R语言机器学习 | 7 支持向量机
Posted PsychRun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言机器学习 | 7 支持向量机相关的知识,希望对你有一定的参考价值。
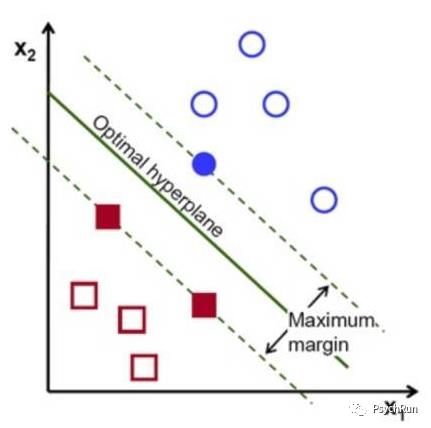
因此,我们需要选择一条最佳的直线将其分类,使得类间数据点的间隔最大。为了求得这样的直线,SVM使用的数学方法即最大间隔方法。
简单而言,如下图所示,要使类间距离margin最大,可以先作一条虚线穿过一个蓝色的点,然后画与其平行的另一条虚线穿过红点,通过旋转平行的虚线,可以不断增加类间距离。当旋转到某个时候,一条虚线穿过了两个红点,此时就是类间间隔最大的时候,即maximun margin。
这样一个最优的超平面(这里是直线),表示其邻域的两条直线刚好接触到两类中的三个点,即这三个点就实际上决定了这个分类器。由于空间中每个点都是一个向量,因此,这三个点就被称为支持向量,这种分类方法就叫支持向量机。
上述情形是线性可分的情况,我们已经知道,在这种情况下利用之前提到的线性判别分析方法也可以很好地对数据进行分类。那么,当数据具有明显的线性不可分特征时,SVM相比之下就有一种非常好的解决线性不可分问题的方法,即使用核函数。核函数的使用可以说是SVM最强力的武器。
例如,下面左图中两类样本显然无法用直线分开,任何线性的分类器可能都表现欠佳,但是我们发现这些数据点的分布是一个椭圆形,如果用椭圆曲线就可以将两类数据轻松分开。借助这个思想,我们可以将椭圆方程变换为直线方程,然后进行线性的分类。一般椭圆方程是w1x1^2+w2x2^2+b=0,我们可以将椭圆的二次项变换为一次项w1z1+w2z2+b=0,再以z1、z2作为坐标轴,从而实现线性可分。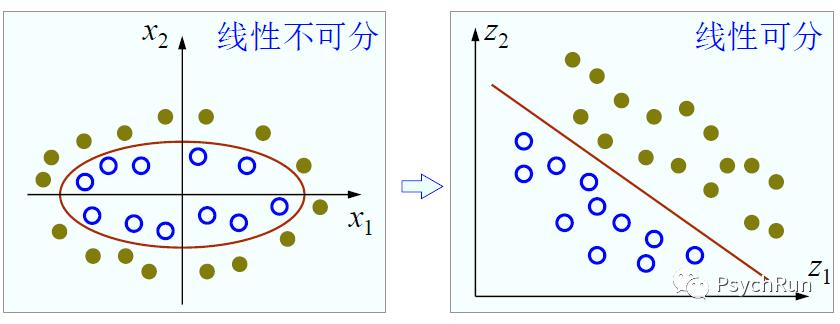
这种用线性方法解决非线性问题的方法的思想是:使用一个合适的变换(或者叫映射),将原来低维空间中的数据映射到新的高维空间,然后在高维空间里使用线性分类方法进行分类。
以上面的例子来说,相当于就是把一个二维的平面上的数据点投射到了一个三维的二次面上(x1→x1^2; x2→x2^2),从而使数据在高维空间可分。但是,当数据从低维变为高维后,通常带来的是维数灾难,即极大的增加运算难度,而核函数方法可以通过引入一些数学技巧,使得较为轻松地找到合适的变换方式,并以相对容易地完成这样一种变换。具体的数学方法这里不细讲。
概念就简单讲到这,其R语言的实现和之前的判别分析一样轻松,可以使用e1071包进行实现。其过程和之前的方法类似,这里不再赘述。
值得注意的是,svm()函数除了输入特征、标签之外,还可以自己设定“核”(kernal),比如这里演示的是使用sigmoid核,此外还可以使用多项式核(polynomial)、径向基核(radial basis)等,在实际过程中可以通过交叉验证等方法尝试不同的核函数,最后选一个最好的核函数即可。这里的混淆矩阵结果表明分类效果还不错,正确率达到95.6%。
set.seed(100)index <- sample(nrow(iris),0.7*nrow(iris)) #在x里面抽size个样本;这里直接是抽index,以便接下来使用。train <- iris[index,]test <- iris[-index,]library(e1071)M1 = svm(data=train,Species~.,kernal='sigmoid',probability = TRUE) #kernal是核函数,有多种核函数如 polynomial/radial basis;prob是为了之后算ROCsummary(M1)pre_svm = predict(M1,test) #默认prediict是分类table(test$Species,pre_svm) #混淆矩阵
以上是关于R语言机器学习 | 7 支持向量机的主要内容,如果未能解决你的问题,请参考以下文章