R语言一键生成好看的Table 1?小白也能十分钟之内搞定!
Posted 挑圈联靠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言一键生成好看的Table 1?小白也能十分钟之内搞定!相关的知识,希望对你有一定的参考价值。
扫描下方二维码免费领取☟☟☟
大家好,我 是 阿琛。谈统计 而色变, 不知道你还记得那些年学过的统计知识吗?从 变量类型 ,到 统计描述 ,以及 假设检验 。 一 串 一串的概念,初识之时以为大家不过萍水相逢,考试过后也便自然向往于江湖。 然而,当打开SCI论文,无论是生信研究,亦或者是临床或基础研究,那熟悉的Table 1让人又爱又恨。下面,让阿琛带大家一起温故而知新,讲述一下这Table 1制作的过往历程。
SPSS经典分析方法回顾
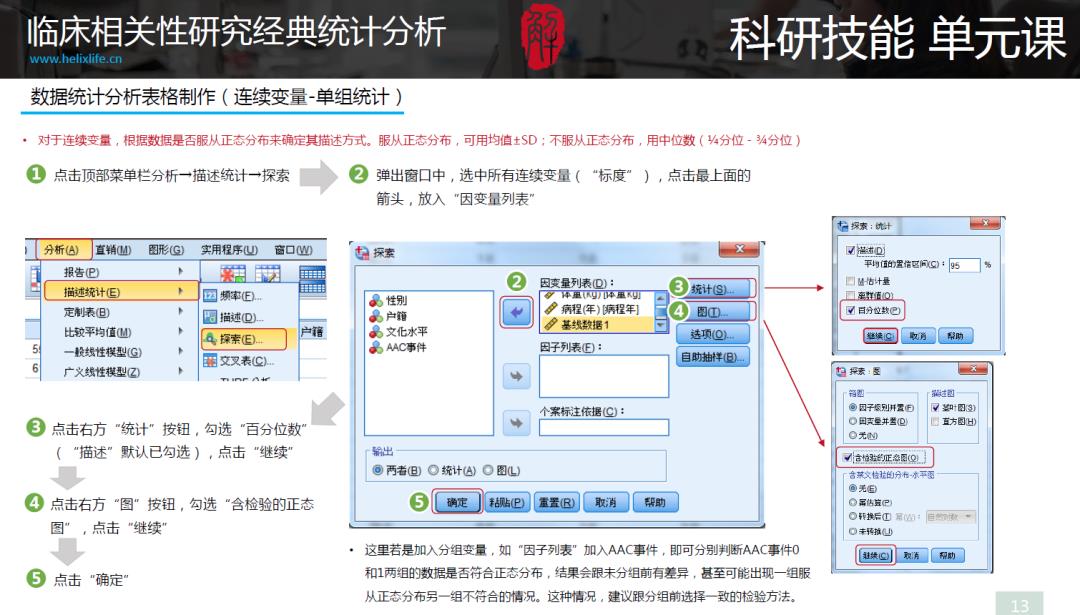
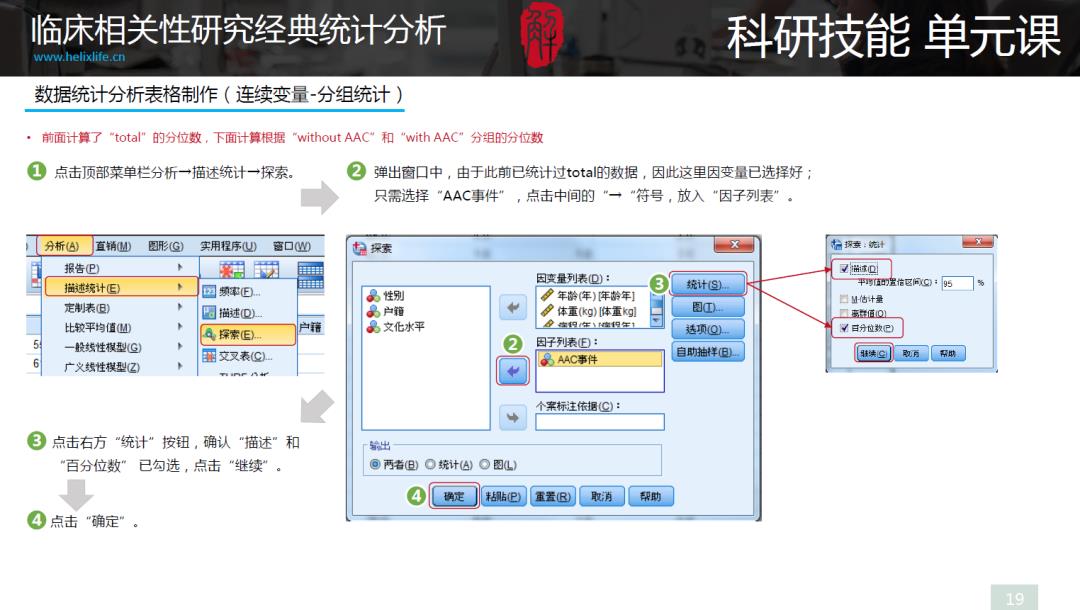
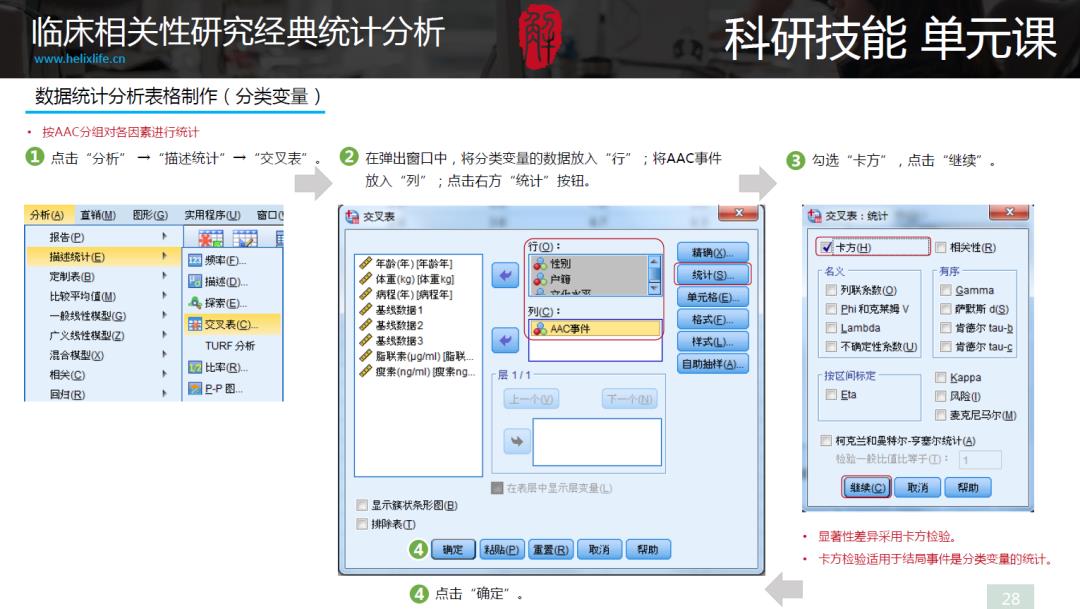
R绘制Table1方法
1
install.packages("tableone")library(tableone)
2
setwd("C:\Users\000\Desktop\Table") #设置工作目录rt <- read.table("clinical.txt",header=T,sep=" ",row.names=1) #读取表格head(rt) #查看数据结果
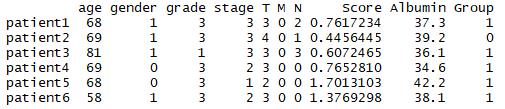
3
tab1 <- CreateTableOne(data = rt) #指定数据来源print(tab1) #查看tab1
4
#4.1 设置需要比较的变量名称myVars <- c("age", "gender", "grade", "stage", "T", "M", "N", "Score", "Albumin")#4.2 设置分类变量catVars <- c("gender", "grade", "stage", "T", "M", "N")#4.3 设置非正态分布的变量nonVars <- c("Score")
5
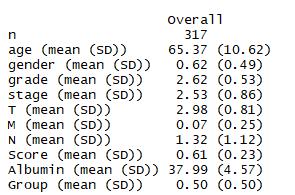
tab2 <-CreateTableOne(data =rt, #指定分析数据集vars = myVars, #指定比较的变量factorVars = catVars) #指定其中的分类变量print(tab2,nonnormal = nonVars) #指定非正态分布变量
-
结果显示:

6
tab3 <- CreateTableOne(data = rt,strata = "Group", #指定分组变量vars = myVars,factorVars = catVars)print(tab3,cramVars = catVars,nonnormal = nonVars,exact = "M") #指定进行fisher精确检验
主要是继续参考每个nmf类里面的不同signature的比例,已经不同nmf类的相关性热图
可视化是一条永无止境的路。大家加油哈!

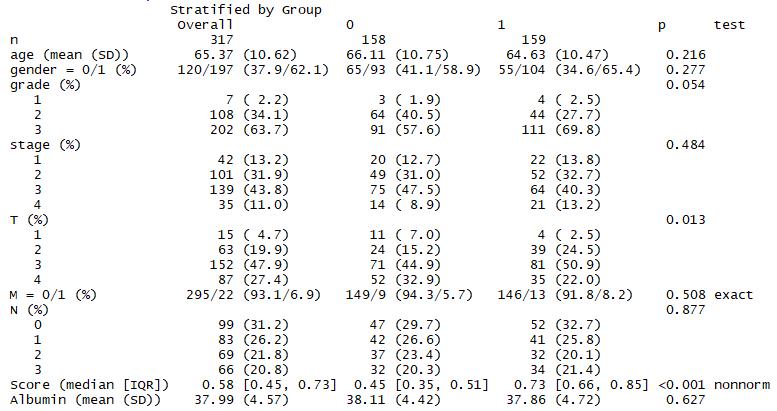
tab4 <- CreateTableOne(data = rt,strata = "Group", #指定分组变量vars = myVars,factorVars = catVars,addOverall = TRUE) #添加Overall列的分析结果print(tab4,cramVars = catVars,nonnormal = nonVars,exact = "M") #查看tab4
7
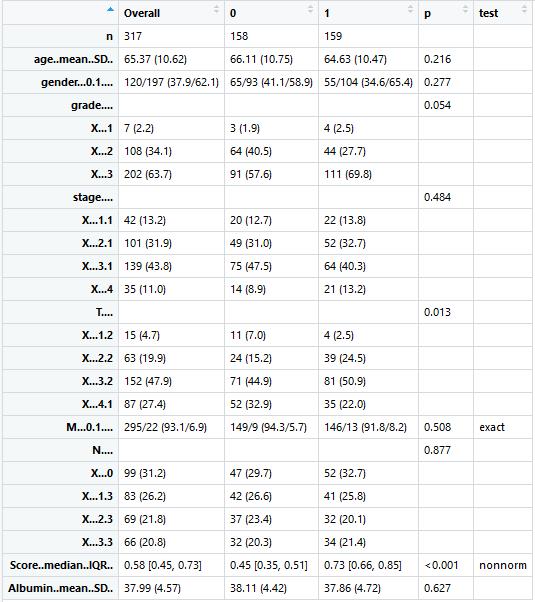
print(tab4,cramVars = catVars,nonnormal = nonVars,exact = "M",quote = TRUE, #显示引号noSpaces = TRUE) #删除空格

tab5 <- print(tab4,cramVars = catVars,nonnormal = nonVars,exact = "M",quote = FALSE, #不显示引号noSpaces = TRUE,printToggle = FALSE)write.csv(tab5, file = "TABLE1.csv")

以上是关于R语言一键生成好看的Table 1?小白也能十分钟之内搞定!的主要内容,如果未能解决你的问题,请参考以下文章
黑科技 | 人工智能降噪清晰神器来了!小白也能轻松一键操作!
R语言data.table导入数据实战:data.table生成新的数据列(基于已有数据列)生成多个数据列
R语言中三线表是什么?使用table1包绘制(生成)三线表实战
全网最详细中英文ChatGPT-GPT-4示例文档-步骤指示智能生成从0到1快速入门——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)