R语言 | R包pls的偏最小二乘(PLS)回归
Posted 生物空间站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言 | R包pls的偏最小二乘(PLS)回归相关的知识,希望对你有一定的参考价值。

偏最小二乘(PLS)回归的特点
PLS使用hPLS1和PLS2算法(hPLS1 and PLS2 algorithms,hPLS1对应于只有一个响应变量的情况,PLS2对应于存在多个响应变量的情况,hPLS1可视为PLS2的特例)计算成分,目的是选择能够最大程度解释响应变量的一组成分,降维后的成分代表了最能解释响应变量矩阵的特征。对比另一种类似的基于成分的回归方法,,自变量矩阵的降维过程是独立进行的,与响应变量矩阵无关,获得的成分主要描述了自变量的特征。因此与主成分回归相比,PLS更易于辨识系统信息与噪声,对观测值的不确定性更具鲁棒性,并使得回归系数将更容易解释。
尽管PLS允许在单个模型中拟合多组响应变量,但只有当多组响应变量间不相关时,才适用于对多组响应变量的建模。
如果从主成分回归或从PLS回归获得的成分数量等于原始自变量的数量,则三种方法(偏最小二乘回归,主成分回归和普通最小二乘回归)返回的结果(自变量矩阵对响应变量矩阵的解释程度)相同。
作为一种基于成分的回归方法,PLS的其它普遍特点可参考前文“”的描述。
对于应用,PLS更建议使用于数据集中变量数远大于样本数,且变量间存在更高度相关时的情况。例如很多组学数据集具有非常高维的特征,这些数据中变量数量远远大于观测样本的数量,并且变量间存在高度相关()。特别是蛋白质组、代谢组等光谱测量值数据,光谱测量值中包括许多普遍相关的化学成分或各种理化特性之间的关系。因此, PLS更多应用于对光谱测量值(NIR、IR、UV)之间的关系进行建模,这也是在文献中见到的PLS应用最多的情景。
R包pls的偏最小二乘(PLS)回归
接下来以R包pls中的方法为例,简单展示PLS回归的实现。同样地,以某光谱数据为例。
示例数据
pls包的内置数据集yarn,记录了28个不同密度的涤纶纱在268种不同波长下的近红外光谱测量数据。
library(pls)
#示例数据,详情 ?yarn
data(yarn)
head(yarn)

NIR.n,共计268列,代表了268种不同波长下的红外光谱数据。
density,记录了28个涤纶纱的密度数值。
train,数据集已经提前划分为两组,一组包含了21个涤纶纱数据(标记为TRUE),作为训练集构建回归模型;另一组包含7个涤纶纱数据(标记为FALSE),用作测试集评估模型的预测性能。
接下来使用PLS回归,拟合涤纶纱的红外光谱测量值和其密度的关系。目的为构建一个合适的模型,能够通过红外光谱测量值准确预测涤纶纱密度,并尝试寻找更重要的特定波长的光谱。
PLS回归执行及结果解读
首先,使用训练集的数据中全部的光谱测量值拟合与涤纶纱密度的PLS回归。PLS通过包中函数plsr()执行。
注意输入数据集中的变量名称,所有的自变量统一使用“var_class.n”(即变量类型+序号)类似的名称表示,var_class在本示例中就是NIR,n是1-268。
#选择训练集和测试集
yarn_train <- subset(yarn, train)
yarn_test <- subset(yarn, !train)
##使用训练集数据构建 PLS 回归模型,详情 ?plsr
#例如这里设定成分数 4(结果中展示前 4 个主要的成分),并执行交叉验证
pls_mod <- plsr(density~NIR, data = yarn_train, scale = TRUE, ncomp = 4, validation = 'CV')
summary(pls_mod) #回归统计概要

在该示例中,对于参数“ncomp = 4”指定的成分数量4,它指的是在统计结果中展示前4个主要的成分。计算过程中会得到全部的成分,该参数指明在全部结果中提取前4个主要的成分用于统计计算。
不同参数值的ncomp指定会影响部分统计结果,如交叉验证以及重要变量的识别;但对于成分的方差解释率,则是不受其影响的。因此,如果模型重在“预测”,该参数影响不大;但如果期望通过模型评估重要价值的变量,则该参数的选择要慎重。一种确定成分数量的可行方法是,对成分的重要性进行评估后,选择合适的成分数量,重新在plsr()在设置ncomp参数。
结果中,展示的4个成分已经按重要性由高到低排序,并给出了4个成分的累积贡献。
CV和adjCV为成分的交叉验证结果,默认使用10折交叉验证,代表了模型误差随成分数量增加的累积关系。通常,随成分数量的增加,误差会降低。开始时下降明显,但到了特定位置时,下降幅度将不再有明显改变,可据此评估重要的成分。(该统计项的数值与ncomp的指定有关)
% variance explained中,X和density分别代表了各成分对自变量矩阵和响应变量矩阵的累积总方差解释率。同样地,随成分数量的增加,累积方差解释率会提升。开始时提升明显,随后越趋缓慢,可据此评估重要的成分。(该统计项的数值与ncomp的指定无关)
可以看到,排名靠后的成分的贡献已经很低了,提示只重点解释前2-3个成分的效应就可以了。
成分的重要性评估和选择
pls包中,可通过validationplot()查看当前PLS回归模型的预测均方误差(MSEP)、预测均方根误差(RMSEP)或模型R2与成分数量的关系,评估成分的重要性,帮助确定选择哪些成分是合适的。
#查看成分的重要性,确定保留哪些成分是合适的
#详情 ?validationplot
par(mfrow = c(1, 2))
validationplot(pls_mod, val.type = 'MSEP')
validationplot(pls_mod, val.type = 'R2')
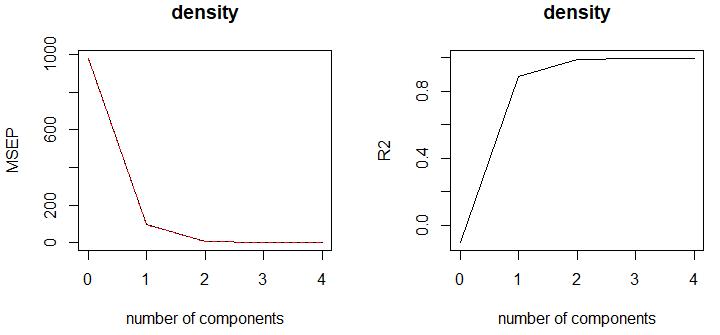
可以看到,第一成分的贡献度最高,前两成分的贡献是最明显的,第三成分及以后的贡献很低,因此选择前1-2个成分就可以了。
模型预测值和观测值的一致性与成分的关系
不妨比较使用不同数量的成分拟合出的涤纶纱密度预测值与涤纶纱密度观测值的的一致性。
#模型预测值和响应变量实际观测值的比较简图
#ncomp 指定预测使用的成分数量
par(mfrow = c(1, 3))
plot(pls_mod, ncomp = 1, line = TRUE) #使用第一成分的预测
plot(pls_mod, ncomp = 2, line = TRUE) #使用前两成分的预测
plot(pls_mod, line = TRUE) #使用全部成分的预测
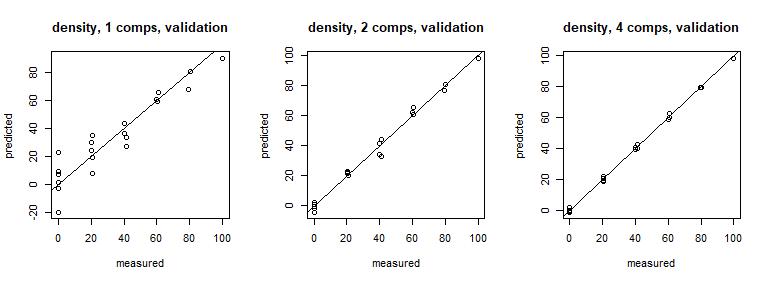
横轴是观测值,纵轴是预测值。
结果中同样可以看到,使用前两成分的PLS模型预测精度与全模型精度几乎相差无几,前两成分足以代表数据集的整体特征。
通过得分图观察样本特征与成分的关系
由于PLS也是降维的方法,因此也可以像那样,绘制得分图展示样本沿成分轴上的分布特征,描述涤纶纱密度或者不同波长的红外光谱与前两个主要成分的关系。
现在将前两个成分提取出来,绘制得分图。
#查看结果中包含的各类统计信息,可通过“pls_mod$XXX”之类的语句提取查看
names(pls_mod)
#例如,提取对象得分(可以理解为,样本投影在成分轴上的坐标)
yarn_site <- pls_mod$scores
#合并涤纶纱密度数值信息
yarn_site <- data.frame(yarn_site[ , ])
yarn_density <- yarn_train$density
yarn_site <- cbind(yarn_site, yarn_density)
#绘制得分图
library(ggplot2)
ggplot(yarn_site, aes(Comp.1, Comp.2, color = yarn_density)) +
geom_point() +
scale_color_gradientn(colors = c('green', 'orange', 'red')) +
theme_bw()
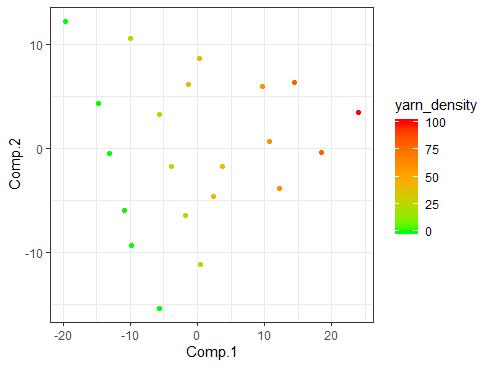
上文已经得知,第一成分的贡献度最高,解释了原始数据的大部分方差。这里通过得分图还能清晰的观察到,涤纶纱密度沿第一成分轴具有明显的递增趋势,第一成分即很好地描述出了响应变量的特征。第二成分不如第一成分的贡献明显,但也能观察到涤纶纱密度沿第二成分轴的微弱递增趋势。
使用测试集评估模型的预测性能
进一步,使用测试集数据继续评估已构建好的PLS回归应用至训练集外的其它数据时,是否同样具有良好的预测性能。
#将该 PLS 回归应用至测试集数据
#进一步比较模型预测值和响应变量观测值的一致性
par(mfrow = c(1, 2))
#使用前两成分的预测
fit_test_2 <- predict(pls_mod, yarn_test, ncomp = 2)
plot(yarn_test$density, fit_test_2, main = 'density, 2 comps, validation',
xlab = 'measured', ylab = 'predicted')
abline(0, 1, col = 'red')
#使用全部四个成分的预测
fit_test_4 <- predict(pls_mod, yarn_test, ncomp = 4)
plot(yarn_test$density, fit_test_4, main = 'density, 4 comps, validation',
xlab = 'measured', ylab = 'predicted')
abline(0, 1, col = 'red')
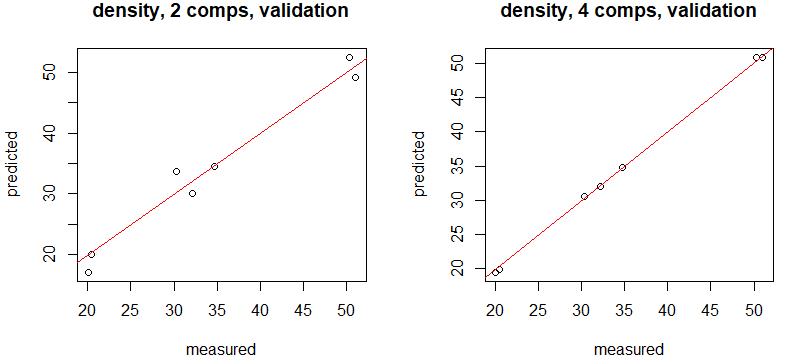
结果显示,对于测试集数据,已构建好的PLS回归的预测效果依然良好。
变量的相对重要性
如果期望查看PLS回归模型中,哪些自变量的贡献度更高,可以根据它们的回归系数评估相对重要性。对于本示例而言,评估重要的变量就是寻找少数几种代表性波长的红外光谱,它们的测量值与涤纶纱密度更具关联。
特别注意,在上文提到,plsr()构建回归模型时,参数ncomp的指定将非常影响后续的对重要变量的识别。不同的ncomp设定值下,变量的重要性排名将会发生明显改变,因此该参数的选择要慎重。在上文的分析探讨中,得知前两个成分就足以表征数据集的整体特征,因此考虑重新通过plsr()构建回归,设定ncomp=2并根据回归系数分析变量的重要性。
#这次直接使用全部的数据集(不区分训练集或测试集)构建 PLS 回归
#plsr() 中重新设定成分数 2
pls_mod2 <- plsr(density~NIR, data = yarn, scale = TRUE, ncomp = 2, validation = 'CV')
#由于变量在 PLS 回归时已经过 scale 参数执行了标准化处理
#因此可将回归系数的绝对值大小作为评估变量的相对重要性的依据
coefficients <- coef(pls_mod2)
coef_weight <- abs(coefficients) #回归系数的绝对值
coef_sum <- sum(coef_weight)
importance <- coef_weight * 100 / coef_sum #根据回归系数的绝对值计算的各变量的百分比重要性
importance <- sort(importance[ ,1,1], decreasing = TRUE) #按重要性排序
importance <- cbind(importance, coefficients = coefficients[ ,1,1][names(importance)])
write.table(importance, 'NIR_importance.txt', col.names = NA, sep = ' ', quote = FALSE)
#查看前 10 种重要的光谱
coef_top10 <- head(importance, 10)
coef_top10
par(las = 1)
barplot(coef_top10[ ,1], horiz = TRUE, width = 0.6, xlab = 'importance (%)',
col = ifelse(coef_top10[ ,2] > 0, 'red', 'blue'))
结果中已经根据红外光谱变量的相对重要性,按高值往低值排列。图中蓝色代表了回归系数是负值的光谱变量,红色代表了回归系数是正值的光谱变量。
importance代表了所有红外光谱变量的相对重要性百分比,它们的总和为100。可以据此挑选感兴趣的光谱变量,后续尝试查看只使用少数一组更重要光谱变量的PLS回归模型是否也能较好地预测涤纶纱密度,如果可行,则提示后续可以只需测量这几种特定波长下的红外光谱就能很好的检测涤纶纱密度。
coefficients为这些变量在PLS回归中的回归系数,回归系数绝对值高的变量具有更高的相对重要性百分比。对于负值的回归系数,解释为随着红外光谱测量值的增加,代表着涤纶纱密度的降低;对于正值的回归系数,解释为随着红外光谱测量值的增加,代表着涤纶纱密度的增高。
偏最小二乘判别分析(PLS-DA)
上述过程,响应变量是一组连续变量的情况,PLS执行回归的功能。
当响应变量是一组类别型变量时,此时PLS用于执行监督分类的功能,也就是众所周知的偏最小二乘判别分析(Partial least squares Discriminant Analysis ,PLS-DA)。
关于PLS-DA的简述及R语言计算,可参考前文“”。
参考资料
以上是关于R语言 | R包pls的偏最小二乘(PLS)回归的主要内容,如果未能解决你的问题,请参考以下文章