R语言机器学习 | 8 决策树与集成学习
Posted PsychRun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言机器学习 | 8 决策树与集成学习相关的知识,希望对你有一定的参考价值。
本节介绍决策树(Decision Tree)算法及其衍生的集成学习算法,如Bagging、随机森林(Random Forest)、Adaboost(adaptive boosting)等。
1 决策树与回归树
决策树的概念非常直观,举个简单的例子,已知特征X包括:年收入、是否拥有房产、婚姻情况;现在要预测该个体能否偿还贷款(Y),也就是要预测的标签包括能偿还or不能偿还。利用决策树算法,可以计算出类似下面的树模型,通过不断地决策判断,得到最后的分类结果。
理论上,通过参数的调整,我们几乎可以通过类似的决策树,成功对样本中每一个个案进行正确分类,但是,如果决策树太过细节,会出现之前提到的过拟合(overfitting)现象,即在训练集中表现极为出色,但在测试集中表现不佳。因此,好的决策树算法并不会“枝繁叶茂”,而是会进行适当的“剪枝” (prune),使得该树模型有较好的泛化能力。
在上面这个例子中,标签Y是分类变量(能偿还or无法偿还),所以该模型叫做“决策树”,如果标签Y是连续变量(如:要偿还几个月),就会将这样的树模型叫做“回归树”。
同样,从上面的例子可知,特征X可以是分类变量(如是否有房产),也可以是连续变量(如年收入)。那么树模型如何生成呢?比如,如何判定哪个节点在上面,哪个节点在下面(变量选择),如何确定年收入的分类标准是97.5(参数设定)?一般而言,算法会利用基尼系数等度量指标,通过模型遍历,寻找出最优解。当然,具体如何生成、如何剪枝的数学原理在这里不做重点,因为从应用角度,利用已有算法可以直接轻松实现。
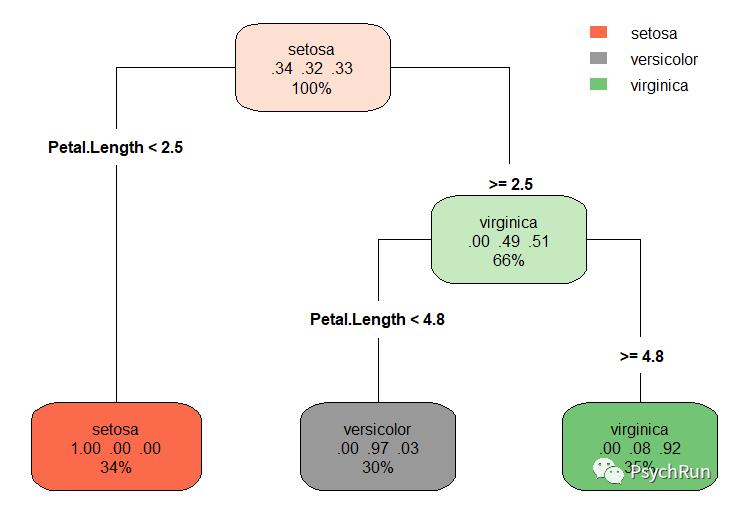
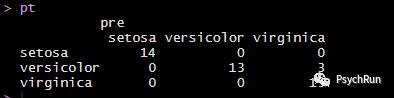
依然使用鸢尾花数据集作为例子,利用rpart包进行决策树学习,使用rpart.plot包进行画图。这里依然使用训练集-测试集的交叉验证方法,使用rpart()函数直接进行决策树训练,通过rpart.plot() 可以画出决策树的示意图。最后的混淆矩阵结果表明,决策树的预测正确率是93.33%。
#决策树library(rpart);library(rpart.plot);set.seed(100)index <- sample(nrow(iris),0.7*nrow(iris)) #在x里面抽size个样本;这里直接是抽index,以便接下来使用。train <- iris[index,]test <- iris[-index,]tree = rpart(Species~.,data = train,method = 'class')summary(tree)rpart.plot(tree,cex = 1,type = 4) #更改type可以更改图形样式pre = predict(tree,test,type = 'class') #利用决策树算法得到的预测值;type='class'输出的是预测类别;type='prob'是预测概率pt=(table(test$Species,pre)) #混淆矩阵pt
2 基于树的集成算法
基于树的集成算法(也叫组合算法),即通过一定的重抽样方法,生成N个决策树,从而进一步提升决策树算法的表现。常见的集成算法包括bagging、随机森林、adaboost等。下面所有的算法均是既可以做分类,也可以做回归。下面进行简单介绍。
Bagging算法是用决策树等算法结合bootstrap方法,得到许多棵决策树,从而提高预测精度,所以Bagging有时也被叫做bootstrap aggregating。
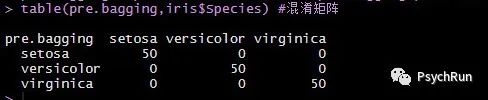
Bootstrap方法在心理学中也十分常用,简单来说,bootstrap是一种有放回的抽样,如实际上收集了N个数据,现在每次从这些样本里,有放回的抽取N个样本,由于抽取的随机性,会得到若干个(如1000个)新的样本集。之后,通过对这1000个样本集进行训练,可以得到1000棵决策树,再通过少数服从多数的“等权投票”进行集成,可以得到一个更强的学习器。比如,以性别分类为例,1000棵决策树里,有过半树认为分类为男性,则bagging的最后判断为男性。利用ipred包可以进行bagging学习,结果发现,bagging算法的分类正确率为100%!
# Bagginglibrary(ipred)M = bagging(Species~.,iris)summary(M) #可看到默认是bootstrap = 25pre.bagging = predict(M,iris) #预测值 pre.bagging$prob 是概率table(pre.bagging,iris$Species) #混淆矩阵
随机森林算法与bagging类似,但随机森林不光对样本进行bootstrap随机采样,也对变量进行抽样,因此随机森林中,每棵树可能长得都不一样(可见称之为森林很形象),最后同样根据少数服从多数进行决策。R中可以利用randomForest包进行随机森林算法,该算法默认是500棵树,最后混淆矩阵表明,分类正确率也是100%。
#随机森林(与 bagging类似,但它不光样本bootstrap抽样,变量也抽,也可以分类或回归)library(randomForest)set.seed(50)#因为有随机抽样,所以可以定个种子forest = randomForest(Species~.,data=iris) #默认500棵树pre.forest = predict(forest,iris,type = 'response') #预测值,type=response是分类,prob是概率table(pre.forest,iris$Species) #混淆矩阵print(forest)
Adaboost算法(adaptive boosting)也与bagging类似,也是通过有放回再抽样的不同样本建立许多棵决策树。但是在这个算法下,在第一课树之后,抽样不是等概率的,而是对前一棵树错判的观测值增加其被抽中的概率,这能够增加这些被错判的观测值的代表性。因此,Adaboost算法最后不是通过少数服从多数,而是通过“加权投票”判断结果,准确率高的树权重更大。可以想见,这样的计算量会是一般决策树的许多倍,因此在计算时通常需要一定时间。R中可以利用adabag包进行训练,最后混淆矩阵表明,分类正确率也是100%。
# Adaboostlibrary(adabag)ada = boosting(Species~.,data=iris)predict(ada,iris)$confusion #混淆矩阵 #predict(ada,iris)$prob 可导出预测值便于画ROCsummary(ada)importanceplot(ada) #变量重要性,描述哪些变量更重要
注:部分图片来源于网络,侵删。代码可参考资料b站R语言手把手系列。
以上是关于R语言机器学习 | 8 决策树与集成学习的主要内容,如果未能解决你的问题,请参考以下文章