R语言离群值处理分析
Posted 拓端数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言离群值处理分析相关的知识,希望对你有一定的参考价值。
参考 :http://tecdat.cn/?p=3415
数据中的异常值可能会使预测失真并影响准确性,尤其是在回归模型中,如果您没有正确检测并处理它们,那么它们会影响精度
为什么异常值检测很重要?
在真实观察中处理或改变异常值/极端值不是标准操作程序。但是,了解它们对预测模型的影响至关重要。留待调查人员判断是否需要治疗异常值以及如何去做。
那么,为什么识别极端值很重要?因为,它可以大大偏倚/改变合适的估计和预测。让我使用cars数据集来说明这一点。
为了更好地理解异常值的含义,我将比较具有和不具有异常值的汽车数据集的简单线性回归模型的拟合。为了清楚地区分效果,我手动将极端值引入原始数据集。然后,我预测这两个数据集。
检测异常值
单变量方法
对于给定的连续变量,异常值是那些位于1.5 * I Q R之外的观测值,其中IQR,“四分位数间距”是第75和第25个四分位之间的差值。在盒子下面看看胡须外的点。
双变量方法
可视化X和Y的框图,用于分类X
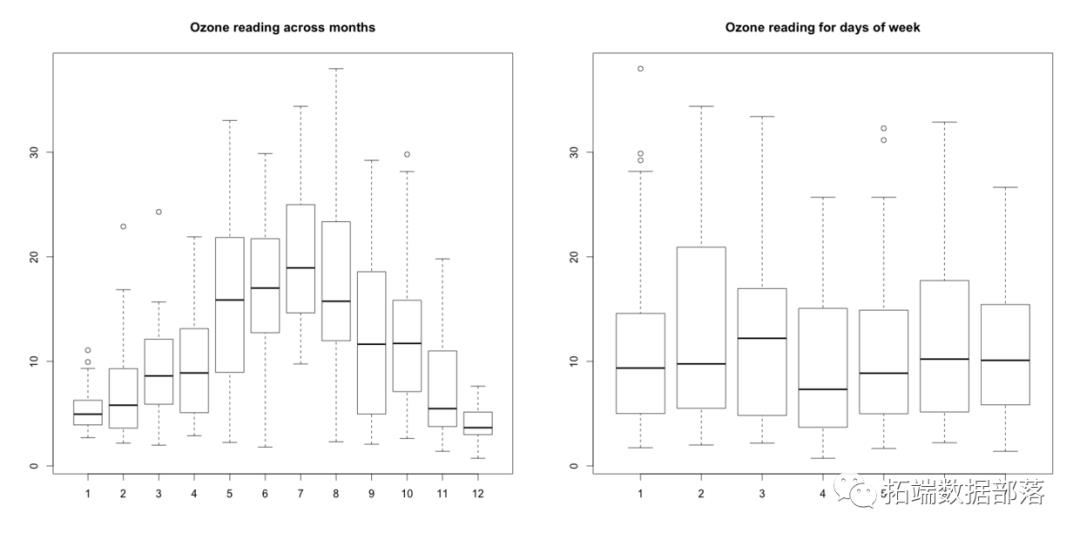
什么是推论?盒子水平的变化表明,Month似乎有影响,ozone_reading而Day_of_week没有。相应分类层级中的任何异常值都显示为盒外晶须外的点。
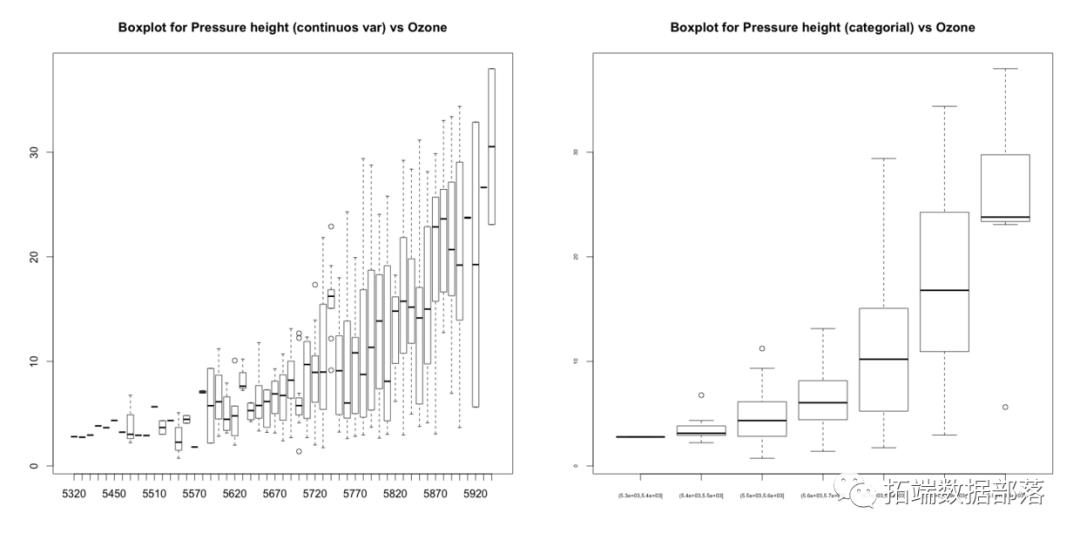
你可以在箱形图中看到几个异常值,以及这个值是如何ozone_reading增加的pressure_height。这很清楚。
多变量模型方法
基于仅仅一个(相当不重要)的特征声明观察结果为异常值可能会导致不切实际的推论。当你必须决定一个单独的实体(由行或观察值表示)是否是极值时,最好集体考虑重要的特征(X)。输入Cook的距离。
库克距离
库克距离是一个关于给定回归模型计算的度量,因此仅受模型中包含的X个变量的影响。但是,厨师的距离是什么意思?它计算每个数据点(行)对预测结果的影响。
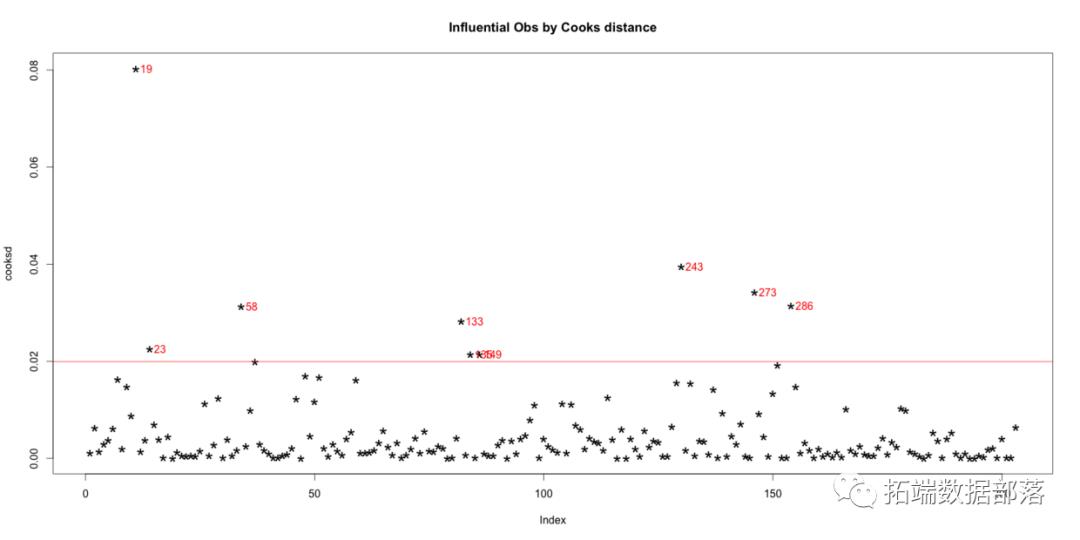
现在让我们从原始数据中找出有影响的行。如果你提取并检查每一个有影响的行(从下面的输出),你将能够推断出为什么该行变得有影响力。模型中包含的X个变量之一可能具有极端值。
异常值测试
该功能outlierTest从car包中给出了基于给定的模型最极端的观察。以下是基于mod我们刚创建的线性模型对象的示例。
点击标题查阅往期内容
更多内容,请点击左下角“阅读原文”查看


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看
以上是关于R语言离群值处理分析的主要内容,如果未能解决你的问题,请参考以下文章