R语言 | 多元回归中常见的变量选择方法
Posted 生物空间站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言 | 多元回归中常见的变量选择方法相关的知识,希望对你有一定的参考价值。

变量选择(variable selection)是从回归的所有预测变量集合中选择预测变量子集的过程,目的是在减少候选预测变量的数量的同时尽可能不丢失过多的解释度。
对于这个过程,可以根据回归中各预测变量的回归系数的显著性手动判断选择。也有一些机器自动选择方法,目前比较常用的例如逐步回归法(stepwise method),全子集回归(all-subsets regression)等。
下文以为例,简介这些变量选择方法在R语言中的实现过程。
注:以下提到的变量选择方法在很多类型回归中,例如广义线性模型等中都是可以通用的。
示例数据,R代码的百度盘链接(提取码,8x3y):
https://pan.baidu.com/s/1gr4ef4alXou2mMdwQ-601A
若百度盘失效,也可在GitHub的备份中获取:
https://github.com/lyao222lll/sheng-xin-xiao-bai-yu
一个多元线性回归示例
首先来看一个多元线性回归示例,来自前文“”。
节选马里兰州生物资源调查研究(https://dnr.maryland.gov/streams/Pages/mbss.aspx)的部分数据,记录了马里兰州河流中每75米长的区段水域内,鱼类物种Rhinichthys cataractae的丰度,并测量了每段水域中相应的环境特征。
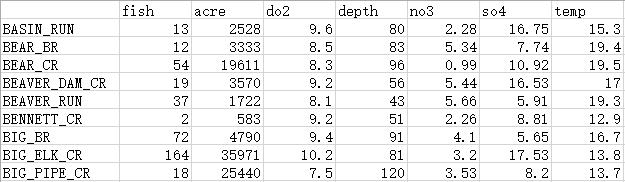
其中第一列代表了调查河流区段的位置信息,其余各列依次为:
fish,水域中鱼类物种Rhinichthys cataractae的个体数量,代表了物种丰度;
acre,水域流域面积(英亩,acre);
do2,水域溶解氧含量(毫克/升,mg/L);
depth,水域最大深度(厘米,cm);
no3,水域硝酸盐浓度(毫克/升,mg/L);
so4,水域硫酸盐浓度(毫克/升,mg/L);
temp,水域温度(摄氏度,℃)。
这里期望通过多元线性回归,探索可能影响鱼类物种Rhinichthys cataractae丰度的环境因素,并对物种丰度变化的原因作出解释。
#读取鱼类物种丰度和水体环境数据
dat <- read.delim('fish_data.txt', sep = ' ', row.names = 1)
#首先使用全部环境变量拟合与鱼类物种丰度的多元线性回归
fit1 <- lm(fish~acre+do2+depth+no3+so4+temp, data = dat)
summary(fit1) #展示拟合方程的简单统计
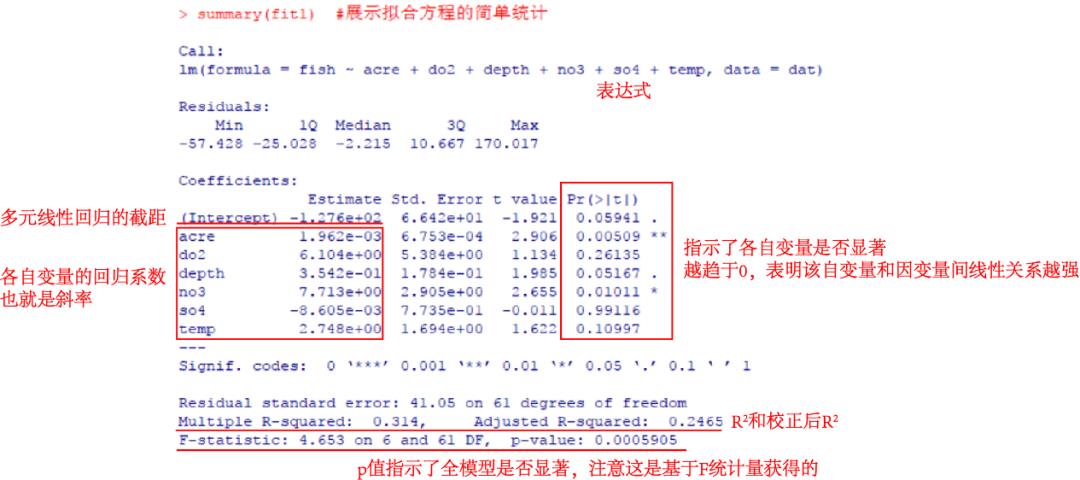
各结果项的描述详见前文“”。简单概括,acre(流域面积)和no3(硝酸盐浓度)的增加有助于物种丰度的增加;depth(水域深度)的增加也轻微贡献了物种丰度的提升;未观察到物种丰度与do2(水域溶解氧含量)、so4(水域硫酸盐浓度)和temp(水域温度)呈线性响应。
忽略全模型的校正后R2仅为0.247,算不上很高,归因于物种丰度和大部分环境因素间关系实际上并非线性这样简单,这里选择线性模型的原因只是它更易于理解和简化问题。
接下来,期望通过一些变量选择方法,去除部分“无效”的预测变量,也就是对物种丰度变化的贡献度偏低的环境因素,以实现对这个线性模型的优化。
手动选择变量
这个在前文“”中也已有提到,这里再拿来展示下。
可以根据各预测变量在回归中的p值进行判断,将不显著的预测变量手动去除。例如,do2(水域溶解氧含量)、so4(水域硫酸盐浓度)和temp(水域温度)是非常不显著的,表明这些环境因素的变动不会引起物种丰度增加或减小的线性响应(可能存在其它的非线性响应方式,但由于这里只期望关注线性关系,所以暂不考虑复杂情况),因此考虑去除它们。depth(水域深度)临界显著性,索性保留吧,将它与显著的acre(流域面积)和no3(硝酸盐浓度)一起,重新建立线性回归。
#只考虑使用 3 个和鱼类物种丰度线性关系较为明显的环境变量拟合多元线性回归
#这里将处于线性关系临界值的 depth 也算在内
fit2 <- lm(fish~acre+no3, data = dat)
summary(fit2) #展示拟合方程的简单统计
#anova() 检验前后两个嵌套模型的拟合优度
#比较去除 3 个不显著的预测变量后,回归整体预测性能是否一样好
anova(fit2, fit1)
#AIC 评估前后两个回归复杂性与拟合优度的关系
#AIC 值较小的回归优先选择,表明较少的预测变量已经获得了足够的拟合度
AIC(fit2, fit1)

这是手动选择变量后,计算的多元线性回归,并比较了变量选择前后两个回归的优度。
总体来看,回归中去除了3个不显著的预测变量后,变得变得精简和易于解读;同时精度并未下降,以校正后的R2为例,先前是0.247,这里为0.246,是一致的。
最终选择的影响鱼类物种丰度的环境因素的多元回归式为:
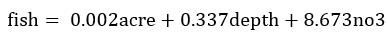
式中保留了depth(水域深度),也认为它对物种丰度具有较小贡献(尽管不是很显著,但也接近)。您也可以选择去除它,然后重新拟合回归,总之这种变量选择存在一定的人为主观性。
式中的截距项不显著,因此没有保留它。这也是可以解释的,截距项代表了在其它预测变量为0时的物种丰度。毕竟当acre(流域面积)或depth(水域深度)的取值为0时,代表河流枯竭,此时是不可能有鱼类物种生存,因此截距项的存在没有意义。
逐步回归选择变量
当初始回归模型中的预测变量比较多时,手动判断选择变量就比较繁琐,此时不妨尝试一些机器自动选择变量的方法。
首先简介逐步回归(stepwise method)。逐步回归中,回归模型会一次添加或者删除一个预测变量,直到达到某个判停准则为止。逐步回归法的实现依据增删变量的准则不同而不同,常见类型主要包括3种:前向逐步回归,后向逐步回归以及双向逐步回归。
R语言中,MASS包中的stepAIC()可以实现逐步回归(前向、后向和双向),依据的是AIC(Akaike Information Criterion,赤池信息准则)。通过选择最小AIC统计量对应的回归模型,来达到删除或增加变量的目的。接下来,使用这种自动选择方法,对上文中物种丰度和环境因素关系的多元线性回归执行变量选择。
前向逐步回归
前向逐步回归(forward stepwise regression)或称前向选择(forward selection),每次添加一个预测变量到回归中,直到添加变量不会使回归精度(总R2)有所改进时为止。
因此,首先需要构建一个只包含1-2个少数预测变量的起始回归模型(推荐找一个最显著的预测变量作为起始模型),或者直接使用不含任何预测变量的空模型,随后使用前向逐步回归依次往回归中添加其它预测变量,直到模型最优。
library(MASS)
#首先构建了一个只包含 1 个非常显著的预测变量的起始回归模型
fit0 <- lm(fish~acre, data = dat)
#如果使用不含任何预测变量的空模型
#fit0 <- lm(fish~1, data = dat)
#随后应用前向选择逐步往里添加新的预测变量,直到模型最优或达到指定的最大变量数量
stepAIC(fit0, direction = 'forward',
scope = list(lower = fit0, upper = ~acre+do2+depth+no3+so4+temp))

起始回归模型中只包含1个预测变量,acre(流域面积)。然后每一步中,AIC列提供了增加一个新的预测变量后模型的AIC值,<none>中的AIC值表示没有变量被添加时模型的AIC值。当存在新的预测变量添加后的AIC值小于<none>的AIC值时,选择能够使AIC值最小的预测变量添加到原有的回归中。依次类推,直到不存在新的预测变量添加后的AIC值小于<none>的AIC值时终止选择。
前向逐步回归选择变量后,最终保留了3个有效的预测变量,acre(流域面积)、no3(硝酸盐浓度)以及depth(水域深度)。因此最终选择的影响鱼类物种丰度的环境因素的多元回归式为:
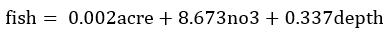
和上文结果是一致的。
后向逐步回归
后向逐步回归(backward stepwise regression)或称后向选择(backward selection),从完整模型(包括所有预测变量)开始逐一删除预测变量,若某变量删除之后回归精度降低最少则对其执行删除,直到删除某变量时回归精度发生明显降低时为止。
因此,首先考虑使用全部的预测变量构建起始回归模型,随后通过后向逐步回归依次在回归中逐一删减预测变量,直到模型最优。
#首先使用全部环境变量拟合与鱼类物种丰度的多元线性回归,作为起始回归模型
fit1 <- lm(fish~acre+do2+depth+no3+so4+temp, data = dat)
#随后应用后向选择逐步在模型中删减预测变量,直到模型最优
stepAIC(fit1, direction = 'backward')

起始回归模型中包含所有的6个预测变量,acre(流域面积)、no3(硝酸盐浓度)、depth(水域深度)、do2(水域溶解氧含量)、so4(水域硫酸盐浓度)和temp(水域温度)。然后每一步中,AIC列提供了删减一个已有预测变量后模型的AIC值,<none>中的AIC值表示没有变量被删减时模型的AIC值。当存在某预测变量被删除后的AIC值小于<none>的AIC值时,选择能够使AIC值最小的预测变量在原有回归中删除。依次类推,直到不存在任意预测变量删除后的AIC值小于<none>的AIC值时终止选择。
后向逐步回归选择变量后,最终保留了3个有效的预测变量,acre(流域面积)、no3(硝酸盐浓度)以及depth(水域深度)。因此最终选择的影响鱼类物种丰度的环境因素的多元回归式为:
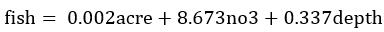
和上文结果是一致的。
双向逐步回归
双向逐步回归(stepwise stepwise regression)或称双向选择(forward-backward selection),结合了前向选择和后向选择的方法。每次添加一个预测变量到回归中,并同时分析检查是否能将一些已涵括的没有贡献的预测变量移除用于改进模型。预测变量可能会被添加、删除好几次,直到获得最优模型为止。
因此,首先需要构建一个只包含1-2个少数预测变量的起始回归模型(推荐找一个最显著的预测变量作为起始模型),或者直接使用不含任何预测变量的空模型,随后使用双向逐步回归依次往回归中添加其它预测变量,并同时考虑是否可以删除其中某个已存在的预测变量以提升模型优度,直到模型最优。
#首先构建了一个只包含 1 个非常显著的预测变量的起始回归模型
fit0 <- lm(fish~acre, data = dat)
#如果使用不含任何预测变量的空模型
#fit0 <- lm(fish~1, data = dat)
#随后执行双向选择,逐步往里添加新的有效预测变量,并考虑删除已存在的无效预测变量,直到模型最优或达到指定的最大变量数量
stepAIC(fit0, direction = 'both',
scope = list(lower = fit0, upper = ~acre+do2+depth+no3+so4+temp))

起始回归模型中只包含1个预测变量,acre(流域面积)。然后每一步中,AIC列提供了增添或删减某预测变量后模型的AIC值,<none>中的AIC值表示没有变量被增添或删减时模型的AIC值。当存在某个预测变量增添或删减后的AIC值小于<none>的AIC值时,选择能够使AIC值最小的预测变量在原有的回归中增添或删减。依次类推,直到不存在新的预测变量增添或删减后的AIC值小于<none>的AIC值时终止选择。
双逐步回归选择变量后,最终保留了3个有效的预测变量,acre(流域面积)、no3(硝酸盐浓度)以及depth(水域深度)。因此最终选择的影响鱼类物种丰度的环境因素的多元回归式为:
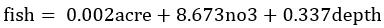
和上文结果是一致的。
全子集回归选择变量
逐步回归方法存在一些局限性,例如不能保证每一种可能的预测变量组合都参与评价。相比之下,全子集回归(all-subsets regression)能够将所有可能的组合模型都考虑在内,综合评估由N个不同子集大小(一个、两个或多个预测变量)的最佳模型。
R语言中,全子集回归可用leaps包中的regsubsets()实现。接下来,使用这种自动选择方法,对上文中物种丰度和环境因素关系的多元线性回归执行变量选择。
library(leaps)
#全子集回归评估最佳的 N 变量组合
leap <- regsubsets(fish~acre+do2+depth+no3+so4+temp, data = dat, nbest = 2)
plot(leap, scale = 'adjr2') #以校正后 R2 代表模型精度
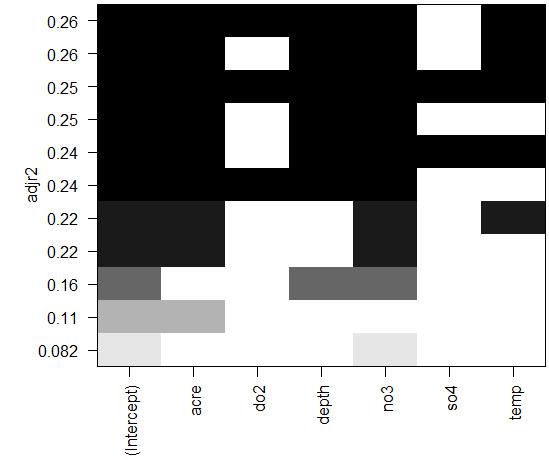
regsubsets()中设置了nbest=2,即在各N变量组合下的所有情况中,只展示两个最佳的N变量组合。
该图中,横轴代表预测变量,纵轴代表回归的精度(这里使用的校正后的R2),即展示了当考虑不同的预测变量组合时,回归精度的变化情况。例如,当仅考虑no3作为预测变量时,回归的R2.adj=0.082;当仅考虑acre作为预测变量时,回归的校正后R2=0.11;当考虑acre和no3作为预测变量时,回归的R2.adj=0.22;当考虑acre、no3和depth作为预测变量时,回归的R2.adj=0.25。
通过该图可作出判断,acre(流域面积)、no3(硝酸盐浓度)以及depth(水域深度)是最合适的三预测变量组合。其余情况,要么校正后R2过低,要么预测变量数量过多不利于解读。
此外,car包也提供了在全子集回归结果中帮助选择最佳变量子集的方法。
#辅助选择预测变量组合
library(car)
subsets(leap, statistic = 'cp')
abline(1,1,lty = 2,col = 'red')
越好预测变量组合离图中红线(截距项和斜率均为1的直线)越近。据此再次得出判断,acre(流域面积)、no3(硝酸盐浓度)以及depth(水域深度)是最合适的三预测变量组合。
随后再通过这3种环境预测变量,建立和鱼类物种丰度的多元线性回归即可,不再多说,和上文结果是一致的。
关于变量选择的一些注意问题
对于机器自动选择变量的方法而言,全子集回归要优于逐步回归,因为考虑了更多的预测变量组合情况。但是,当有大量预测变量时,全子集回归会很慢。一般来说,变量自动选择应该被看做是对回归模型选择的一种辅助方法,而不是直接方法,因为可能选择了数学上显著但是在生物学上无意义的模型。
多元回归中涉及的变量较少时,手动选择方法优于机器自动选择。尽管主观性较强,但有利于根据经验建立生物学上易于解释的变量关系。
参考资料
推荐阅读
以上是关于R语言 | 多元回归中常见的变量选择方法的主要内容,如果未能解决你的问题,请参考以下文章