R语言:时间序列经典分析法
Posted 易学统计
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言:时间序列经典分析法相关的知识,希望对你有一定的参考价值。
题记:本文是个人的读书笔记,仅用于学习交流使用。本文将深入研究时间序列技术。
01
解决什么问题?
前面一章,介绍了时间序列中涉及到的基本概念,本章将在此基础上介绍如何对时间序列的资料进行分析,怎么选择合适的模型。时间序列的分析方法,已经给大家整理出一个流程图,如下图。本章介绍时间序列经典分析法。
02
时间序列组分分解法
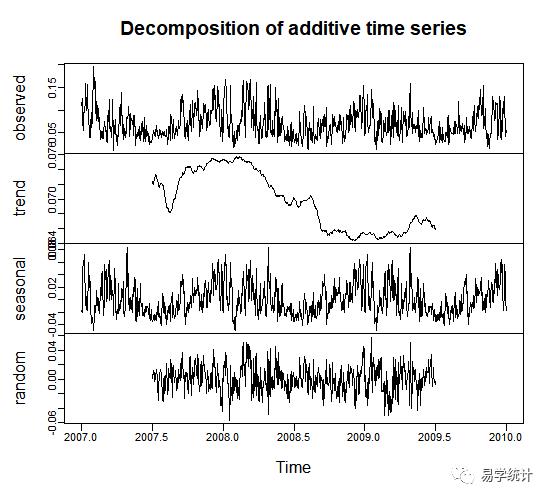
根据前文中,时间序列是四大影响因素的综合影响结果(长期趋势,循环周期,季节变动和不规则变动,),在各个分量按照加性组合的假定下,对加性模型各分量进行分解,R中使用decompose()函数将各分量分解。下图为使用加性效应关系绘制的分解图。
下图,从上往下分别是原图,长期趋势,季节变动和不规则随机变动图。长期趋势有下降的趋势;季节分量反应有年度变化周期;随机分量曲线绕着0水平波动。
03
趋势拟合法
时间序列中的确定性趋势和季节变动可以用线性回归模型识别,但时间序列的回归模型不同于标准回归模型,因为残差之间存在自相关性,本质上也是一个时间序列,因此这类模型要仔细检查残差。
1.线性回归拟合
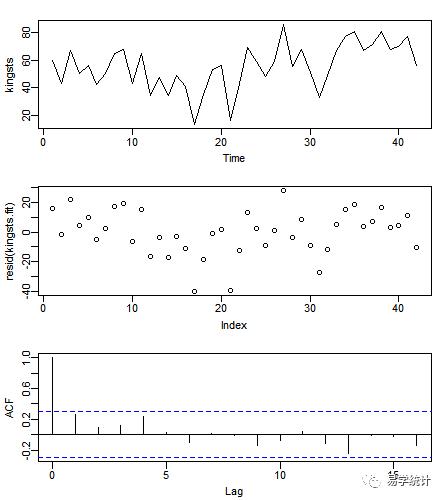
###书籍集为每年国王的寿命kingsts <- ts(kings) ##转成时间序列格式len <- length(kingsts)t <- seq(1,len)/10 ##产生有序变量kingsts.fit <- lm(kingsts~t) ##配合最小二乘法回归模型summary(kingsts.fit) ##输出主要计算结果par(mfrow=c(3,1),mar=c(3,3,1.6,1),mgp=c(1.8,0.5,0))plot.ts(kingsts) ##绘制时间序列图plot(resid(kingsts.fit),cex.axis=0.8,cex.lab=0.8) ##画出残差图acf(resid(kingsts.fit),cex.axis=0.8,cex.lab=0.8) ##做残差的acf图Box.test(kingsts.fit.fit$residuals) ##对残差做检验## p-value = 0.08575
2.曲性回归拟合
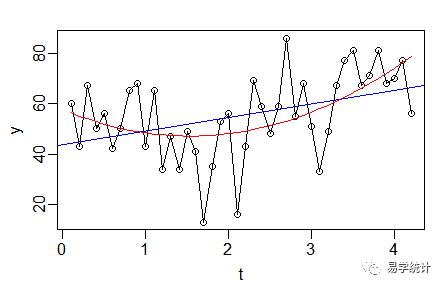
kingsts.fit1 <- lm(kingsts~t+I(t^2)) ##二次拟合summary(kingsts.fit1) ##调整R2=0.2542summary(kingsts.fit) ##调整R2=0.1419Box.test(kingsts.fit1$residuals) ##p-value = 0.4331acf(kingsts.fit1$residuals) ##无相关性
3.结果解释
1.国王寿命的数据作图(上上图1),可看到有一个先下降后上升的长期趋势,因此可以做趋势拟合。
2.先配合一阶回归模型,并对拟合的模型做残差检验,分别用acf()和Box.test()函数检验(上上图2和3)。可看到残差图没有任何趋势,残差相关图无相关性,残差检验的P值大于0.05,也证实无相关性。
3.根据其数据先下降后上升的趋势,可以尝试拟合下二次曲线,并对拟合完的模型残差检验,其残差没有相关性,且比对第一个模型和第二个模型的调整R2发现,第二个模型的R2更大,说明二次曲线更适合这个数据,上图的蓝色线为拟合的直线模型,红线为拟合的曲线模型,看上去曲线模型拟合更好。
04
平滑法
根据不同的历史间隔远近在预报中所起的作用不同而给予不同的权重,历史较近的观察值对当前值影响较大,应给予较大的权重;反之,历史较远的观察值对当前值的影响较小,应赋予较小的权重。该方法特别适合变化比较缓慢的时间序列资料的分析。
简单指数匀滑法适合不含趋势和季节变动资料,Holt-Winters法则是将简单指数匀滑推广到含有趋势和季节变动的时间序列资料的分析。在R中都采用HoltWinter()函数分析,其具有下面的基本结构:
HoltWinters(x, alpha = NULL, beta = NULL, gamma = NULL,seasonal = c("additive", "multiplicative"),start.periods = 2, l.start = NULL, b.start = NULL,s.start = NULL,optim.start = c(alpha = 0.3, beta = 0.1, gamma = 0.1),optim.control = list())
函数中的x为时间序列资料的名称,alpha为水平参数α,beta为趋势参数β,gamma为季节参数γ。当beta和gamma都赋值为FALSE时,模型就没有趋势分量和季节分量,也就是简单指数匀滑法。当gamma赋值为FALSE时,模型就没有季节分量。
简单指数匀滑法
空气中颗粒物PM10数据集为例pm10.ts <- ts(pm_10$PM10,start = c(2007,1),frequency = 365)pm10.ts.hw <- HoltWinters(pm10.ts,gamma = F,beta = F)coef <- pm10.ts.hw$coefficientswith(pm10.ts.hw,c(alpha,beta,gamma,coef,SSE))

不含季节趋势指数匀滑
pm10.ts.hw.NS <- HoltWinters(pm10.ts,gamma = F)coef <- pm10.ts.hw.NS$coefficientswith(pm10.ts.hw.NS,c(alpha,beta,gamma,coef,SSE))
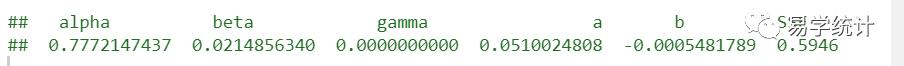
包含长期趋势和季节趋势的Holt-Winters匀滑
pm10.ts.hw.S <- HoltWinters(pm10.ts)coef <- pm10.ts.hw.S$coefficients[1:2]with(pm10.ts.hw.S,c(alpha,beta,gamma,coef,SSE))##提取匀滑参数和当前基础水平a和趋势分量bpm10.ts.hw.S$coefficients[c(3:6,365+2)]##提取前4个和最后一个季节的匀滑参数s


上述三个不同模型的结果解释:
1.该序列没有明显的长期趋势,但可见明显的季节周期,这里为了和后面对比,因此姑且以此数据作为例子进行简单指数平滑。其水平参数α=0.73,说明某一天的pm10浓度受近期的影响比较大。其趋势和季节参数为0,SSE为0.57。
2. 第二部分,仍以该例子,假使其没有季节分量gamma=F。看到β=0.02,说明其长期趋势不明显。SSE=0.59
3.第三部分,考虑长期趋势和季节变动,看到α=0.61,表明近期污染水平对当前值影响大于远期污染水平。β=0表明趋势分量不需要随时间更新,γ=0.7,该序列存在明显季节周期。a=0.082是当前的基础水平,b=-1.1699e-06是当前的趋势,s1,s2等则是每天的季节指数。输出的SSE=0.52,误差低于前面两个模型,该模型构建比较合适。
采用Holt-winters法的加性模型配合时间序列资料的图形见下图:
plot(pm10.ts.hw.S$fitted) ##加性模型拟合图 图中xhat 为用模型参数估计值回代所得的期望值;level为水平值图,即稳定部分的估计值;trend为时间趋势图,结果未显示趋势,故为一条平行线;season为季节分量图,显示两个周期。2008-2009和2009到2010,预报未来一年的pm10含量图形见下图。
pm10.ts.hw.S.pre <- predict(pm10.ts.hw.S,365)ts.plot(pm10.ts,pm10.ts.hw.S.pre,lty=1:2)
上图中2007-2010年的实线部分为观察值,2010-2011年的虚线部分为预测值。
05
总结
本文作为时间序列的第二章,主要介绍经典时间序列的分析方法,包括组分分解,趋势拟合和平滑法,详细介绍HoltWinter()函数的使用和结果解读,趋势拟合的缺点要有长期稳定趋势,而在商业和经济中往往只有一段线性特征,这种情况要用随机时间序列分析,后面的ARMA模型。
06
参考文献
彭晓武等.R软件及其环境流行病学应用.中国环境出版社
Jonathan D.Cryer .时间序列分析及应用.机械工业出版社
Cory Leismester.精通机器学习:基于R.人民邮电出版社
作者介绍:医疗大数据统计分析师,擅长R语言。
欢迎各位在后台留言,恳请斧正!
更多阅读:
以上是关于R语言:时间序列经典分析法的主要内容,如果未能解决你的问题,请参考以下文章