R语言数组数据框因子
Posted 大学生资料阁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言数组数据框因子相关的知识,希望对你有一定的参考价值。
可以在两个以上的维度存储数据的R数据对象
存储相同类型的元素
维度向量:表示数组中各维的长度的向量
多维数组array可以描述多维数据
array有一个特征属性叫维度向量(dimension vector),即dim属性,此向量是一个正整数所构成的向量,如果它的长度为k,那么该数组就是k维数组
矩阵是数组的特殊情况,它具有两个维度
创建数组
可以通过array函数方便地创建数组
array(data = NA,dim = length(data),dimnames = NULL)
数组索引
数组是矩阵的一个自然推广。与矩阵一样,数组中的数据也只能拥有一种模式
从数组中选取元素的方式与矩阵相同。不同的是数组的维度更高,下标也更为复杂
程序示例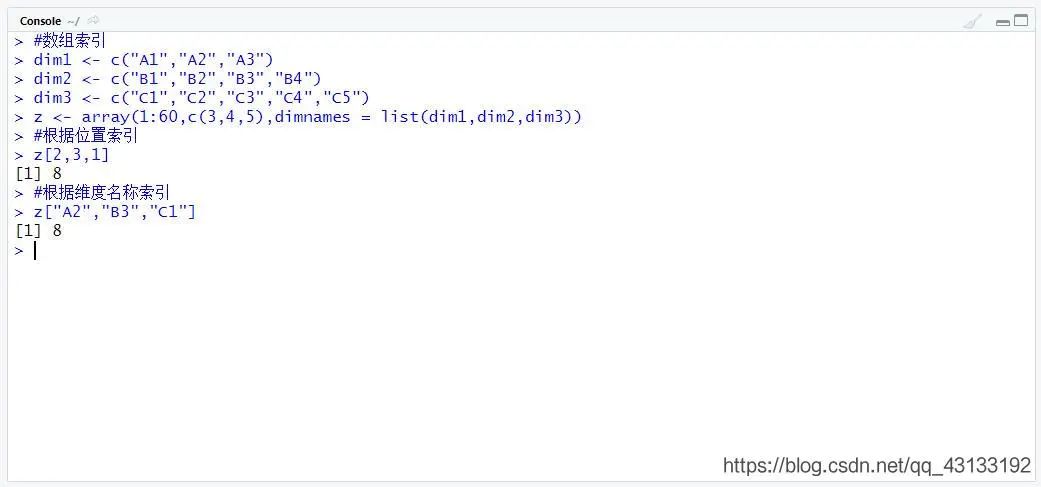
数据框是仅次于向量的最重要的数据对象类型,是R语言中最常处理的数据结构。由于数据有多种数据类型,所以无法将此数据集放入一个矩阵。在这种情况下,数据框是最佳选择
可以将不同的数据类型组合在一起的数据结构
每一列存储数据的类型必须相同
每列的行数(长度)必须相同
创建数据框
数据框是仅次于向量的最重要的数据对象类型
在实际操作中,通常会用数据框的一列代表某一变量属性的所有取值,用一行代表某一样本数据
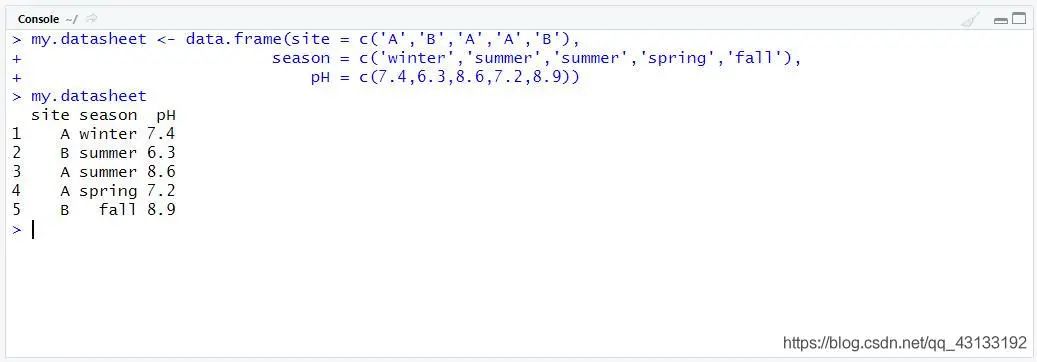
data.frame函数可以直接把多个向量建立为一个数据框,并为列设置名称

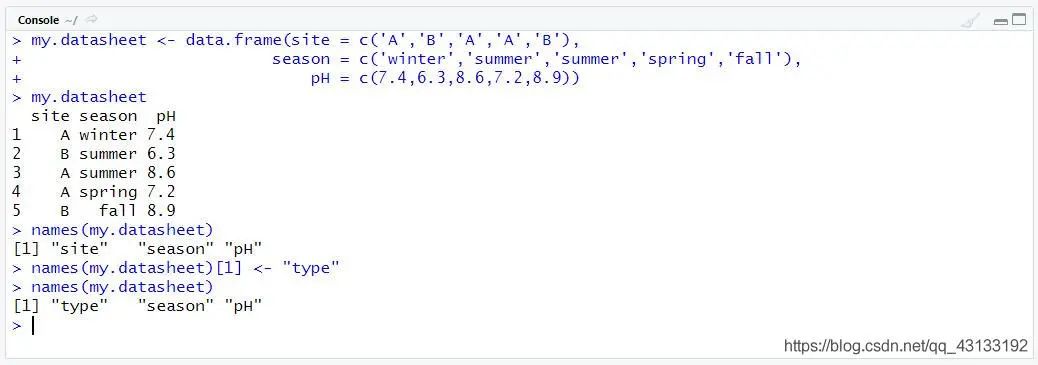
也可以通过names(<数据框>)来读取并编辑列名称

数据框索引
数据框索引和矩阵类似,主要有:
下标索引
行或列的索引
元素索引
使用$符号按名称索引列数据(某个特定变量)
subset函数按条件索引
sqldf包中的sqldf函数使用sql语句索引

数据框编辑
数据框可以通过edit函数和fix函数手动修改
rbind函数和cbind函数分别增加新的样本数据和新属性变量
(需要注意的是,rbind函数的自变量的宽度(列数)应该与原数据框的宽度相等,而cbind函数的自变量的高度(行数)应该与原数据框的高度相等,否则程序将会报错)
names函数可以读取数据框的列名以进行修改操作


因子,也称为因子型变量
是R中用于对数据进行分类
并将其存储为级别的数据对象
它可以是一个类别的集合
也可以是一个有序项目的集合
因子型变量可以取得的所有值,被称为因子水平(levels)
因子创建
在R中,使用因子来表示名义变量或有序变量,其中factor()函数是一种定义因子的方法。它是将一个向量转换成因子,其使用格式为
factor(x = character(),levels,labels = levels,exclude = NA,ordered = is.ordered(x))
| 名称 | 取值及意义 |
|---|---|
| x | 数据向量,也就是被转换成因子的向量 |
| levels | 可选向量,表示因子水平,当此参数缺省时,由x元素中的不同值来确定 |
| labels | 可选向量,用来指定各水平的名称,缺省时,取levels的值 |
| exclude | 从x中剔除的水平值,默认值为NA |
| ordered | 逻辑变量,取值为TRUE时,表示因子水平是有次序的(按编码次序);否则(FALSE)是无次序的 |
使用函数factor()将原始表示类别的字符串映射到整数上
diabetes <- factor(diabetes)
创建有序的因子型向量
status <- factor(status,ordered=TRUE)
展示一个因子的所有水平
levels(status)
factor()以一个整数向量的形式存储类别值
整数的范围是[1.k]
同时一个由字符串组成的
内部变量将映射到这些整数上
以上是关于R语言数组数据框因子的主要内容,如果未能解决你的问题,请参考以下文章