R语言中Gibbs抽样的Bayesian简单线性回归
Posted 拓端数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言中Gibbs抽样的Bayesian简单线性回归相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=4612
贝叶斯分析的许多介绍都使用了相对简单的教学实例(例如,根据伯努利数据给出成功概率的推理)。虽然这很好地介绍了贝叶斯原理,但是这些原则的扩展并不是直截了当的。
这篇文章将概述这些原理如何扩展到简单的线性回归。我将导出感兴趣参数的后验条件分布,给出用于实现Gibbs采样器的R代码,并提出所谓的网格点方法。
贝叶斯模型
假设我们观察数据
对于我们的模型是
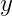
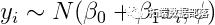
有兴趣的是作出推论
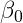
如果我们在方差项之前放置正态前向系数和反伽马,那么这个数据的完整贝叶斯模型可以写成:
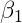
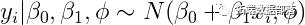
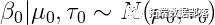
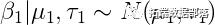
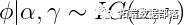
假设超参数
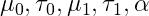 是已知的,后面可以写成一个常数的比例,
是已知的,后面可以写成一个常数的比例,
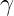
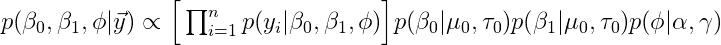
括号中的术语是数据或可能性的联合分布。其他条款包括参数的联合先验分布(因为我们隐含地假设独立前,联合先验因素)。
R代码的第0部分为该指定的“真实”参数从该模型生成数据。我们稍后将用这个数据估计一个贝叶斯回归模型来检查我们是否可以恢复这些真实的参数。
tphi<-rinvgamma(1, shape=a, rate=g)tb0<-rnorm(1, m0, sqrt(t0) )tb1<-rnorm(1, m1, sqrt(t1) )tphi; tb0; tb1;y<-rnorm(n, tb0 + tb1*x, sqrt(tphi))
吉布斯采样器
为了从这个后验分布中得出,我们可以使用Gibbs抽样算法。吉布斯采样是一种迭代算法,从每个感兴趣的参数的后验分布产生样本。它通过按照以下方式从每个参数的条件后面依次绘制:

可以看出,剩下的1,000个抽签是从后验分布中抽取的。这些样本不是独立的。绘制顺序是随机游走在后空间,空间中的每一步取决于前一个位置。通常还会使用间隔期(这里不做)。这个想法是,每一个平局可能依赖于以前的平局,但不能作为依赖于10日以前的平局。
条件后验分布
要使用Gibbs,我们需要确定每个参数的条件后验。
它有助于从完全非标准化的后验开始:
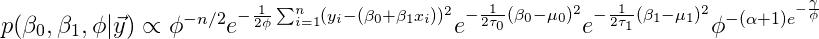
为了找到参数的条件后验,我们简单地删除不包含该参数的关节后验的所有项。例如,常数项
条件后验:
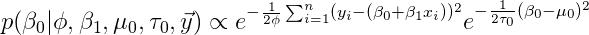
同样的,
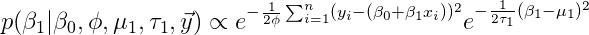
条件后验可以被认为是另一个逆伽马分布,有一些代数操作。
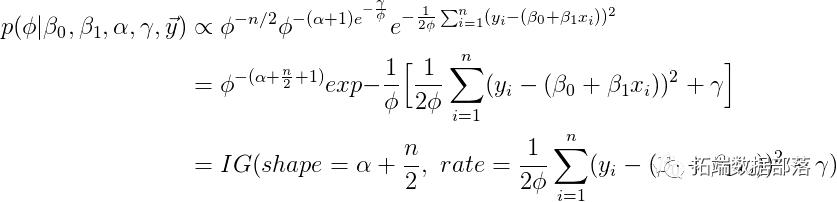
条件后验不那么容易识别。但是如果我们愿意使用网格方法,我们并不需要经过任何代数。
考虑网格方法。网格方法是非常暴力的方式(在我看来)从其条件后验分布进行抽样。这个条件分布只是一个函数。所以我们可以评估一定的密度值。在R表示法中,这可以是grid = seq(-10,10,by = .001)。这个序列是点的“网格”。
那么在每个网格点评估的条件后验分布告诉我们这个抽取的相对可能性。
然后,我们可以使用R中的sample()函数从这些网格点中抽取,抽样概率与网格点处的密度评估成比例。
for(i in 1:length(p) ){p[i]<- (-(1/(2*phi))*sum( (y - (grid[i]+b1*x))^2 )) + ( -(1/(2*t0))*(grid[i] - m0)^2)}draw<-sample(grid, size = 1, prob = exp(1-p/max(p)))
这在R代码的第一部分的函数rb0cond()和rb1cond()中实现。
使用网格方法时遇到数值问题是很常见的。由于我们正在评估网格中未标准化的后验,因此结果可能会变得相当大或很小。这可能会在R中产生Inf和-Inf值。
例如,在函数rb0cond()和rb1cond()中,我实际上评估了派生的条件后验分布的对数。然后,我通过从所有评估的最大值减去每个评估之前归一化,然后从对数刻度取回。
我们不需要使用网格方法来从条件的后面绘制。
因为它来自已知的分布
请注意,这种网格方法有一些缺点。
首先,这在计算上是复杂的。通过代数,希望得到一个已知的后验分布,从而在计算上更有效率。
其次,网格方法需要指定网格点的区域。如果条件后验在我们指定的[-10,10]的网格间隔之外具有显着的密度?在这种情况下,我们不会从条件后验得到准确的样本。记住这一点非常重要,并且需要广泛的网格间隔进行实验。所以,我们需要聪明地处理数字问题,例如在R中接近Inf和-Inf值的数字。
仿真结果
现在我们可以从每个参数的条件后验进行采样,我们可以实现Gibbs采样器。这是在附带的R代码的第2部分中完成的。它编码上面在R中概述的相同的算法。
iter<-1000burnin<-101phi<-b0<-b1<-numeric(iter)phi[1]<-b0[1]<-b1[1]<-6
结果很好。下图显示了1000个吉布斯(Gibbs)样品的序列。红线表示我们模拟数据的真实参数值。第四幅图显示了截距和斜率项的后面联合,红线表示轮廓。
z <- kde2d(b0, b1, n=50)plot(b0,b1, pch=19, cex=.4)contour(z, drawlabels=FALSE, nlevels=10, col='red', add=TRUE)
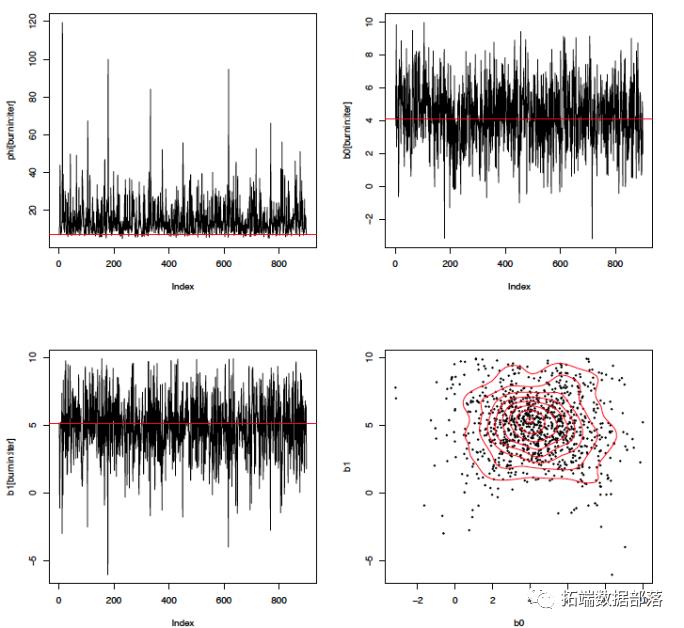
总结一下,我们首先推导了一个表达式,用于参数的联合分布。然后我们概述了从后面抽取样本的Gibbs算法。在这个过程中,我们认识到Gibbs方法依赖于每个参数的条件后验分布的顺序绘制。这是一个容易识别的已知的分布。对于斜率和截距项,我们决定用网格方法来规避代数。
点击标题查阅往期内容
更多内容,请点击左下角“阅读原文”查看


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看
以上是关于R语言中Gibbs抽样的Bayesian简单线性回归的主要内容,如果未能解决你的问题,请参考以下文章