R语言随机森林模型中具有相关特征的变量重要性
Posted 拓端数据部落
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言随机森林模型中具有相关特征的变量重要性相关的知识,希望对你有一定的参考价值。
原文链接:http://tecdat.cn/?p=13546
变量重要性图是查看模型中哪些变量有趣的好工具。由于我们通常在随机森林中使用它,因此它看起来非常适合非常大的数据集。大型数据集的问题在于许多特征是“相关的”,在这种情况下,很难比较可变重要性图的值的解释。
为了获得更可靠的结果,我生成了100个大小为1,000的数据集。
library(mnormt)RF=randomForest(Y~.,data=db)plot(C,VI[1,],type="l",col="red")lines(C,VI[2,],col="blue")lines(C,VI[3,],col="purple")
顶部的紫色线是的可变重要性值 ,该值相当稳定(作为一阶近似值,几乎恒定)。红线是的变量重要性函数, 蓝线是的变量重要性函数 。例如,具有两个高度相关变量的重要性函数为
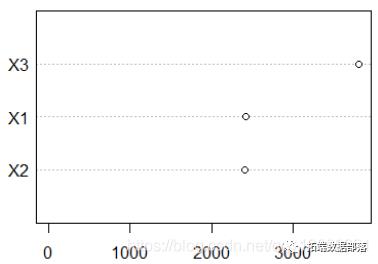
实际上,我想到的是当我们考虑逐步过程时以及从集合中删除每个变量时得到的结果,
apply(IMP,1,mean)}在这里,如果我们使用与以前相同的代码,
我们得到以下图
plot(C,VI[2,],type="l",col="red")lines(C,VI2[3,],col="blue")lines(C,VI2[4,],col="purple")
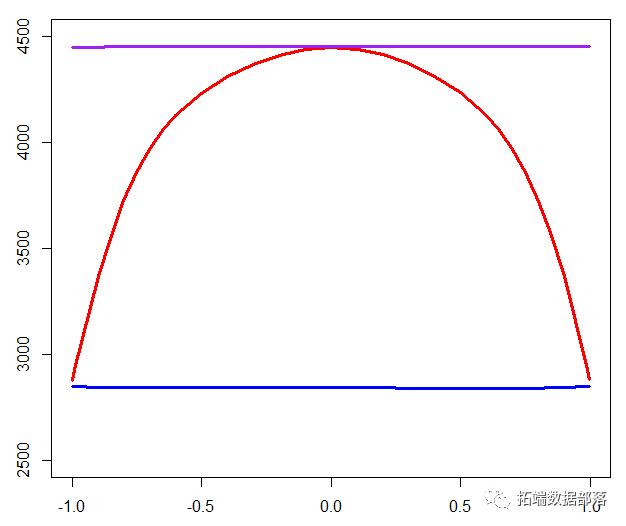
然而,当我们拥有很多相关特征时,讨论特征的重要性并不是那么直观。
点击标题查阅往期内容
更多内容,请点击左下角“阅读原文”查看报告全文


![]()
案例精选、技术干货 第一时间与您分享
长按二维码加关注
更多内容,请点击左下角“阅读原文”查看报告全文
以上是关于R语言随机森林模型中具有相关特征的变量重要性的主要内容,如果未能解决你的问题,请参考以下文章