(更新)R语言 dplyr的group与summarise的使用
Posted 龙氏逻辑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(更新)R语言 dplyr的group与summarise的使用相关的知识,希望对你有一定的参考价值。
最近整理一批数据,要求是统计所有变量的非缺失值数,再按照地区分组总计非缺失值数。
数据长这样(信息敏感,就涂掉了部分),包括一万多个对象以及726个变量。
可以看到第三列County是一个地区分组变量(包含南宁和玉林两个选项)。等会儿就用到dplyr包中的group来进行分组。
一、设置环境、导入数据
设置环境使用setwd,你可以将你的数据放在这里,输出的数据也会默认放在这里。
setwd('C:\Users\longxinyang1995\Desktop\shuju')导入数据,一般还是推荐将表格保存成csv格式后,用read.csv进行导入。
注意:此时参数选择header=TRUE提示第一行是表头;na.strings指定哪些值为缺失值;stringsAsFactors = FALSE表示拒绝将字符串转换成因子。
data <- read.csv('.\filename.csv', header = TRUE, na.strings = c('##','','NA'), stringsAsFactors = FALSE)二、导入包,然后将默认的data.frame转换成tibble格式(此步骤可不用)
library(dplyr)data <- as_tibble(data)
三、使用is.na()函数判断是否为缺失值
由于我们想要知道非缺失值的个数,所以选择!is.na()判断是否为非缺失值。(逻辑快要混乱掉了)如果是非缺失值则为1,不是则为0。
再使用sum()函数统计所有的1,那么非缺失值的个数就出来了。
同样的,为了统计所有列的情况,使用for循环对726列数据进行循环。此处创建了一个叫zong的向量来承接循环的结果。并再最后删去第一个空值。
zong <- c('')for (i in c(1:726)){i <- sum(!is.na(data[,i]))zong <- c(zong, i)}zong <- zong[-1]
到这里,其实未分组的统计已经结束了。
四、使用group和summarise分组统计
其实正常情况下,将南宁和玉林的数据单独提出来,再执行上面的第三步就可以了。但前天学习了新的函数(filter过滤,group_by分组,summarise统计),想要尝试一下。
我的逻辑是,针对每一个变量,先将缺失值过滤掉,然后分组,然后计算每组数的个数(注意,之前已经过滤掉了缺失值,所以这里是计算所有数的个数即为非缺失值个数)
先尝试对第一列数据进行操作,查看代码有无问题:
最后一步为重新命名表头
subdata <- filter(data, !is.na(data[,1]))difang <- group_by(subdata, County)a <- summarise(difang, n())names(a) <- c('fenzu',colnames(data[,1]))
得到如下数据:
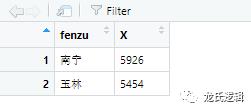
确认没有问题,使用循环,并使用之前提及到的merge函数进行一个结果的拼接,来承接每次循环的结果。(注意,由于第三列是分组变量,我这里就未对第三列进行循环)
for (i in c(2, 4:726)){subdata <- filter(data, !is.na(data[,i]))difang <- group_by(subdata, County)b <- summarise(difang,n())names(b) <- c('fenzu',colnames(data[,i]))a <- merge(a,b, all = TRUE)}
得到最终的结果数据框a:
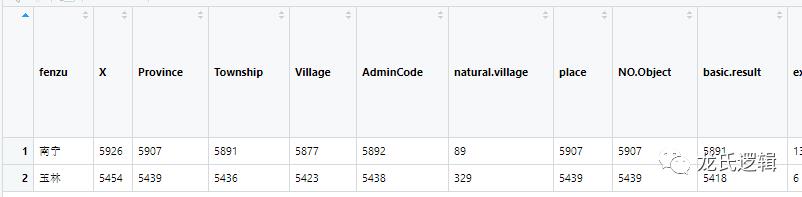
五、 合并未分组与分组的结果,输出csv文件
由于未分组时统计了第三列(分组变量),所以删除第三列,并在第一添加一个变量标识。
zong <- c("合并", zong[-3])更改前:
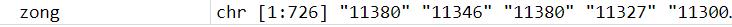
更改后:
然后合并数据,将zong这个变量作为数据框a的第三列,并用write.csv保存结果。
a[3,] <- zongwrite.csv(a, './tongjishuju20200612.csv')
六、其实summarize有很多功能。
上面只是用到了n()来统计个数。还可以用mean、median统计均值和中位数,使用sd其方差,使用IQR求四分位间距等等。
尝试一下,以某个变量为例,如身高(数据需要事先清洗一下,比如没有非数字,保证所有的空值都已经被排除,不然会报错):
subdata <- filter(data, !is.na(data$Height))difang <- group_by(subdata, County)a <- summarise(difang, n(), mean(Height), sd(Height))names(a) <- c('fenzu',colnames(data[,1]),'mean','sd')
结果如下:
但是我发现mean()里面的参数,只能填变量名,若是用data[,20]代替会失败。那么可能做循环的话就不能直接用i in c(1:726)了。而是应该将所有表头名放进一个向量,比如X。然后用i in X来做条件才行。
今天到此结束。目前还是只能做一些简单的统计。下次可以考虑做一些更深的分析,并结合画图来展示,毕竟ggplot的图确实挺好看的。
以上是关于(更新)R语言 dplyr的group与summarise的使用的主要内容,如果未能解决你的问题,请参考以下文章