R语言 | 数据操作dplyr包
Posted 大邓和他的Python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言 | 数据操作dplyr包相关的知识,希望对你有一定的参考价值。
dplyr简介
dplyr是R语言的数据分析包,很像python中的pandas,能对dataframe类型的数据做很方便的数据处理和分析操作。最初我也很奇怪dplyr这个奇怪的名字,我查到其中一种解释
-
d代表dataframe -
plyr是英文钳子plier的谐音
library(tidyverse)
## ── Attaching packages ────────────────────────────────────── tidyverse 1.3.0 ──
## ✓ ggplot2 3.3.1 ✓ purrr 0.3.3
## ✓ tibble 3.0.1 ✓ dplyr 1.0.0
## ✓ tidyr 1.1.0 ✓ stringr 1.4.0
## ✓ readr 1.3.1 ✓ forcats 0.5.0
## ── Conflicts ───────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()
tidyverse::tidyverse_packages()
## [1] "broom" "cli" "crayon" "dbplyr" "dplyr"
## [6] "forcats" "ggplot2" "haven" "hms" "httr"
## [11] "jsonlite" "lubridate" "magrittr" "modelr" "pillar"
## [16] "purrr" "readr" "readxl" "reprex" "rlang"
## [21] "rstudioapi" "rvest" "stringr" "tibble" "tidyr"
## [26] "xml2" "tidyverse"
读取数据
tidyverse含有readr,所以不用导入readr
#用readr包导入csv数据
aapl <- readr::read_csv('data/aapl.csv')
## Parsed with column specification:
## cols(
## Date = col_character(),
## Open = col_double(),
## High = col_double(),
## Low = col_double(),
## Close = col_double(),
## Volume = col_double()
## )
aapl
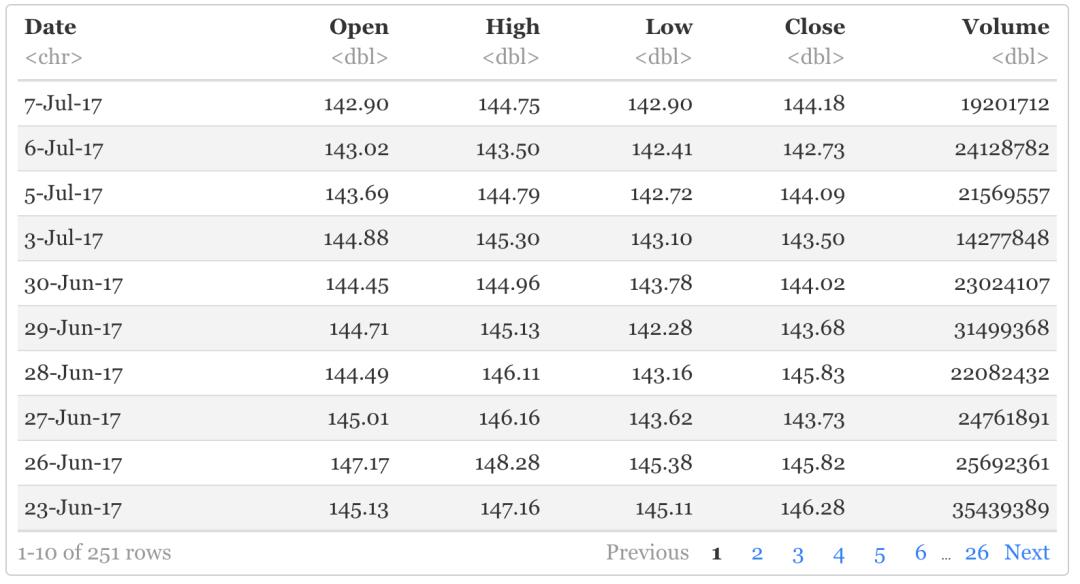
查看数据基本信息
这里使用的是R语言的基本函数,不用导入包就可以使用
数据类型
class(aapl)
## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"
字段
colnames(aapl)
## [1] "Date" "Open" "High" "Low" "Close" "Volume"
记录数、字段数
dim(aapl)
## [1] 251 6
前5条记录
head(aapl, n=5)

查看dplyr用例
vignette("dplyr")
## starting httpd help server ... done
dplyr常用函数
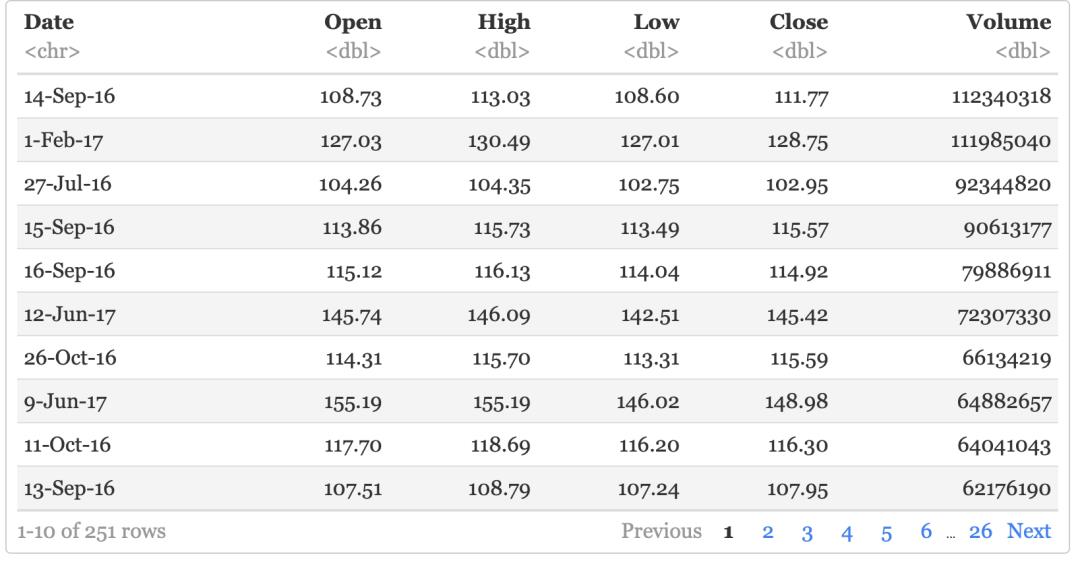
Arrange
对appl数据按照字段Volume进行降序排序。为了写作方便,我就不再写完整的调用,在这里arrange()代替 dplyr::arrange()
library(dplyr)
#dplyr::arrange(aapl, -Volume)
arrange(aapl, -Volume)
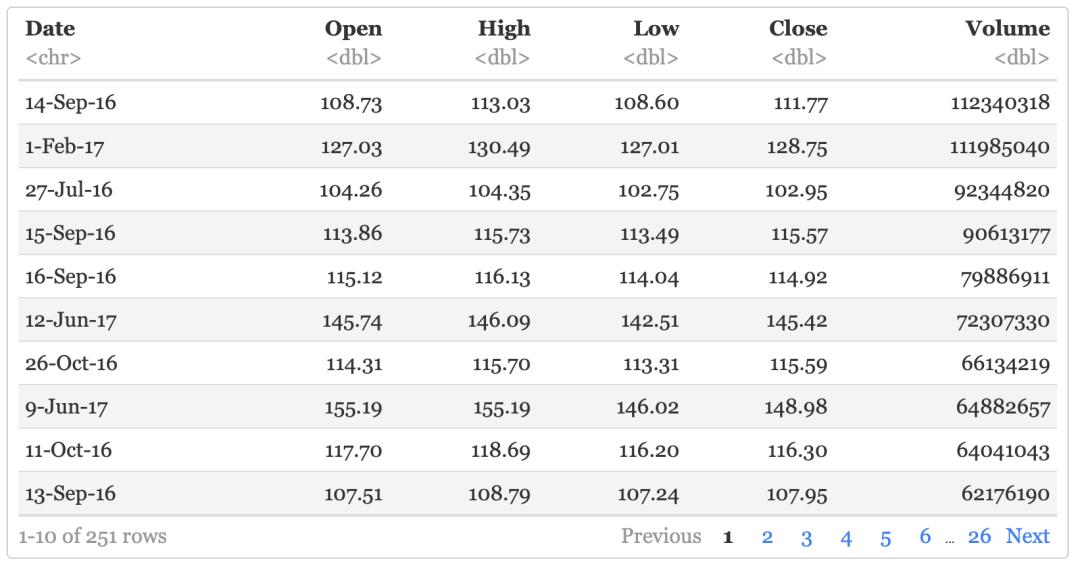
管道符 %>%
在dplyr中,有一个管道符%>%,符号左侧表示数据的输入,右侧表示下游数据处理环节。
我们可以用管道符 %>% 改写上面的代码,两种写法得到的运行结果是一致的,用久了会觉得管道符 %>% 可读性更强,后面我们都会用 %>% 来写代码。
aapl %>% arrange(-Volume)
Select
选取 Date、Close和Volume三列
aapl %>% select(Date, Close, Volume)
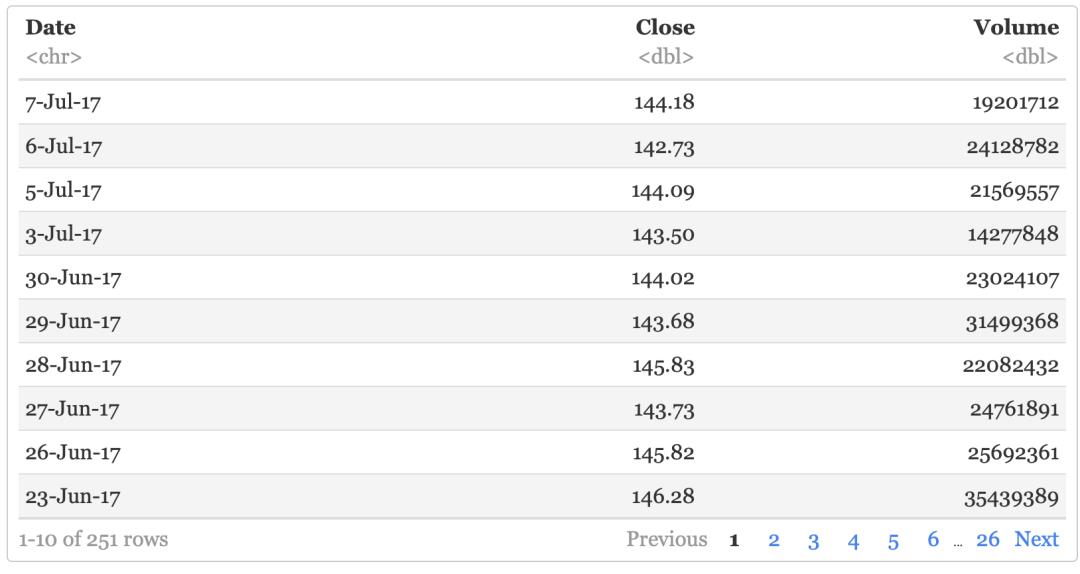
只选取Date、Close和Volume三列,其实另外一种表达方式是“排除Open、High、Low,选择剩下的字段的数据”。
aapl %>% select(-c("Open", "High", "Low"))
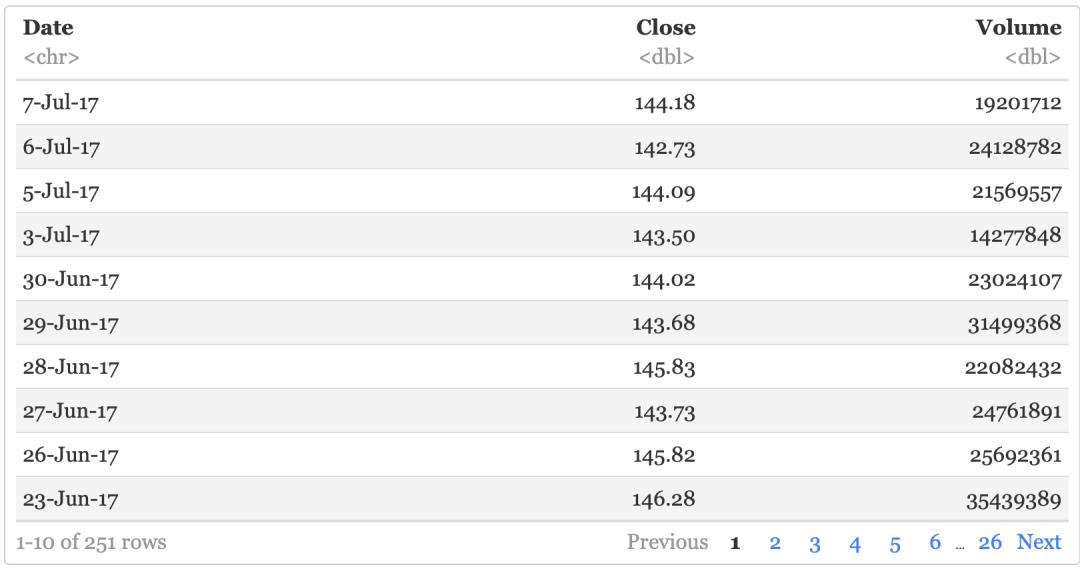
Filter
按照筛选条件选择数据
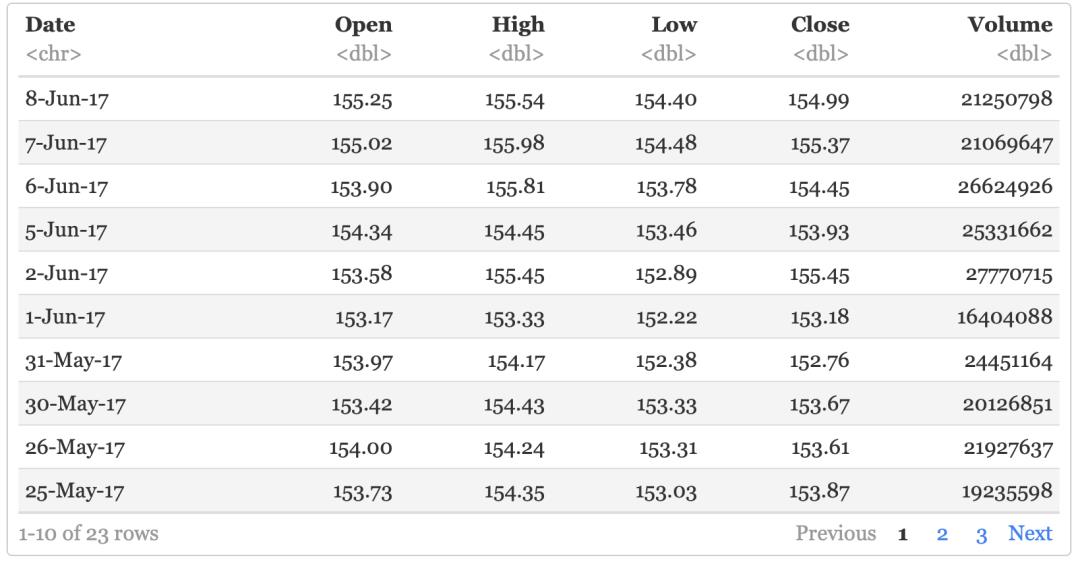
#从数据中选择appl股价大于150美元的交易数据
aapl %>% filter(Close>=150)
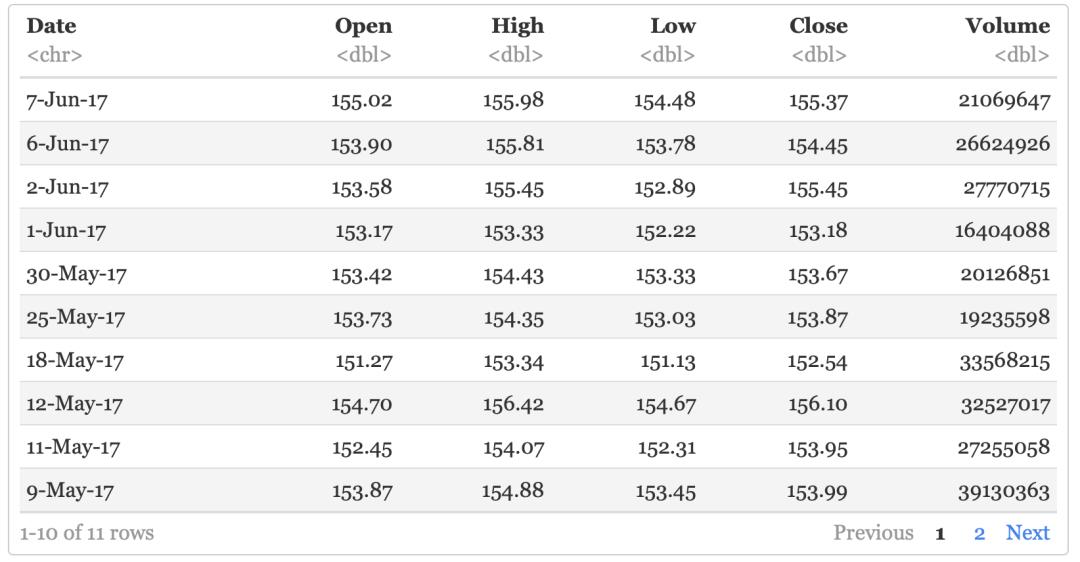
从数据中选择appl
-
股价大于150美元 且 收盘价大于开盘价
的交易数据
aapl %>% filter((Close>=150) & (Close>Open))
Mutate
将现有的字段经过计算后生成新字段。
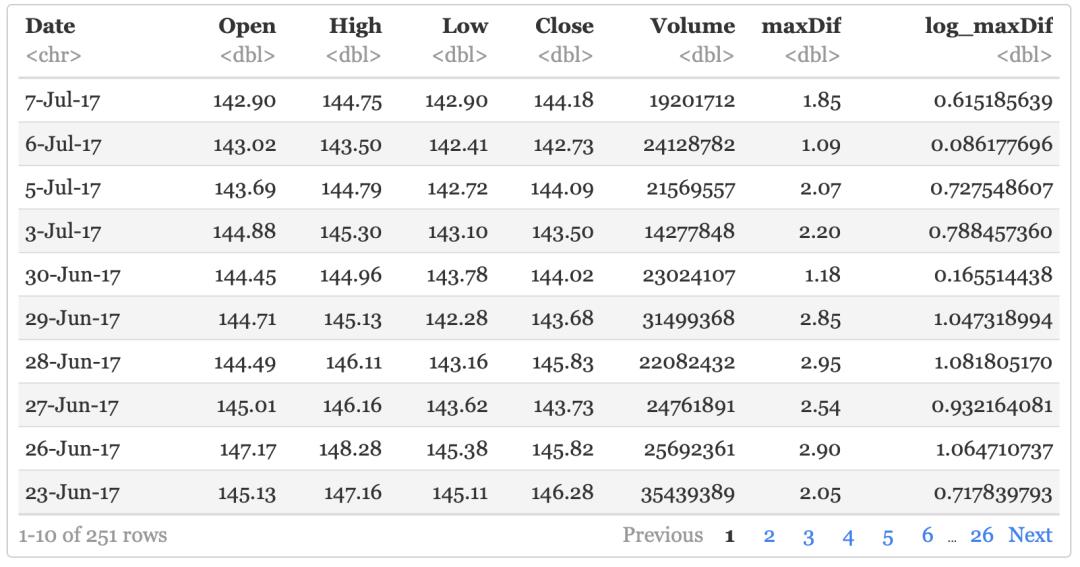
#将最好价High减去最低价Low的结果定义为maxDif,并取log
aapl %>% mutate(maxDif = High-Low,
log_maxDif=log(maxDif))
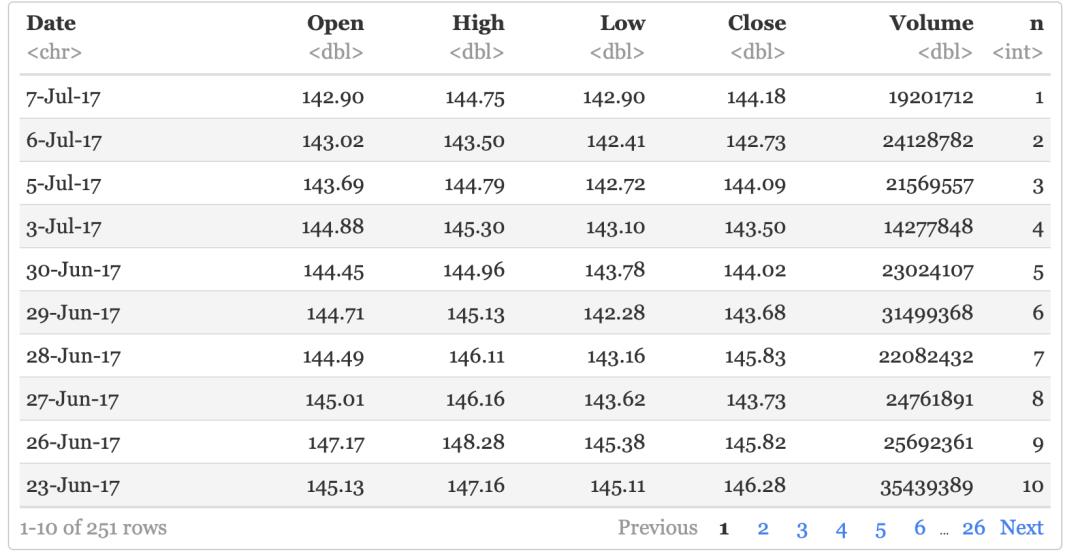
得到记录的位置(行数)
aapl %>% mutate(n=row_number())
Group_By
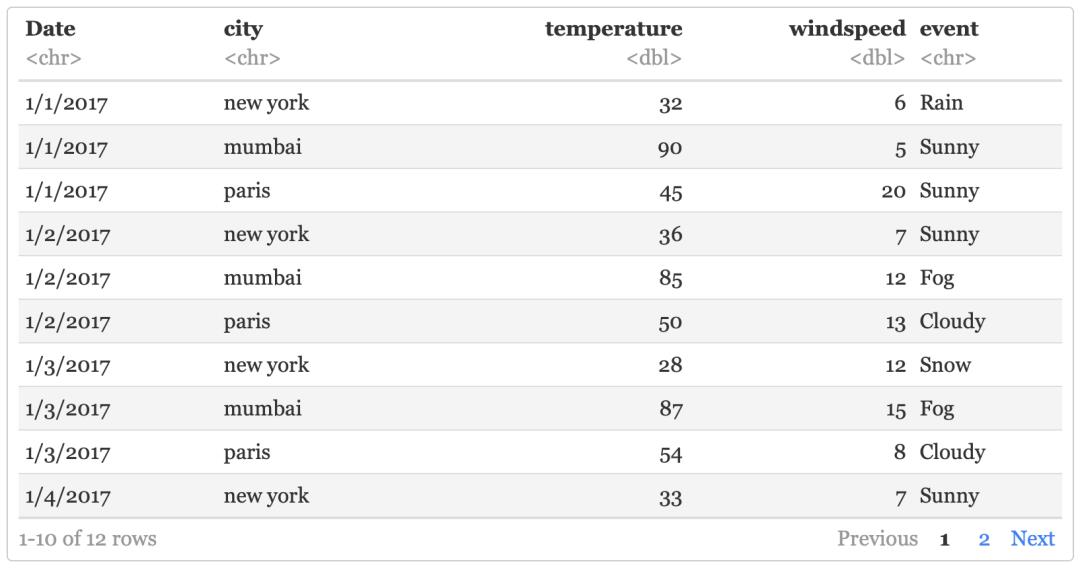
对资料进行分组,这里导入新的 数据集 weather
#导入csv数据
weather <- readr::read_csv('data/weather.csv') %>% as_tibble()
## Parsed with column specification:
## cols(
## Date = col_character(),
## city = col_character(),
## temperature = col_double(),
## windspeed = col_double(),
## event = col_character()
## )
weather
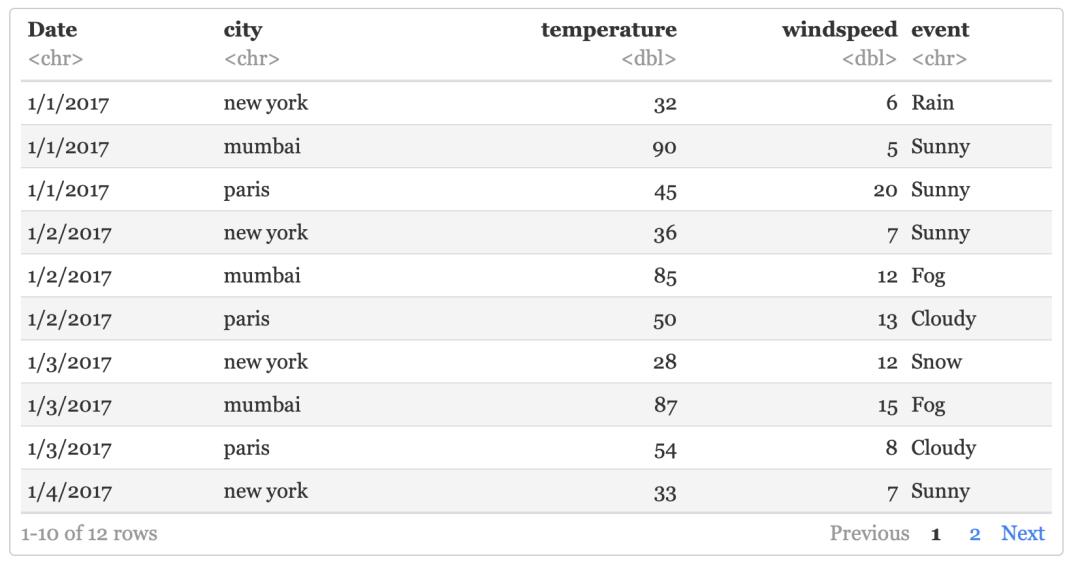
按照城市分组
weather %>% group_by(city)
为了让大家看到分组的功效,咱们按照城市分别计算平均温度
weather %>%
group_by(city) %>%
summarise(mean_temperature = mean(temperature))
## `summarise()` ungrouping output (override with `.groups` argument)
weather %>%
summarise(mean_temperature = mean(temperature))
R语言相关
近期文章
后台回复关键词【dplyr】获取本文代码和数据
以上是关于R语言 | 数据操作dplyr包的主要内容,如果未能解决你的问题,请参考以下文章
R语言dplyr包pull函数抽取dataframe数据列实战
R语言dplyr包combine()函数实现数据拼接(concatenate)实战
R语言dplyr包sample_n函数sample_frac函数数据采样实战
R语言dplyr包进行dataframe的连接(inner_joinleft_joinright_joinfull_joinsemi_joinanti_join)操作实战