R语言实现文献的批处理
Posted R语言交流中心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言实现文献的批处理相关的知识,希望对你有一定的参考价值。
科研过程中难免会涉及大量文献的检索下载,还有信息的整合。我们今天给大家介绍一个可以获取文献相关信息甚至全文的R包。Rcrossref可以通过文献doi获得文献的相关信息,crminer可以基于链接直接下载原文,当然这个要看你所在网络的权限了。首先我们看下报道额安装:
install.packages("rcrossref")install.packages("crminer")
接下来我们看下包中各函数的功能:
1. cr_cn获取各种参考文献形式
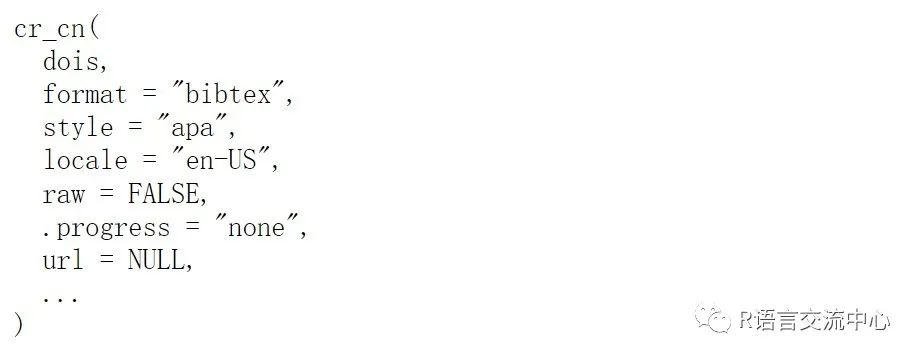
其中主要参数:
Format 指的输出的形式,包括:"rdf-xml","turtle", "citeproc-json", "citeproc-json-ish","text", "ris", "bibtex" (default),"crossref-xml", "datacite-xml","bibentry", or"crossref-tdm"。
Style 指的引文样式风格库,只要包含的都可以输出。
我们看下实例:
cat(cr_cn(dois ="10.1126/science.169.3946.635", format = "bibtex"))

2. cr_citation_count 获取文献的引用次数。我们直接看下实例:
cr_citation_count(doi="10.1371/journal.pone.0042793")

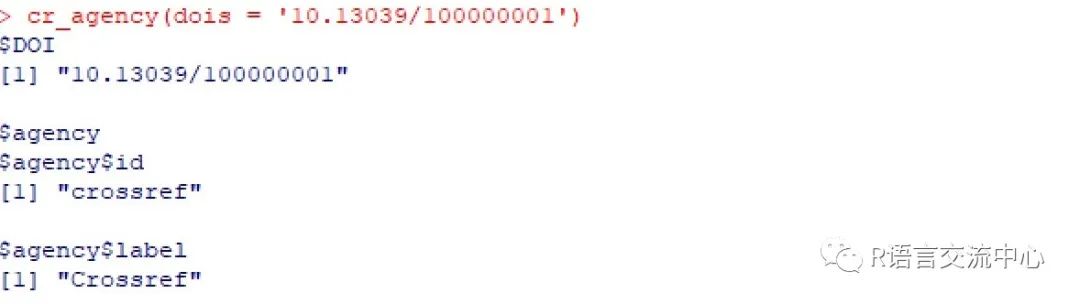
3. cr_agency获取doi 的生成机构。
cr_agency(dois = '10.13039/100000001')
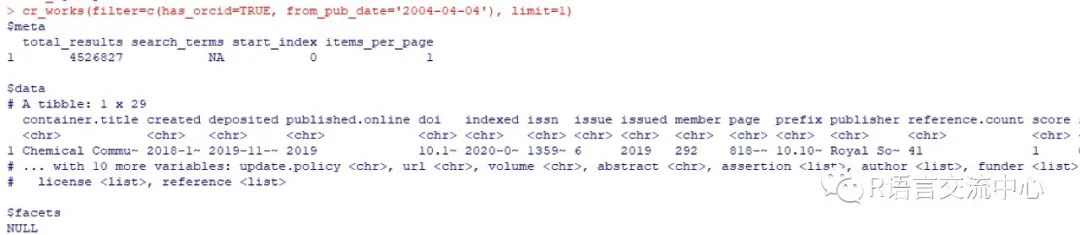
4. cr_works 查看交叉引用的情况。实例:
cr_works(filter=c(has_orcid=TRUE,from_pub_date='2004-04-04'), limit=1)
5. cr_prefixes基于doi前缀搜索相应doi来源
cr_prefixes(prefixes=c('10.1016','10.1371','10.1023','10.4176','10.1093'))
以上是rcrossref中的主要功能,接下来我们看下在crminer中获取文献全文的功能:
1. crm_links 通过doi获取文章全文的链接,全文格式包括'xml', 'html', 'plain', 'pdf', 'unspecified', or 'all' (default)。实例:
crm_links(doi="10.1245/s10434-016-5211-6", "pdf")

2. as_tdmurl 创建一个crm_links项目。实例:
as_tdmurl("http://downloads.hindawi.com/journals/bmri/2014/201717.xml", "xml")

3. crm_text 获取全文的文本数据。实例:
links=crm_links(doi="10.1245/s10434-016-5211-6", "pdf")crm_text(url=links, type='pdf')

4. crm_pdf获取pdf文件。实例:
links <- crm_links(dois_pensoft[10],"all")crm_pdf(links)

5. crm_xml 获取xml格式的文献。实例:
crm_xml(links)

6. crm_extract从pdf中抽取文本信息。实例:
path <-system.file("examples", "MairChamberlain2014RJournal.pdf",package = "crminer")res <- crm_extract(path)

至此,我们只需要知道doi就可以获取文献的相关信息。当然此包存在一定的局限性,那就是预印版杂志的doi是无法获取相关信息的。
以上是关于R语言实现文献的批处理的主要内容,如果未能解决你的问题,请参考以下文章