对照着Excel入门R语言表格数据处理
Posted 基迪奥生物
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对照着Excel入门R语言表格数据处理相关的知识,希望对你有一定的参考价值。
#在线安装dplyr包;
#install.packages("dplyr")
#载入dplyr包;
library(dplyr)
#改变工作目录
setwd("C:/Users/MHY/Desktop/数据的分类汇总统计")
dir()
#读入范例数据,为了方便展示数据仅15行;
dt <- read.table("Excel小技巧范例数据1.txt",header=T,sep=" ")
dt这一部分对应Excel“开始”选项卡下的排序功能,Excel也可以实现多变量排序,如下。
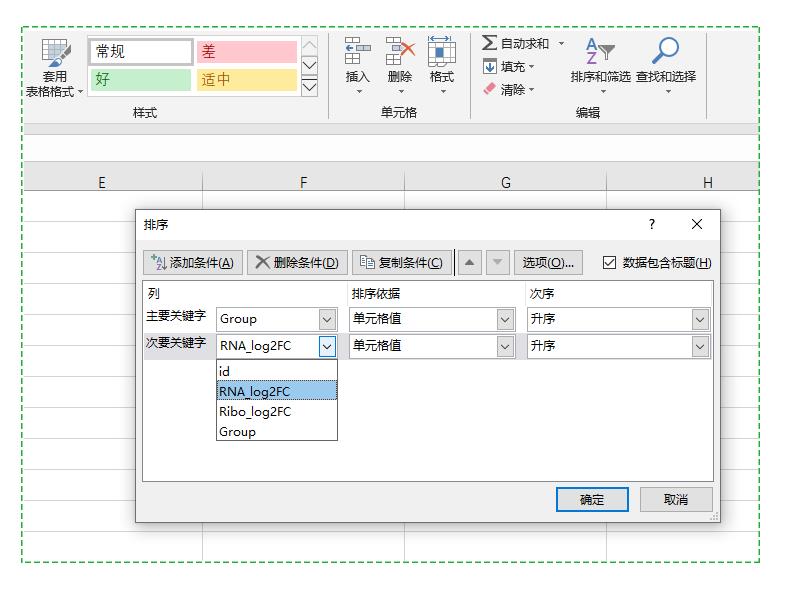
#按照单个变量排序,默认升序排列;
by_id <- arrange(dt,id)
#通过嵌套desc()函数实现降序排列;
by_RNA <- arrange(dt,desc(RNA_log2FC))
#可以按照多个变量排序;
by_Group_RNA1 <- arrange(dt,Group,desc(RNA_log2FC))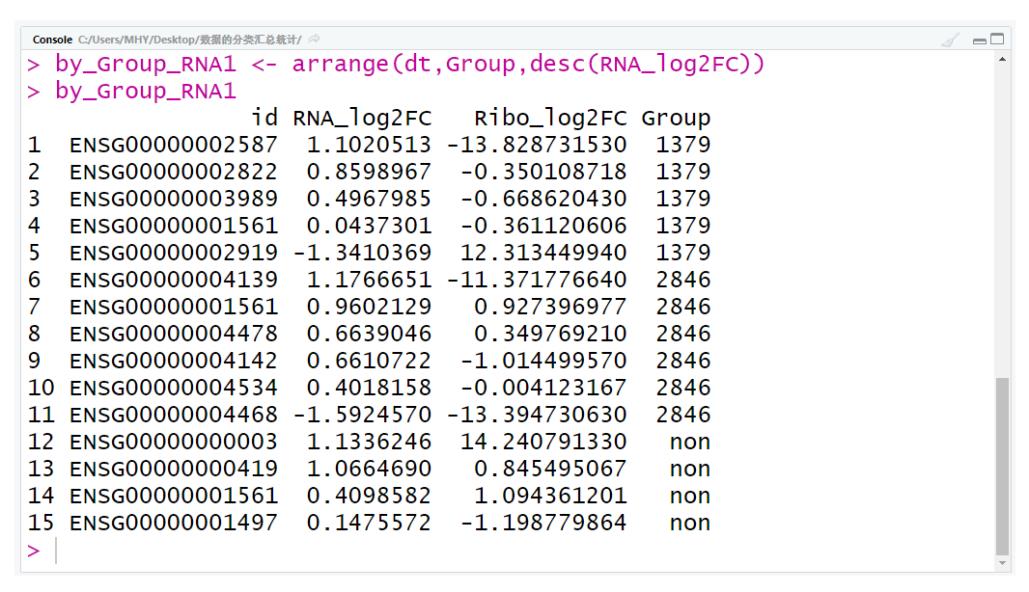
#组内排序;
tbl <- group_by(dt,Group)
by_Group_RNA2 <- arrange(tbl,desc(RNA_log2FC),.by_group = TRUE)
#也可配合管道符号 %>%,简化脚本,本质就是省略输入变量;
by_Group_RNA3 <- dt %>% group_by(Group) %>% arrange(desc(RNA_log2FC),.by_group = TRUE)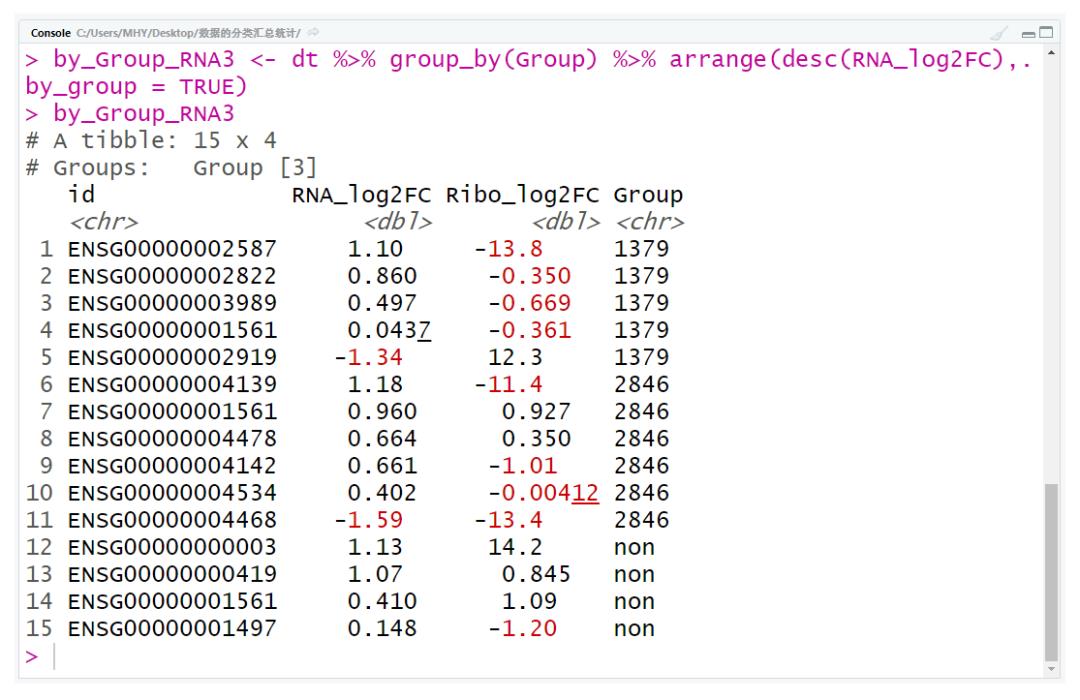
#按指定的分组顺序进行排序;
group <- factor(dt$Group,levels =unique(dt$Group),ordered = TRUE )
by_Group_RNA1 <- arrange(dt,group,desc(RNA_log2FC))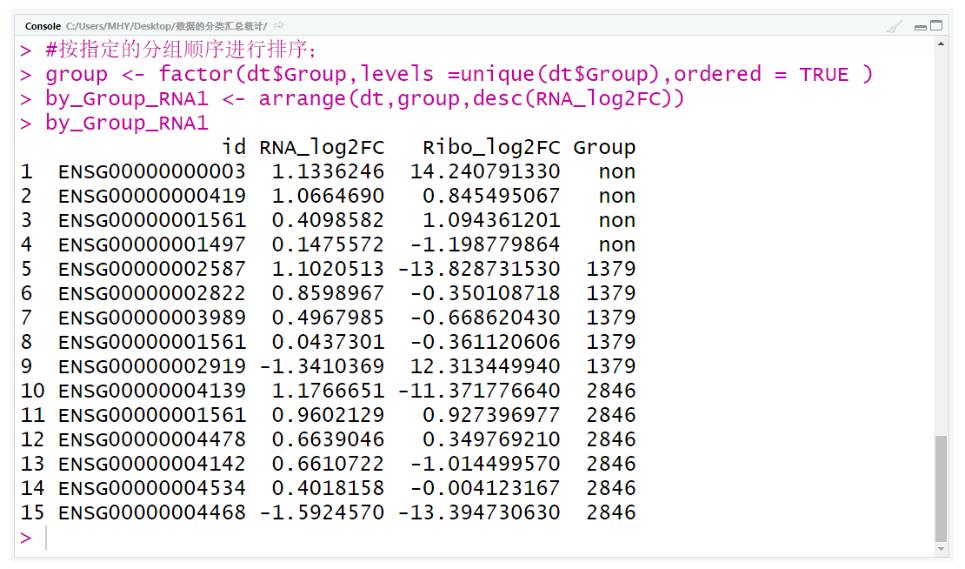
#但是如果使用group_by()则不能这样做了:Error: Column `group` is unknown
tbl <- group_by(dt,group)
# Error: Column `group` is unknown这部分内容对应Excel“数据”选项卡下的筛选和高级筛选功能,如下。
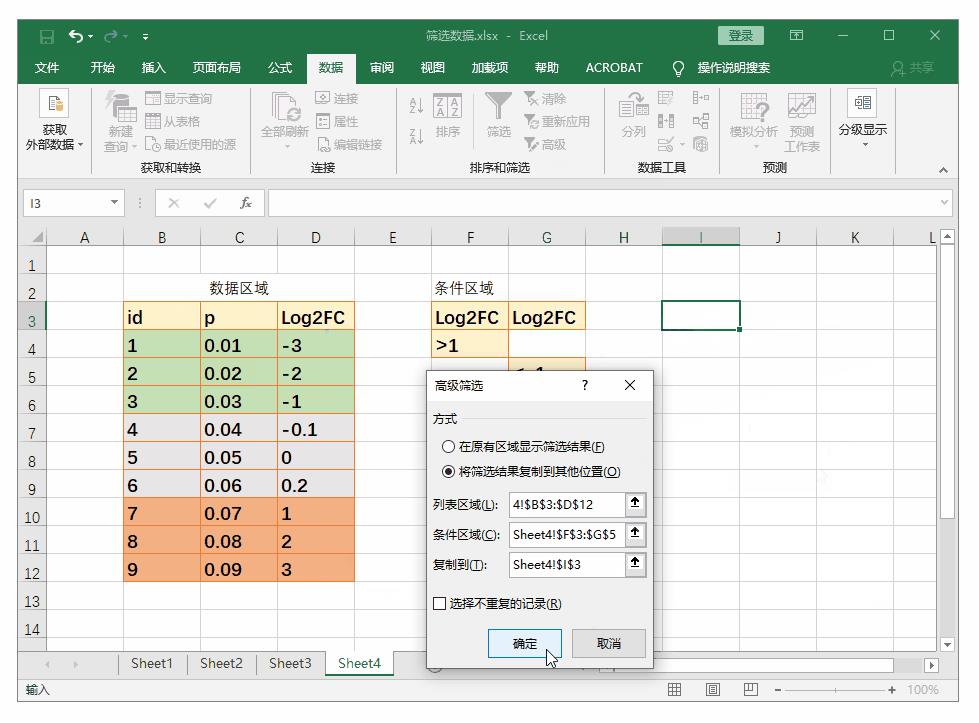
filter(dt,dt$Group=="1379")
#特殊符号:%in% 用于指定特定值集合;
filter(dt,dt$Group %in% c("non","2846"))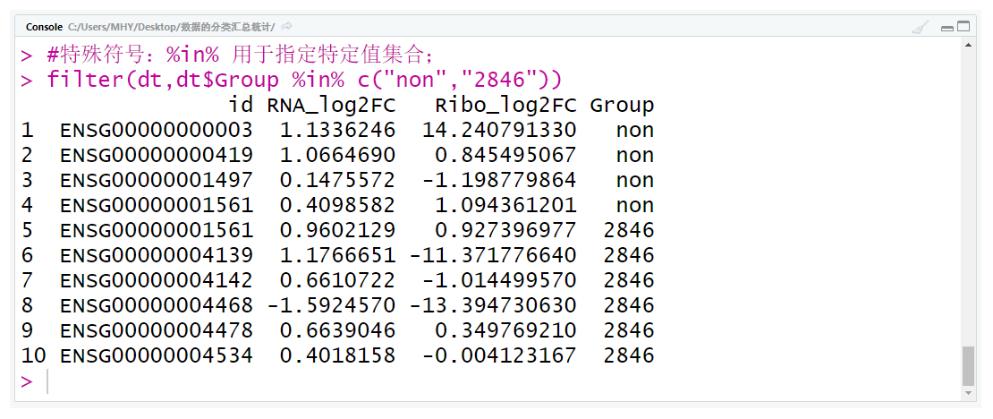
#转成dplyr匹配的tibble类型;
tb <- as_tibble(dt)
tb#以下两种写法等价:外扩号让变量直接打印出来;
(filted <- filter(tb,RNA_log2FC <= -1 | RNA_log2FC>=1))
(subdf <- subset(tb,RNA_log2FC <= -1 | RNA_log2FC>=1))#下面是同时满足两个条件的等价写法:
(filted <- filter(tb,Ribo_log2FC >= 1 , RNA_log2FC>=0))
(filted <- filter(tb,Ribo_log2FC >= 1 & RNA_log2FC>=0))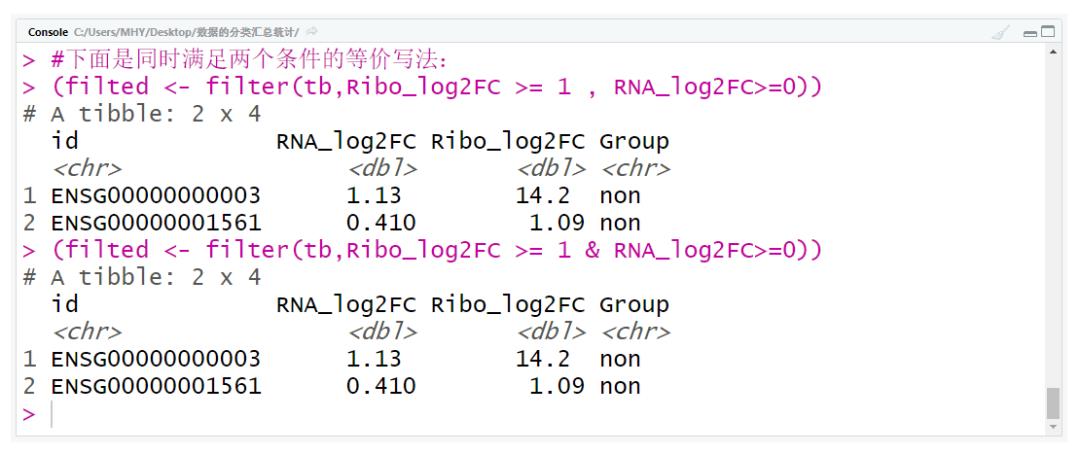
#select()函数可以选择特定的列,组成新的表格;
select(tb,RNA_log2FC,Group)select(tb,ends_with("log2FC"))
select(tb,starts_with("RNA_"),Group)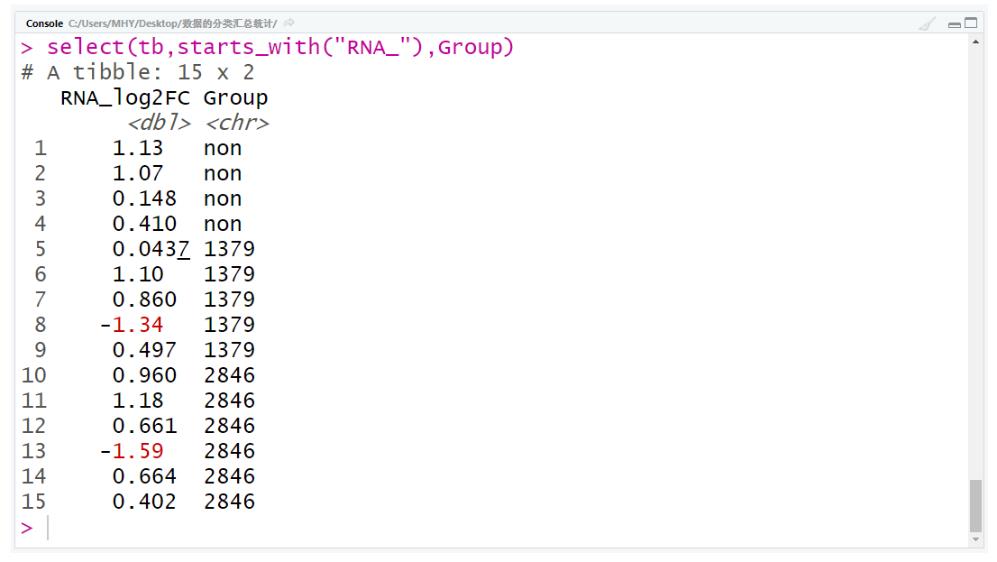
#mutate()
mutate(tb,RNA_FC = 2^RNA_log2FC)
mutate(tb,Sum = RNA_log2FC+Ribo_log2FC)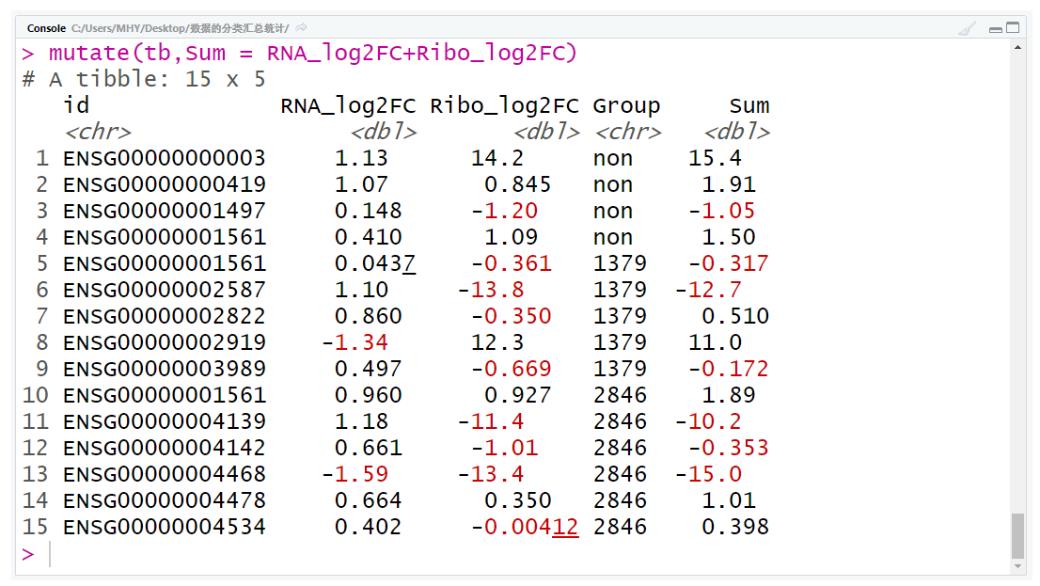
(Sum <- apply(tb[,2:3],1,sum))
(new <- tibble(tb,Sum))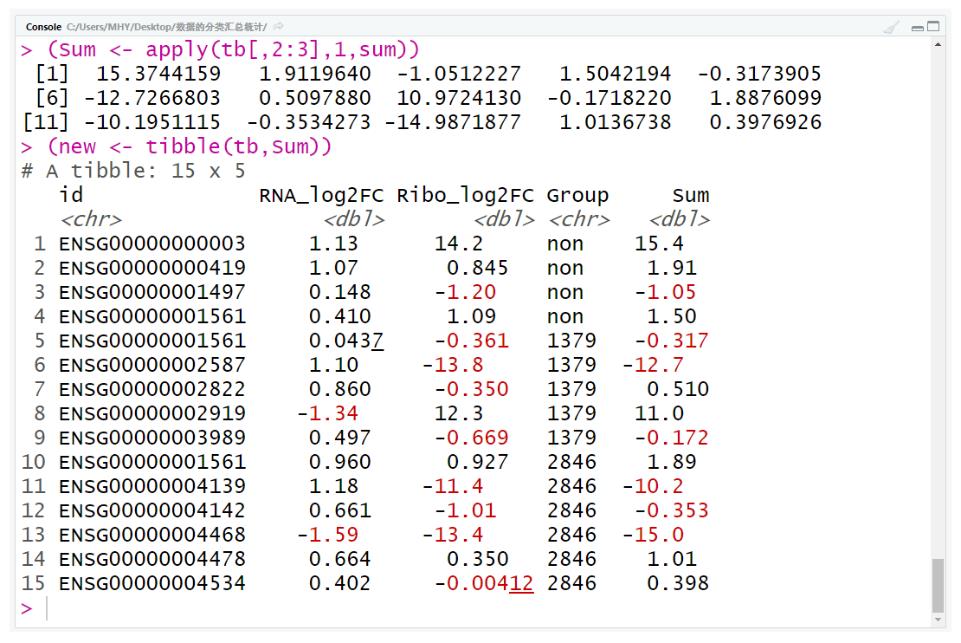
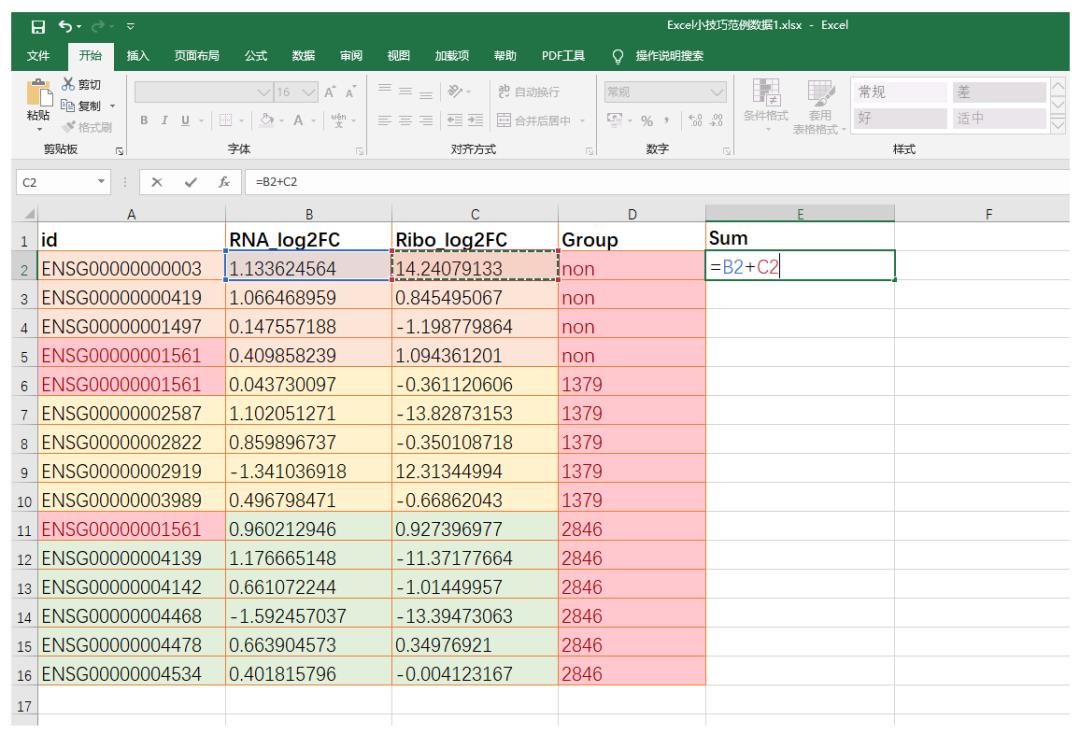
这部分对应Excel添加公式进行批量计算的操作,如下图。
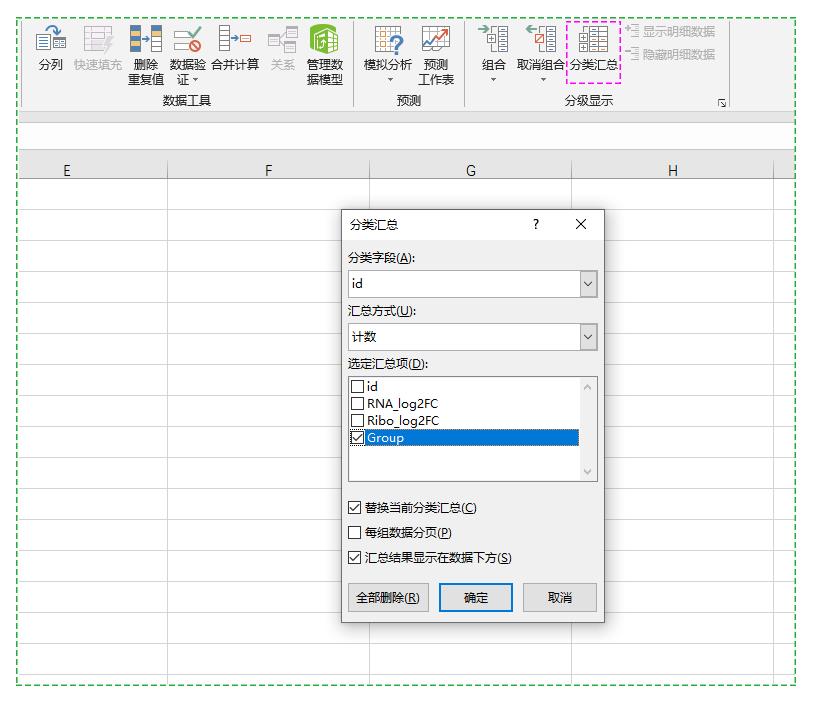
这部分内容对应Excel“数据”选项卡下的分类汇总功能,如下图。
#summarise()统计最大值,结果为单列表格。列名这里是'max(RNA_log2FC)',当然也可以在统计函数前指定生成数据的列名。
summarise(tb,max(RNA_log2FC))
#分类汇总
#统计每个分组的记录数量;
Num<-tb %>% group_by(Group) %>% summarise(num=n())
Num
#计算分组的均值;
Mean<-tb %>% group_by(Group) %>% summarise(mean(RNA_log2FC))
Mean
#转成常规数据框;
(Mean<-as.data.frame(Mean))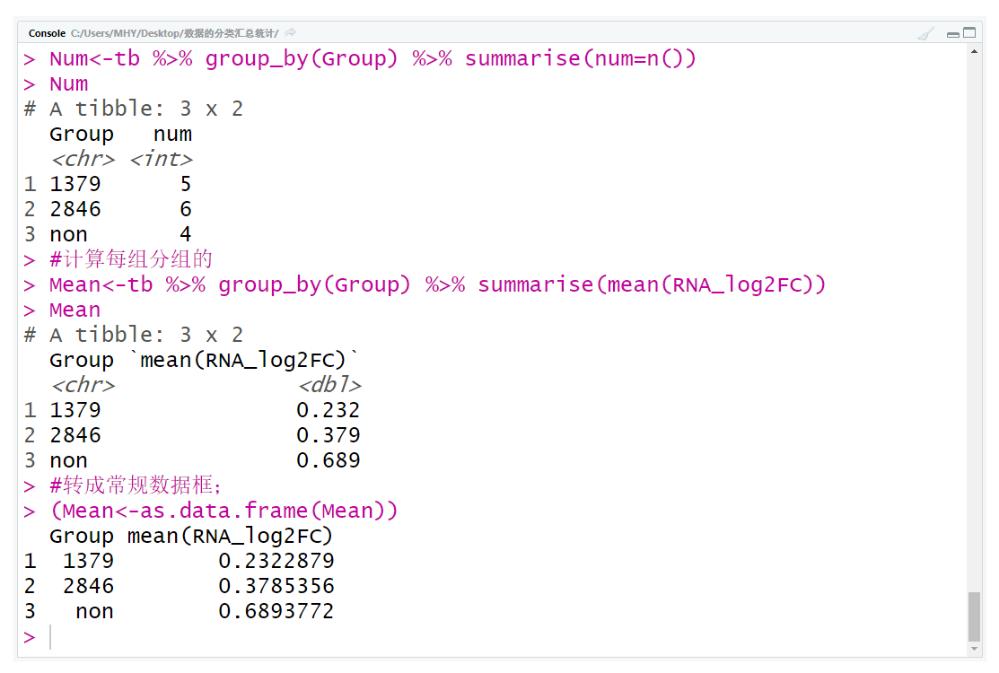
#统计每个分组的记录数量;
(am_length <- aggregate(tb, by=list(group), FUN=length))
#也可指定对某些列进行分类汇总;
(am_mpg_mean <- aggregate(tb["RNA_log2FC"], by=list(group), FUN=mean))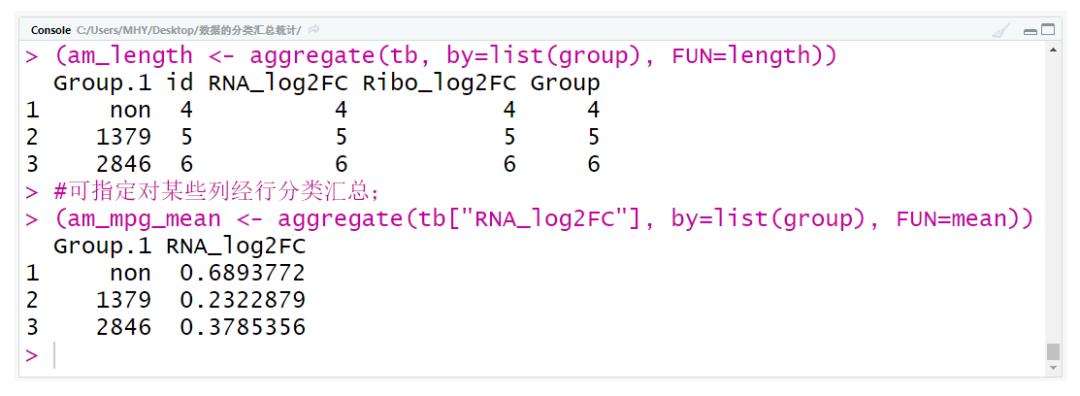
#自定义nf函数;
nf<-function(x){round(sum(x*2),2)}
(am_nf <- aggregate(tb["RNA_log2FC"], by=list(group), FUN=nf))
#对于nf函数,当然summarise()函数也是适用的;
nf_res<-tb %>% group_by(Group) %>% summarise(nf(RNA_log2FC))
nf_res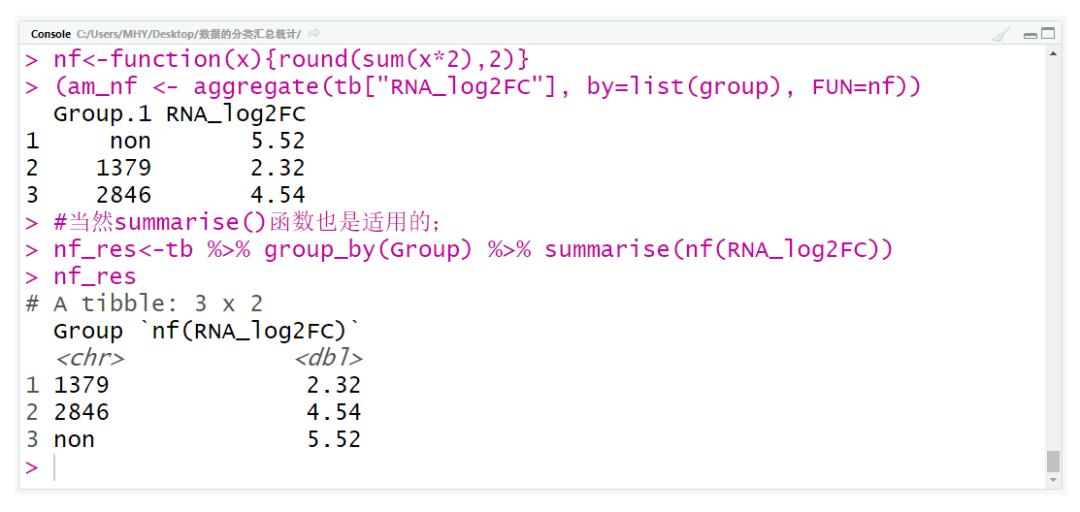
实用科研工具推荐
详实生信软件教程分享
前沿创新组学文章解读
独家生信视频教程发布
以上是关于对照着Excel入门R语言表格数据处理的主要内容,如果未能解决你的问题,请参考以下文章