R语言 | 分段线性回归及对分割点的评估选择及R计算
Posted 生物空间站
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言 | 分段线性回归及对分割点的评估选择及R计算相关的知识,希望对你有一定的参考价值。

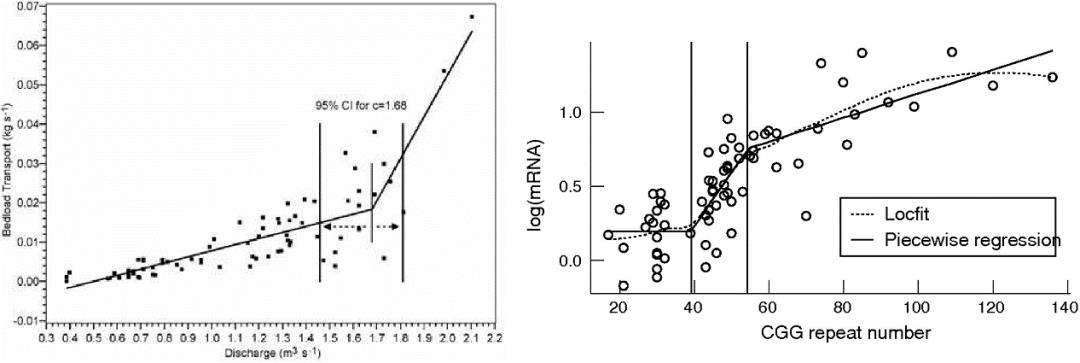
简单分段线性回归的简介
以只有一个断点的一元分段线性回归为例,断点两侧描述为不同的一元线性回归式,并在断点处将两条回归线连接构成一个整体连续的响应模型。例如下式展示了某种简单样式:
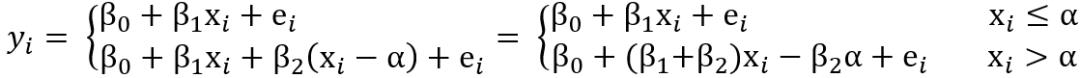
式中x为自变量,y为响应变量,α是断点(阈值),ei是独立的、平均误差为零、方差恒定、有限绝对矩的相加误差。xi是第i个自变量的值,当xi≤α,即自变量未超过断点阈值时,通过线性回归式β0+βixi+ei计算响应变量的估计值yi;当xi>α,即自变量越过断点阈值时,通过线性回归式β0+βixi+β2(xi-α)+ei计算响应变量的估计值yi。断点α两侧的两个线性回归的回归系数(斜率)分别为β1和β1+β2,β2可以解释为两个线性回归在斜率的差异。
由于两个线性回归之间存在断点,使得整体分段回归的一阶导数不连续,可能在很多常用的数值优化程序中出问题。为了避免这个问题,通常会在断点阈值α处添加一小段平滑曲线等使两个线性回归的拟合线在x=α处相交,即让它们在断点处具有强制的连续性,保证整体分段回归的一阶导数连续。
注意的是,尽管其称为分段线性回归,各分段内的局部回归均由线性回归式构成,但由于断点两侧描述了不同形式的变量响应,因此分段回归整体上体现了非线性的响应模式。
关于更复杂的分段回归类型
上述以只有一个断点的简单一元分段线性回归为例作了简介,由此拓展,更复杂的分段回归情况体现在:
(1)断点可以存在N(N≥1)个,不局限只有一个断点阈值;
(2)各分段区间内的子回归可以为任意类型,不局限于局部线性,也可以是非线性响应;
(3)自变量可以存在多个,即多元回归,并且对于每个自变量而言,允许存在不同的断点数量、断点阈值等;
(4)大多数分段回归中,会在断点处将两侧回归线强制通过平滑连接以使整体连续,但某些分段回归中不采取此措施,会出现整体不连续的情况。
总之各有各的特点,但复杂类型并不常见,因为难以解读,有时反而会将问题复杂化。对于复杂情形,还是在实际的文献阅读中体会要点最好,以帮助明确具体的应用情景。
分段线性回归的应用举例
例如在生态学研究中,经常涉及到生态阈值的问题。群落物种多样性或功能模式响应环境特征而改变,但这种响应并不是线性的,生态过程的突然变化可能发生在其中。在某环境梯度范围内,呈现出一种稳定的响应状态;但到达某特定的临界阈值后,可能伴随着剧烈的波动而出现另一种状态的响应。显然在该环境临界点两侧的不同梯度范围内,体现了不同的生态过程,如果在整个环境梯度内使用一种模型描述物种多样性或功能随环境的响应,或许不如分段描述更贴切。
时间尺度上也常应用分段回归描述问题。例如,季节变迁、生态破坏或恢复、物种进化或变异、群落演替等过程中,时而出现某时间点突变的生态过程。这种时间梯度上的突变过程可以是有规律的,如水稻不同生长阶段中,对水分的需求以及各种养分的汲取也大不相同,水稻田的土壤呼吸、物质循环、土壤或根系微生物群落组成或功能等在短期内可能呈现不同模式。也可以是偶然的突发事件,如在严重破坏性的森林大火前后,森林生态系统的物种多样性和功能显然是两种不同的状态。
更多场景就不举例了,以下简单列举几篇文献中的实际应用,来看分段线性回归如何应用在这些场景中寻找合适的断点位置,以及解释不同响应状态的生物学现象。
实例一
Hu等(2020)在青藏高原嘎隆拉山3000米的海拔范围内,研究了地质过程和环境因素对植物、细菌群落多样性和生态系统功能的影响。
文中部分结果中,作者阐述了群落组成和生态功能的海拔模式,分析发现生物群落多样性和生态系统功能的梯度变化在海拔2000–2800米处均存在明显的断点,并且在不同地质断层带之间呈现出一致性,凸显了地质过程与环境相互作用对生态系统的重要塑造作用。
部分分析通过分段线性回归实现,如下展示一些文中应用分段线性回归描述现象的图表。
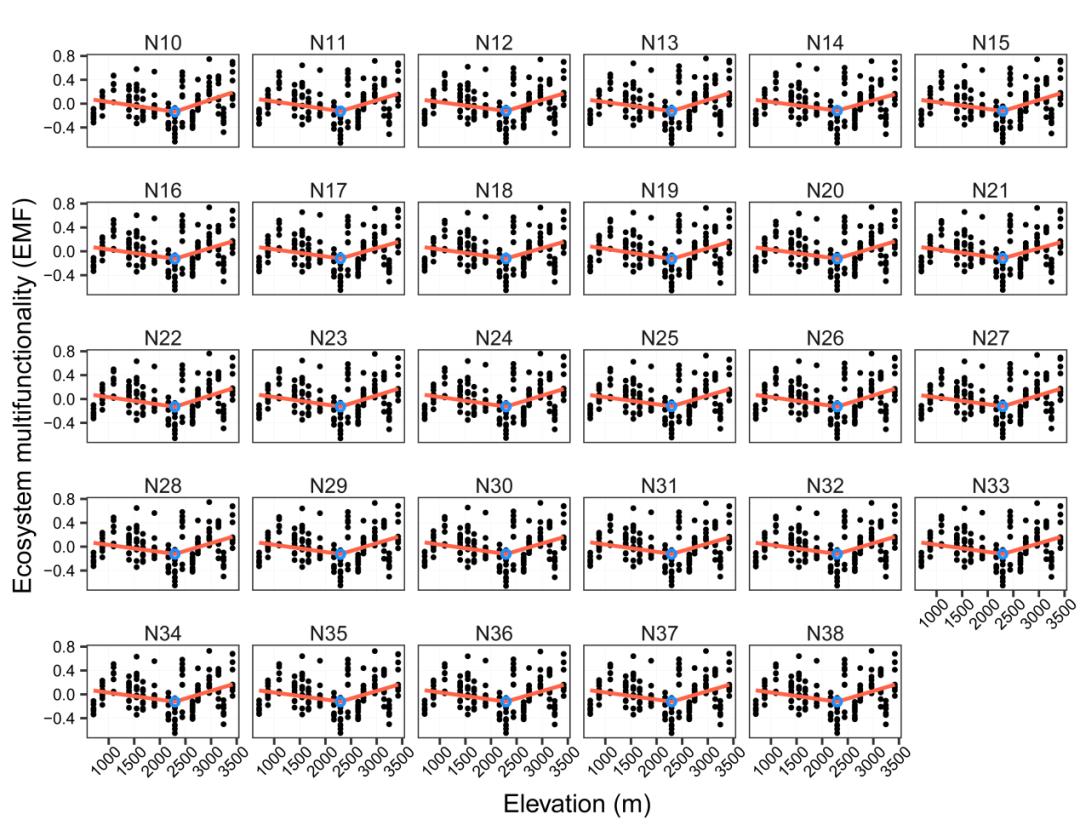
源自图S8,利用分段回归分析方法估算38个生态系统多功能(EMF)的海拔断点,均在2300米左右处,呈现出一致的模式。
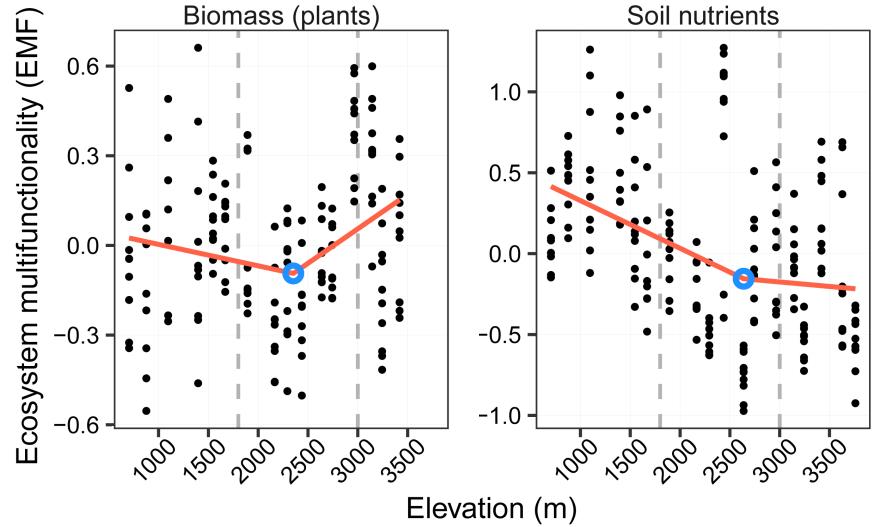
源自图S9,分段回归分析显示,植物生物量以及土壤养分等功能组的生态系统多功能(EMF)在2200-2400米处显示出明显的断点。
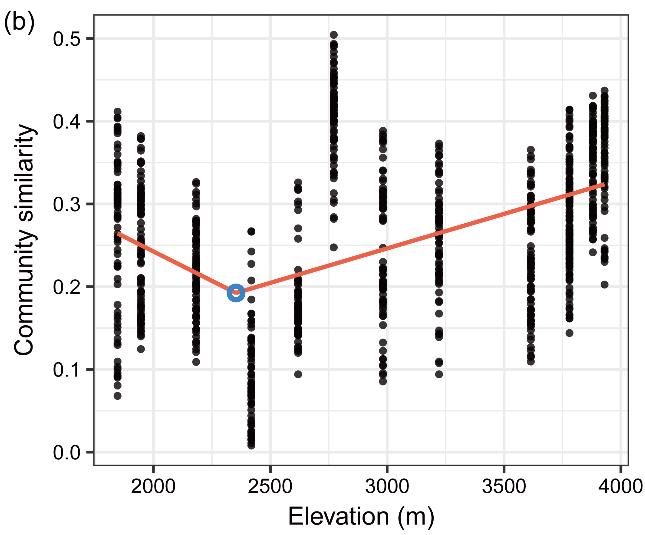
源自图S11 b,在嘎隆拉山与贡嘎山两个不同的地质带环境中,使用分段回归分析检查两山海拔相似的成对地点之间细菌群落相似性随海拔变化的海拔断点,发现呈现出一致的模式。
实例二
Li等(2013)通过调查中国新疆的维管植物、哺乳动物和鸟类的分布,评测了旱地物种丰富度模式的水能动力学假说。
文中部分分析中,作者通过分段线性回归评估物种丰富度模式的气候决定因素,检测到物种丰富度与潜在蒸散量之间关系的潜在断点。结果显示,三类物种丰富度都呈现出与能量可用性的单峰模式:物种丰富度首先随着潜在蒸散量的增加而增加,随后降低,表明在较低的能量可利用性时刺激物种丰富度,而在高时抑制物种丰富度。
如下展示了文中应用分段线性回归描述现象的图表。
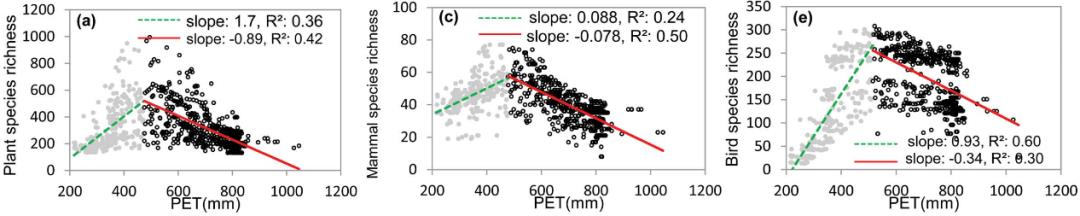
源自图2,维管植物(a)、哺乳动物(c)和鸟类(e)的物种丰富度随潜在蒸散量(potential evapotranspiration,PET)的改变。灰点和虚线表示低能量区域中的关系,黑点和实线表示高能量区域中的关系。
实例三
种-面积关系(species–area relationship,SAR)在保护生物地理学和生物多样性研究的理论框架中起着重要作用,Gao等(2019)探索了大量数据集中种-面积关系中面积阈值的发生率和数量,以评估目前广泛使用的检测小岛效应(small island effect,SIE)的方法是否稳健。
文中部分分析中,作者将15种回归模型(包括线性回归和具有两段和三段的分段线性回归)应用于源自文献的68个全局岛数据集,比较了不同模型的拟合优度以及对斜率和断点估计值的准确度。结果透露出传统单一的小岛效应检测标准似乎并不牢固,比较应使用尽可能多的模型综合衡量。
如下展示了文中应用分段线性回归描述现象的图表。
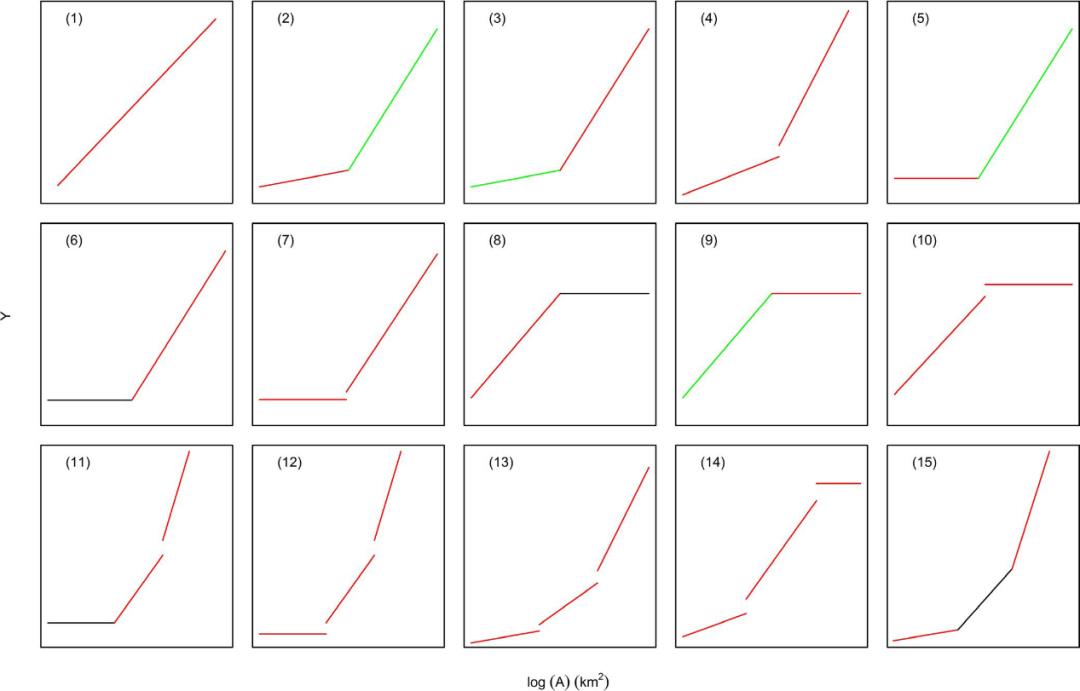
源自图1,15种回归模型拟合回归的示意图。对于图中分段的颜色,红线表示该段是通过回归获得的,绿线表示通过斜率迭代获得线段,黑线表示该段是通过直接继承获得的。
实例四
Mauro等(2018)调查了2002-2016年期间,纽约罗切斯特空气中11–500 nm颗粒物数量浓度特征及颗粒物浓度的时间趋势。
文中部分分析中,作者描述了不同粒径空气颗粒物浓度在2002-2016年期间的整体变化模式。考虑到多年度的时间序列上往往会伴随明显的季节效应,为了排除季节变迁的干扰,作者区分季节(夏季、冬季、春秋季)分别构建了不同粒径空气颗粒物浓度在连续15年尺度上的线性回归和分段线性回归。观察到2011-2013年之间存在的明显断点,特别对于小粒径空气颗粒物而言尤为显著,这可能与这些年及随后的时间中当地汽车数量增加有关。
如下展示了文中应用分段线性回归描述现象的图表。
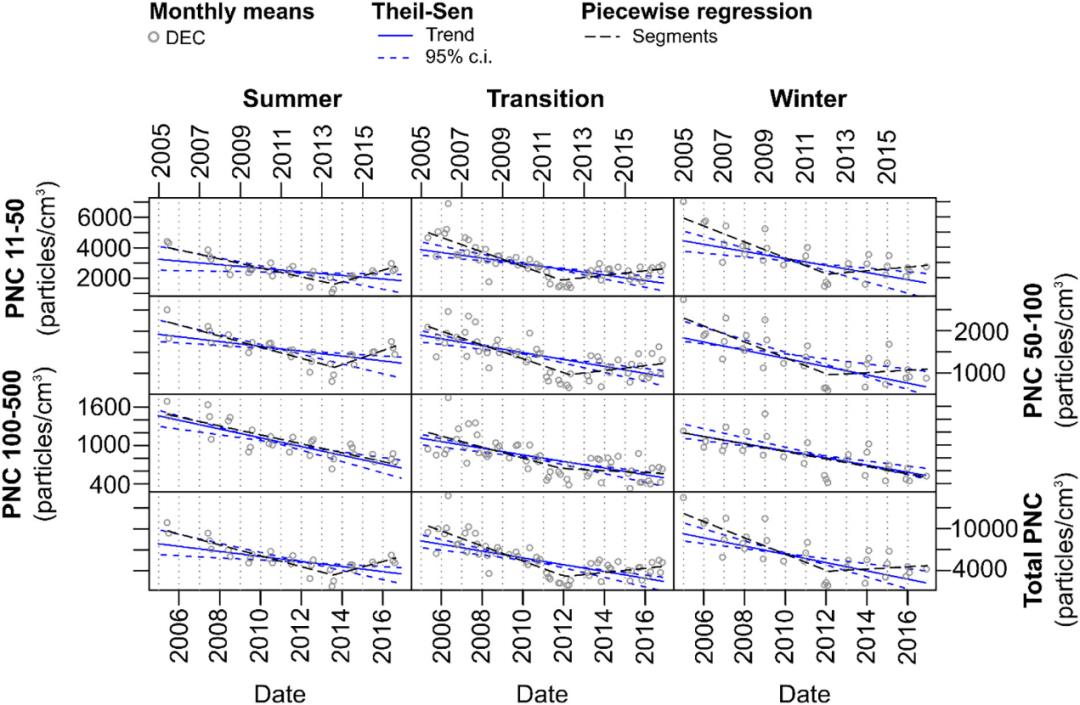
源自图8,2002-2016年期间,3个季节的空气颗粒物浓度的趋势分析结果。黑色虚线为具有断点估计的分段线性回归,蓝色实线为一般线性回归。
R语言执行分段线性回归的示例
R语言中执行分段回归的包很多,大都根据不同的复杂情况而设计。这里就暂且展示两个用于执行最简单分段线性回归的R包,也是很多文献中经常使用的。其它更多或更复杂的方法且不提,需要时根据实际文献中的方法描述学习对应的R包即可。
SiZer包的分段线性回归
SiZer包中函数piecewise.linear()提供了一个非常简洁的方法,用于执行包含单个断点的一元响应的分段线性回归。无需预先指定断点的位置,该函数可以自动评估确定断点。
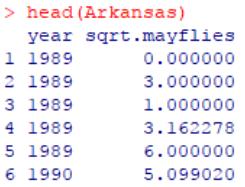
使用R包自带的示例数据Arkansas作演示。该数据集记录了美国科罗拉多州阿肯色河AR1监测站观测记录的蜉蝣丰度的16年时间序列(每年5次重复),包含2个变量的90个观察值,year是观测年限,sqrt.mayflies是浮游丰度的平方根。
现在期望对浮游丰度的时间序列建模。
library(SiZer)
#示例数据集,详情 ?Arkansas
data(Arkansas)
head(Arkansas)
#平滑拟合探索二者关系,发现似乎存在一个阈值时间
#该时间点之前,蜉蝣丰度呈上升趋势;时间点之后,蜉蝣丰度大致平缓
library(ggplot2)
ggplot(Arkansas, aes(year, sqrt.mayflies)) +
geom_point() +
geom_smooth()
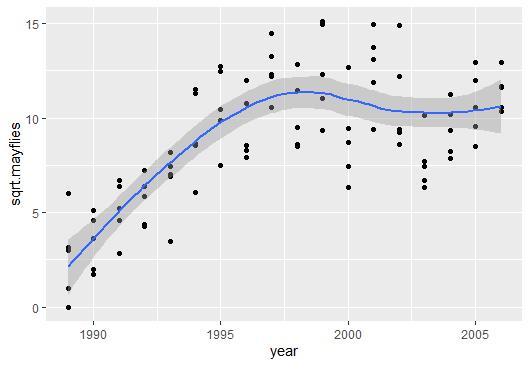
#提示似乎可以通过分段线性回归描述二者关系,该阈值时间就是断点
#执行分段线性回归,详情 ?piecewise.linear
#分段断点的位置自动确定,并使用 1000 次自举估计 95% 置信区间
model <- piecewise.linear(x = Arkansas$year, y = Arkansas$sqrt.mayflies,
CI = TRUE, bootstrap.samples = 1000, sig.level = 0.05)
model
#简单作图查看分段线性回归图
plot(model, xlab = 'year', ylab = 'sqrt.mayflies')
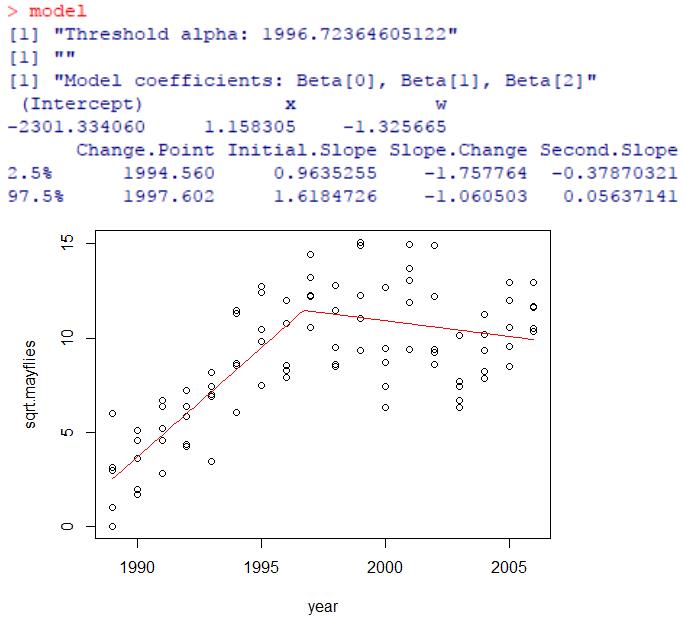
结果中给出了断点的位置,约x=1996.72处,以及两个局部线性回归的参数估计值和置信区间等。
对于全模型的R2这里没有提供,可以通过已知回归式,基于自变量值预测响应变量的期望值,再根据响应变量的原始观测值和预测值的差异,手动计算R2。结果显示回归的R2=0.626,是非常可观的,说明将分段线性回归应用到该数据中是比较合适的。
#SSre:the sum of the squares of the distances of the points from the fit
#SStot:the sum of the squares of the distances of the points from a horizontal line through the mean of all Y values
fit1 <- predict(model, Arkansas$year)
SSre <- sum((Arkansas$sqrt.mayflies-fit1)^2)
SStot <- sum((Arkansas$sqrt.mayflies-mean(Arkansas$sqrt.mayflies))^2)
R2 <- round(1 - SSre/SStot, 3)
R2

segmented包的分段线性回归
与上述方法相比,segmented包中函数segmented()更加灵活:
(1)它可以从一个给定的已知线性回归或广义线性回归模型出发,寻找可能存在的断点,不局限于简单的纯线性关系,适用情况更广泛;
(2)允许考虑多变量响应的情况,不局限于简单的一元响应关系;
(3)允许出现多个断点的情况,不局限于只能识别单个断点;
(4)关于断点位置的确定,即可以通过指定断点数量自动评估位置,但如果您大致确定了断点可能出现的数值坐标,也可以将其输入至函数中,此时函数将在指定位置两侧确定最佳的断点。
方便起见,暂且不关注多元情况,或者多断点的情况,仍以上述数据为例展示吧。
library(segmented)
#例如,先拟合一个简单的线性回归模型
fit_lm <- lm(sqrt.mayflies~year, data = Arkansas)
summary(fit_lm)
#在上述已知的线性回归模型中,通过函数 segmented() 寻找可能的断点
#详情 ?segmented,可选两种方法
#第一种,通过 npsi 指定断点数量
#例如 1 个断点,将自动在全范围内寻找可能的断点位置
lm_seg1 <- segmented(fit_lm, seg.Z = ~year, npsi = 1)
summary(lm_seg1)
plot(lm_seg1, xlab = 'year', ylab = 'sqrt.mayflies')
points(sqrt.mayflies~year, data = Arkansas)
#第二种,通过 psi 指定断点可能存在的大致初始位置
#例如 x=1997 是可能的断点位置,将它指定,将自动在 x=1997 附近寻找最佳的断点位置
lm_seg2 <- segmented(fit_lm, seg.Z = ~year, psi = 1997)
summary(lm_seg2)
plot(lm_seg2, xlab = 'year', ylab = 'sqrt.mayflies')
points(sqrt.mayflies~year, data = Arkansas)
#注:segmented() 的两种方法得到的断点位置或参数估计值等可能不同
#不同 R 包的方法之间,得到的断点位置或参数估计值等可能不同
结果中给出了断点的位置,约x=1996.72处,以及两个局部线性回归的参数估计值、显著性等。
此外还提供了回归的R2=0.626,校正后R2=0.613是非常可观的,说明将分段线性回归应用到该数据中是比较合适的。您还可以再对比一开始构建的简单线性回归的R2=0.376(上图未显示),会发现有非常明显的精度提升。
参考文献
以上是关于R语言 | 分段线性回归及对分割点的评估选择及R计算的主要内容,如果未能解决你的问题,请参考以下文章