R语言基本功:数据集取子集
Posted 刘老师医学统计
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言基本功:数据集取子集相关的知识,希望对你有一定的参考价值。
如果让我推荐一门统计软件,我就推荐你学R语言。R不仅具有非常强大的统计分析能力和绘图能力,更重要的是免费。在未来,越来越来的期刊会要求使用正版软件。
网上有不少针对R语言的教程,有一些确实不错,但使用起来,总有些实际很常用,却没有讲的内容,所以我想着从实战出发,自己争取出个系列教程,方便大家使用。
导入数据
#删除内存中变量rm(list = ls())
mydata <- read.delim("clipboard")str(mydata)head(mydata,9)
#取子集1
#年龄>50,BMI>27,男性
newdata1<-mydata[mydata$age>50 & mydata$sex==1 & mydata$bmi>27,]head(newdata1)

#取子集2
#年龄>50或年龄<30,男性,BMI<24
newdata2<-mydata[mydata$age>50 & mydata$sex==1 & mydata$bmi>27 | mydata$age<30 & mydata$sex==1 & mydata$bmi>27,]head(newdata2)

#取子集3、4
#提取sex, age, bmi, work, x, y, disease变量
newdata3<-mydata[,c("sex","age","bmi","work","x","y",'disease')]head(newdata3)
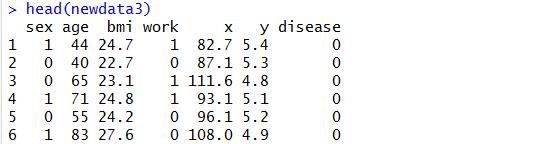
newdata4<-mydata[c("sex","age","bmi","work","x","y",'disease')]head(newdata4)
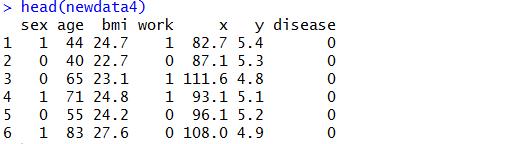
#取子集5
#取子集subset函数
#年龄大于75或年龄小于20,男性,病人
newdata5<-subset(mydata,age>75 & sex==1 & disease==1 | age<20 & sex==1 & disease==1)head(newdata5)

#取子集6
#不选择a、b、c三个变量
#年龄大于75或年龄小于20,男性,病人,保留变量sex age bmi work x y disease
newdata6<-subset(mydata,(age>75 | age<20) & sex==1 & disease==1,select = c(sex:work,x:disease))head(newdata6)
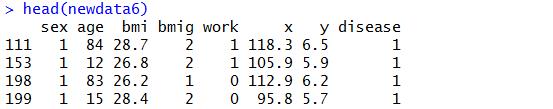
#取子集7
#年龄大于75或年龄小于20,男性,病人,去除变量a b c
newdata7<-subset(mydata,(age>75 | age<20) & sex==1 & disease==1,select = -c(a:c))head(newdata7)
以上是关于R语言基本功:数据集取子集的主要内容,如果未能解决你的问题,请参考以下文章