下,采取什么样的动作。比如狗狗接飞盘的例子,狗狗可以往右走,也可以往左走,还可以原地不动等等,都是动作(Action)。于是,可以用q(s,a)来表达s状态下采取动作a的回报。那么贝尔曼方程就可以改写成以下的样子:
上面的等式中把贝尔曼方程中的回报值V换成了一个q。区别就是q不单单取决于当前的状态,而且还取决于在当前状态下的一个“动作”a。这也就是说,狗狗接飞盘再也不是随机的采取任何一种动作,而是明确的选择动作空间A中的某一种动作a。E还是数学期望,R还是奖励,γ还是折扣因子。回顾一下狗狗接飞盘的图:
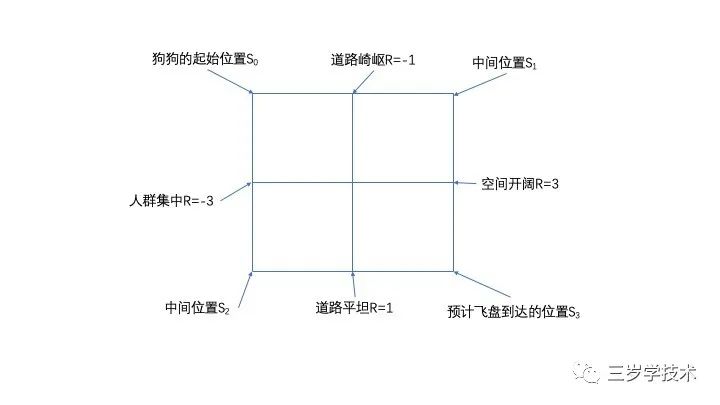
上图中,如果狗狗在起始位置,那么它在看到飞盘飞出以后,可以选择从道路崎岖的一边去接飞盘,也可以从人群集中的一边穿过去。这就是状态S0下的两个动作a。
而选择其中任何一个动作,都会有一个概率,也就是机会,可以记作π(a|s),意思就是状态s下的动作a的概率。把这个东西放进贝尔曼方程又有了新花样:
这个公式强行加入了一个π,和前面的贝尔曼方程中的V(s)以示区别。但是它的含义并不复杂,就是给状态s下面的每一个动作a记录了一个概率。因为有很多种动作,那么就再求一个和。
拿上面的狗狗接飞盘的图做一个说明,每一次狗狗从起始位置看到飞盘以后,都可以选择一个动作a,然后,由于这个动作,又会把狗狗带到下一个状态。比如,处在崎岖的道路上,或者穿行在拥挤的人潮中等等。而这些状态又会给狗狗带来不同的奖励。如果总体评估这个奖励的大小,把上面带有π的贝尔曼方程给展开,就有:
这个公式有一点点小挑战。不过意义很明确,等式左边就是描述在当前状态s下采取所有a的一个“预期回报”。右边,R表示马上可以得到的奖励,p表示一个转移概率,因为从当前状态s到下一个状态s’有可能有很多种转移的方法,就累加起来。π仍然表达状态s下采取动作a的一个概率,q代表递推,也就是下一个状态开始,所能得到的“预期回报”。最后,给所有的“预期回报”乘以一个“折扣因子”γ,就是这个公式的含义。各位看官不禁要问,弄出来这么一个复杂的公式是干什么?因为要选择最优的动作,转移去最好的状态,也就是要优化贝尔曼方程,求得最大“预期回报”。
优化
优化的方法,从数学上表达虽然十分麻烦,可是道理很简单:因为有了贝尔曼方程,在狗狗接飞盘的游戏中,每一次完成游戏,不管成功失败,都可以给中间状态和中间动作求一个“预期回报”。这样,在下一次狗狗接飞盘的训练之中,就可以选择“预期回报”大的那个。重复进行这个过程,狗狗逐渐会尝试每一条道路,每一个动作,不断选取“预期回报”更大的那个,这就是“优化”。每一次优化,又更新了贝尔曼方程的值,从而利于下一次优化。这个过程持续进行,直到没有什么优化空间的时候,就可以停下来了。
这个过程,也正是简单的强化学习的训练过程。强化学习可以采取的具体训练方法有不少,下面我们就介绍一个比较常见的:
动态规划
不论是在学校的教科书里面,还是在企业的面试里面,这几个字一出来,都会吓倒一片人。为了介绍的容易一点,先把狗狗接飞盘的那个地图简化一下:
上图所示,把狗狗接飞盘的游戏场景简化到了四个状态,分别是起始位置S0,崎岖道路S1,人群拥挤S2,终点S3。狗狗可以选择通过某一条道路到达终点,也可以掉头回来重新选择。每一次选择都会有一个奖励,这个奖励可以是正的,也可以是负的。一旦抵达终点,就不再移动。套用前文讲过的贝尔曼公式,我们可以轻松的计算某一个节点的“预期奖励”。
这里为了简单起见,“折扣因子”γ可以设定成为1,便于理解;同时也可以设定每一次选择道路时,左右两面的选择概率都是0.5。于是就可以有这么几个计算方法:
上面这个方程组想要解开,并不困难。这样就可以得到最终的V(s)在各个状态下的“预期奖励”。
那么问题来了,对于真实的情况,真的可以有这样一组方程可以解吗?虽然是有,可是也许非常的多,可能需要几百万个方程,同时对应几百万个未知数。这解起来就非常划不来,甚至是计算机也很吃力的事情了。比如,自动驾驶的汽车,想要学会在城市里面开车的技能,恐怕会遇到无穷多种情况,也就有无穷多个状态,意味着无穷多个方程。解起来就变成了不可能,那么怎么办呢?
迭代
对,答案就是试一试。虽然无法一次求解无穷多组贝尔曼方程,但是可以不停的尝试猜出来解,只要非常接近真实答案,那么也就达到了要求,没有必要去精确求解了。这个过程就叫做迭代求解。下面我们来猜一猜上面的那个图里面的V(s)。
因为贝尔曼方程是基于马尔科夫链来的,都是递推方程,也就是说某一个状态,跟上面一个状态的值相关。所以,从结果层层追回其实位置,就要求所有的状态必须有一个初始的值,不然就追不到尽头了。那么也很简单,就设置所有的状态初始的值都是0就可以了,就这么简单。于是有下面的一个猜测过程:
第一次猜测V(s0):
第一次猜测V(s1):
第一次猜测V(s2):
按照上面的方法一次一次的猜下去,最终就会逼近几个状态的真实解。真实解实际上是:
这种具体的迭代法也就是一种动态规划了。意思即是,无法一次求得通解,但是可以在动态的迭代过程中不断地调整值,逐渐逼近真实的解,最后就算无法得到真实的解,也可以加足够逼近的时候停下。而足够逼近真实解的时候,可能每一次迭代的时候解的变化就不大了,这种现象就可以作为一种停止迭代的标志。
本节讲述了贝尔曼方程包括动作a的情况,同时,又由此进而讲解了动态规划的入门操作——迭代。那么后文,我们将一起来编写代码,实现动态规划的一些算法。
"在看"和“关注”都是满满的爱!
以上是关于强化学习入门系列二:从贝尔曼方程到动态规划的主要内容,如果未能解决你的问题,请参考以下文章