R语言运行太慢怎么办?这几招大幅提升你的运行速度!
Posted 挑圈联靠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言运行太慢怎么办?这几招大幅提升你的运行速度!相关的知识,希望对你有一定的参考价值。
扫描下方二维码免费领取☟☟☟
如何使我们的R运行更快呢?可能很多小伙伴在用R语言处理大数据的时候都可能出现过换电脑的想法,想着我肯定换一个更高级的电脑,那么我的R跑起代码就像飞翔在云端一样,可以藐视众生,可是有些时候真的是我们电脑的问题吗?那还真的不一定,今天小编就带大家一起去看一下到底R语言中有哪些问题限制了我们跑代码的速度以及如何优化我们的代码让R跑起来更快,也希望这篇文章能为大家在接下来的生信下篇学习中提供一些检测代码运行速度慢的方法。

1.microbenchmark包比较各种不同函数读取文件的速度
很多时候我们在R里面读取大数据的时候总是会出现卡顿,但是很多小伙伴每次都不知道到底哪个读取函数更加快。其实我们只需要使用microbenchmark函数就可以去比较几种读取文件的方式哪个更快,再也不用每次都去死记硬背到底哪个更快。
举个例子
library("microbenchmark")a <- read.csv2("TCGA-LUSC.htseq_fpkm.txt")b <- read.csv("TCGA-LUSC.htseq_fpkm.txt")microbenchmark(a,b,times = 1)#times指的是读取速度
用read.csv2和read.csv读取同一个文件,经过microbenchmark函数测量每个读取两次(times设置读取次数),发现read.csv比read.csv快了两倍
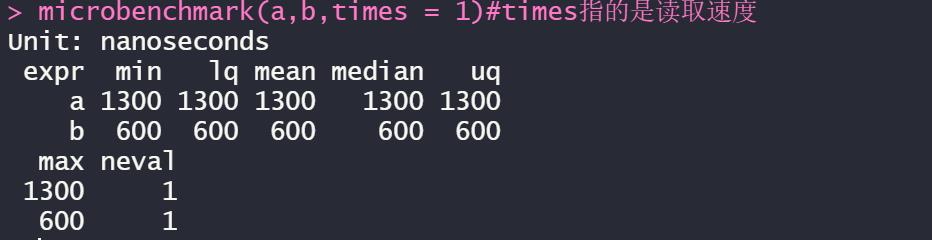
这还仅仅只是300多兆的小文件,如果以后做生信分析的时候,特别是纯代码的生信下篇,读取的文件可能比这个要大很多,所有我们选择read.csv读取的话速度就会快很多。通过microbenchmark函数我们就不用记忆到底哪个函数读取更快,实际操作的时候用一个小文件读取来测试一下,这样就可以帮助我们选择正确的读取函数,从而使R运行更快。
2.R语言编程方式让R运行更快
1
不要去让一个向量在计算中不断延长
举个例子
n <- 30000growing <- function(n){x <- NULLfor(i in 1:n)x <- c(x, rnorm(1))}system.time(res_grow <- growing(30000))
这是R里面典型的慢代码,因为x在计算中会形成一个不断增长的向量,这样对于R的处理就会非常浪费时间

那如何进行优化呢?我们可以改变我们的代码的写法,就是我们不要在每次计算x值的时候都要读取上一次的x值,并且将每次x的值都预先指定,然后在循环的过程中得到的值去不断替代原来的值:
x <- 30000pre_allocate <- function(n){x <- numeric(n)for (i in 1:n)x <- rnorm(1)}system.time(res_allocate <- pre_allocate(30000))

2
尽可能使用向量来解决问题让代码运行更快
#向量化编程是R语言比较有特色的思想,它可以简化我们写的复杂的代码,从而把我们从代码世界解救出来,所有我们应该熟悉R的向量化编程思想 。
举个例子
x <- rnorm(10)x2 <- numeric(length(x))for(i in 1:10)x2[i] <- x[i] * x[i]
这种for循环式代码是学过python的人会打出来的代码,但是在R里面使用向量化编程的思想可以很简单的解决这个问题
x2_mul <- x * x是不是感觉向量化编程简直太简洁了,轻轻松松把别人敲了很多的代码一行搞定
3.充分利用计算机的多芯片
首先我们使用parallel包的detectCores()函数看一下自己的计算机有几块芯片
library(parallel)detectCores()

可以看到小编自己的电脑有8块芯片,相信各位小伙伴的芯片肯定也不止一块,那么我们可以思考一下,我们是否可以使用8块芯片去独立处理8个不同的任务,这样计算机的性能就被我们开发了8倍,而且计算机也不用散热扇飞速旋转啦,答案当然是可以的,不过也需要一定的条件。这里有小伙伴可能会问R语言自己不会灵活使用多块芯片来处理问题嘛?答案当然是否定的,R语言默认只能使用一块芯片来处理,不过我们可以指定它让它进行多块芯片同时处理问题
举个例子
df <- as.data.frame(matrix(1:8e+6, ncol = 8))cl <- makeCluster(8)2, median)stopCluster(cl)

这里小编使用8块芯片去分别计算8列的均值,虽然在小数据上体现不了太大的差别,但是生信分析都是为大数据而生,一旦数据量上去了,多芯片计算的优势就出现了。但是多芯片的使用有一定条件,那就是多块芯片处理数据的独立性,也就是各块芯片处理的数据互相独立,因为计算机分配给每块芯片处理的时候是没有顺序的,所有各个芯片必须是独立的任务。
4.发现代码运行的瓶颈能够更好的优化代码
在平时我们写好代码运行的时候或者在生信下篇运行代码的时候,我们可能总会出现卡断的现象,而且有可能还很久都卡不出来,一直在运行中,这时候要是我们知道自己代码运行到底哪儿慢就好了,因为这样就可以对代码进行针对性的向老师提问和修改。接下来小编给大家介绍profvis包,直接使用包中的profvis()函数就是可以看到运行中哪一步代码比较费时,并且做出相应的修改
data(diamonds, package = "ggplot2")plot(price ~ carat, data = diamonds)m <- lm(price ~ carat, data = diamonds)abline(m, col = "red")

直接选中要测试的代码,然后按住快捷键ctrl+Alt+shift+p就可以对代码进行测试,然后就可以看到每一步代码运行的时间,就能找出突破代码运行速度的瓶颈。
5.如何用R语言去看电脑是否需要更换?
如何在R里面测试电脑性能,看电脑是否真的需要更换了呢?这时候Benchmark包就出场了,Benchmark包能够提供一系列标准的数据让你运行,并将运行的结果和其他的用户进行比较,从而得出你计算机的相对性能。
举个例子
library("benchmarkme")res_io = benchmark_io(runs = 1, size = 5)upload_results(res_io)plot(res_io)
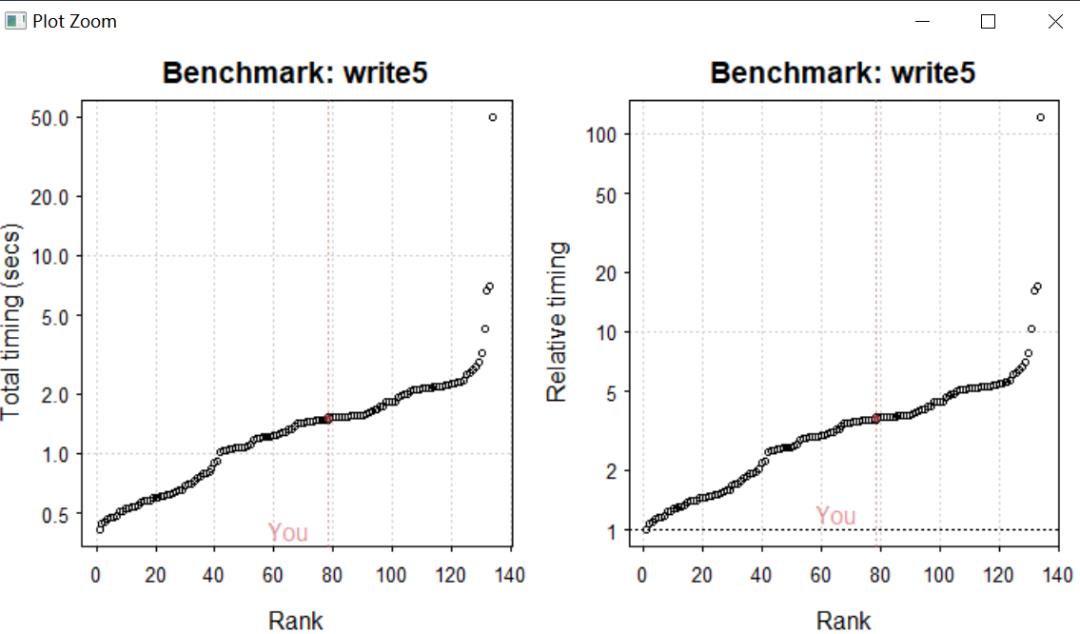
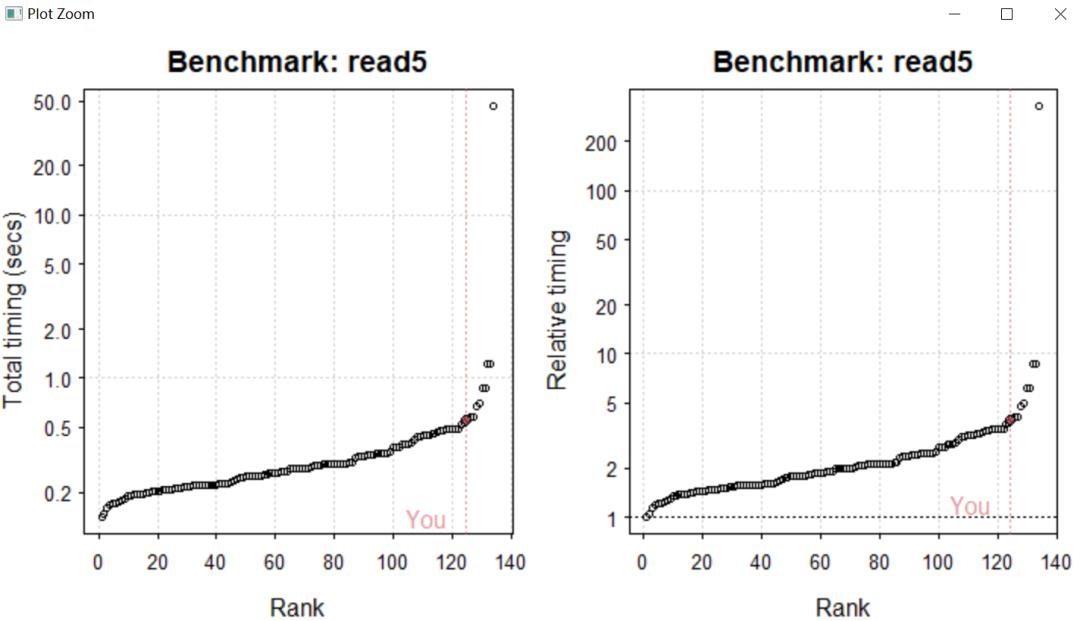
通过读写一次一个5M的标准文件(如果你的RAM少于4GB的话,介意只读写一次),我发现我的电脑读写(I/O)排在了运行同样代码计算机的一半左右,说明小编的计算机还是可以的,至少在读写5M的数据的话是不需要换电脑的,如果想测试大数据电脑的运行速度,则将size = 50,测试写50M的时候电脑的速度。
此外benchmark包还可以对计算机的CPU性能进行检测
举个例子
res = benchmark_std(runs = 1)upload_results(res)plot(res)
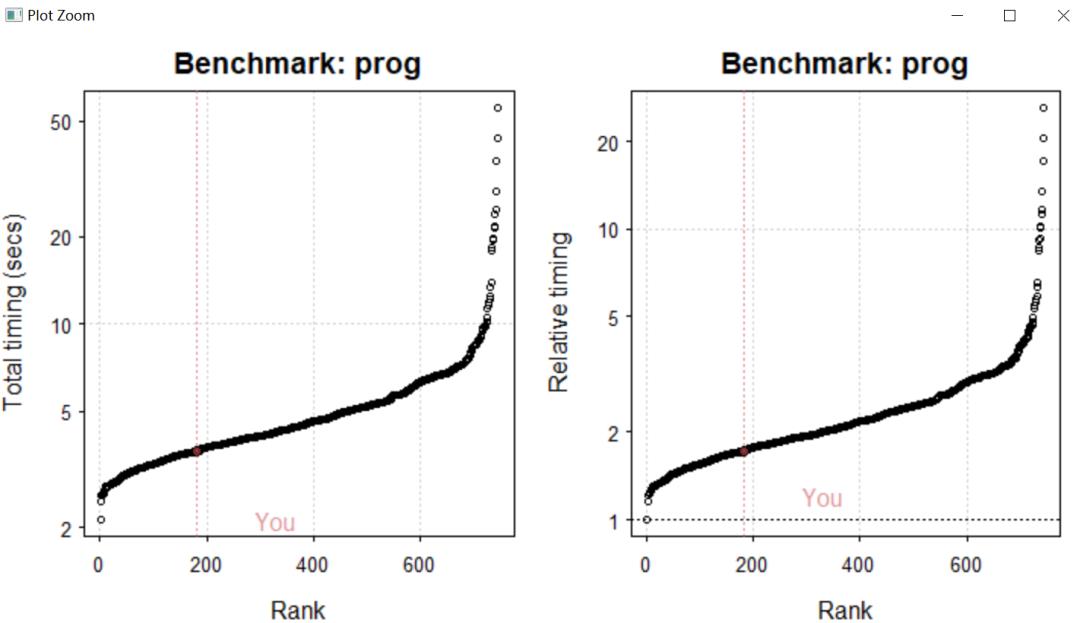
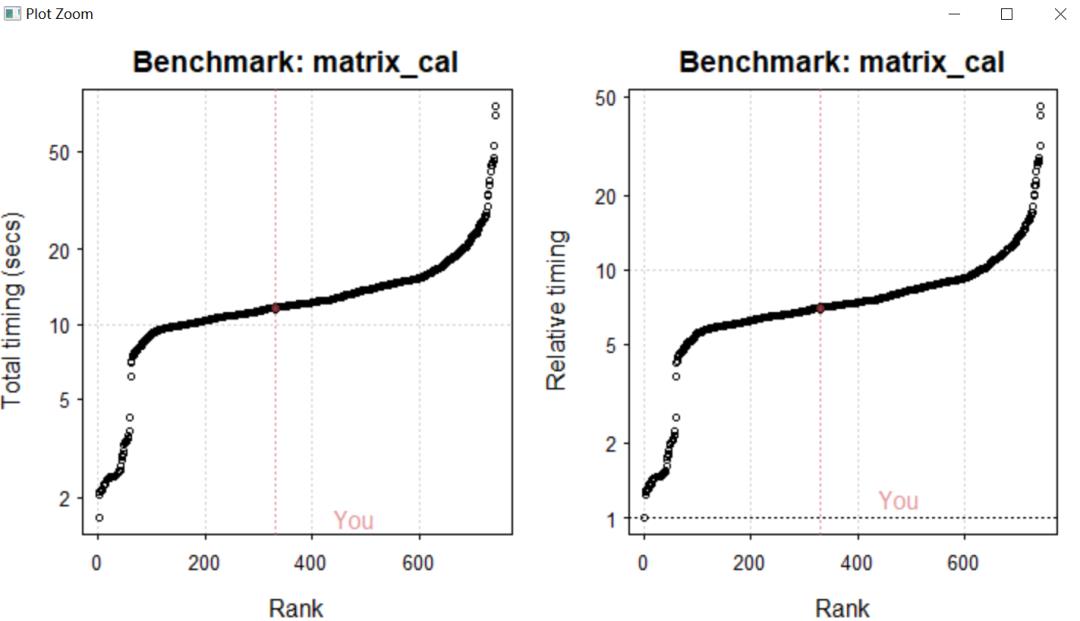
检测发现小编的电脑的CPU还是可以的,处理速度位于中等偏上,说明小编现在还不需要换电脑,足以应付数据的处理。小伙伴们都可以使用benchmark包进行检测自己的计算机,然后去看自己计算机处理的性能到底是怎样的,才去决定有没有必要去更新一台新的计算机。
小福利
install.packages("swirl")library("swirl")swirl()
只需要运行上面代码就可以在RStudio里面进行一边操作一边学习R的知识,真的比看纸质书学习要快很多,而且记得非常牢固。

以上是关于R语言运行太慢怎么办?这几招大幅提升你的运行速度!的主要内容,如果未能解决你的问题,请参考以下文章