技术贴 | R语言:envfit环境因子和菌群回归分析
Posted 微生态
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术贴 | R语言:envfit环境因子和菌群回归分析相关的知识,希望对你有一定的参考价值。
点击蓝字↑↑↑“微生态”,轻松关注不迷路

本文由阿童木根据实践经验而整理,希望对大家有帮助。
原创微文,欢迎转发转载。
利用"基于菌群数据的样本排序"/"样本排序坐标"与环境因子进行多元回归可以分析环境因子与物种组成是否有显著的线性关系。计算样本排序排序有两种方法:一、约束性排序法有RDA、CCA等;二、非约束排序PCA、CA、PCoA、NMDS等。如果约束排序分析结果中环境因子的解释程度偏低,这时可以考虑使用非约束排序的方法再次分析。
分析思路可以是:1. 利用bray-curtis算法计算样本之间的距离,然后用R cmdscale进行多维尺度变换[multidimensional scaling, MDS]获得所有样本的样本排序ordination,也就是样品的mds1 mds2坐标[衡量样品variation或菌群结构],接着用回归函数envfit进行环境因子(观测变量)与ordination(非约束性轴)之间的回归拟合分析,permutation计算显著性P值,获取相关数据和绘图。最后根据R方和P值分析判断环境因子与菌群结构是否有显著的线性关系。
一、 模拟输入
菌群丰度数据
set.seed(1995)
# 随机种子
genus=matrix(abs(round(rnorm(200, mean=20, sd=5))), 50, 4)
# 随机正整数,5行,4列
colnames(genus)=paste("genus", 1:4, sep=".")
# 列名
rownames(genus)=paste("sample", 1:50, sep=".")
# 行名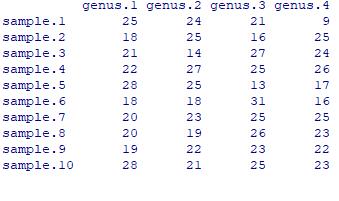
环境因子数据:
set.seed(1996)
# 随机种子
env=matrix(abs(round(rnorm(200, mean=20, sd=5))), 50, 4)
# 随机正整数,5行,4列
colnames(env)=paste("env", 1:4, sep=".")
# 列名
rownames(env)=paste("sample", 1:50, sep=".")
# 行名
group=c(rep("G1", 25), rep("G2", 25))
# 模拟分组
env=data.frame(env, group)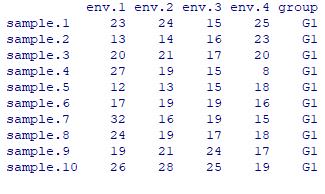
二、计算ordination、mds
library(vegan)
# 加载R包:vegan
ord=cmdscale(vegdist(genus, method="bray"))
# 计算样品间的bray curtis距离,并将距离转成ordination
colnames(ord)=c("mds1", "mds2")
# 重命名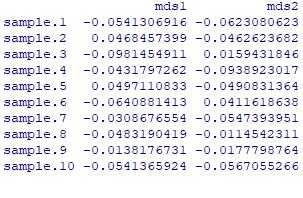
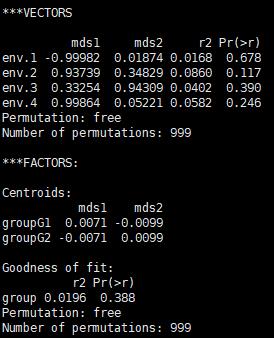
三、envfit拟合、绘图
回归拟合分析:
fit=envfit(ord, env, perm=999)
绘图:
plot(ord, pch=16, col=env$group)
legend("topright", c("G1", "G2"), col=c("black", "red"), text.col=c("black", "red"), pch=c(19, 19))
plot(fit, col=c("blue", "purple", "green"))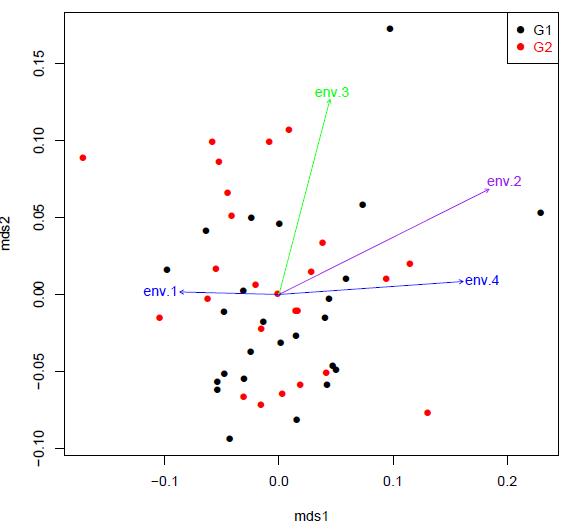
 你可能还喜欢
你可能还喜欢
1
4
5
微生态科研学术群期待与您交流更多微生态科研问题
(联系微生态老师即可申请入群)
了解更多菌群知识,请关注“微生态”。
以上是关于技术贴 | R语言:envfit环境因子和菌群回归分析的主要内容,如果未能解决你的问题,请参考以下文章