R语言_001向量
Posted Lin王发林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言_001向量相关的知识,希望对你有一定的参考价值。
R语言,很多人都没有听过吧,听过也没有见过吧。本来想介绍一下,百度了一下介绍,想复制粘贴过来。一看,及其失望,如果是第一次看到这种介绍,估计已经和R没有缘分了,在这个大部分人接触的都是没有营养的信息的时代,还有比这些更没有营养的介绍。
Python都知道,因为你能接触到信息的地方,充斥着各种诱人的Python小广告(小广告是贬义词)。它是很强大,但也因此变得很庸俗,不过有用,也还是有价值。但R语言才是最纯净、最优雅的存在,就像县界长长隧道后面的雪国一样纯净,就为数据而存在。除此之外,R语言里面画出来的图也是最美的,可视化也是R的一大特长。数据结果也更细腻,Python得到的结果太僵硬,虽然没什么问题,但就是不美,有点难受。但遗憾的是,实际情况下使用Python会更多,以后应该也是,但这又何妨,完全不影响对R的热爱,发自内心的那种,就像盖茨比门前码头对面的那一团绿光,是内心深处的一种希望,这里是对数据的美好希望。
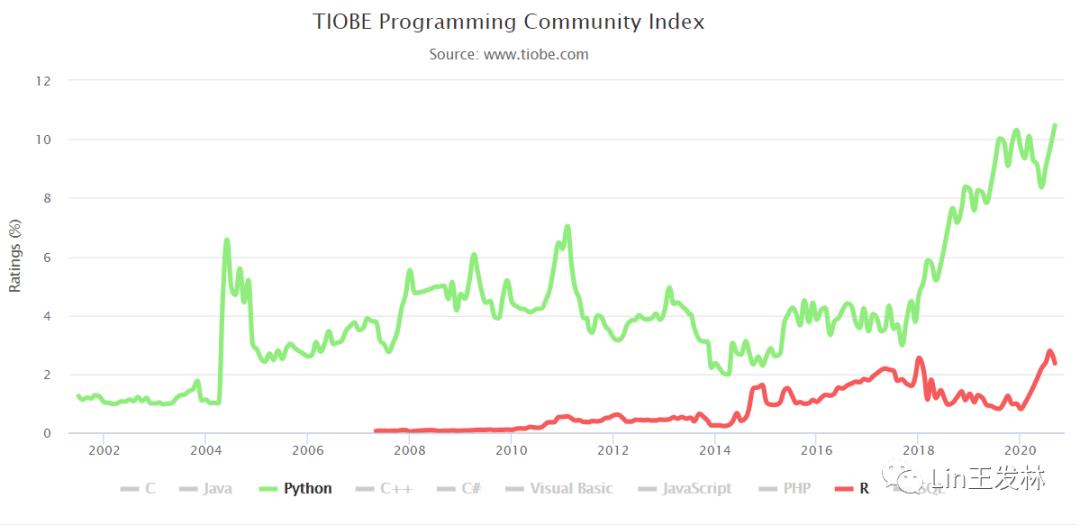
去找了点数据,可以看一下。下面这一张图就是这个月最新鲜的数据,R语言排名第九。看看前面那些响当当的名字,除了Python,哪个跟数据沾点关系,Python也只有大概1/5的用来研究数据的吧,它太泛了。所以这么算来,R和Python在数据领域,应该是没有表面上这么大的差异的。
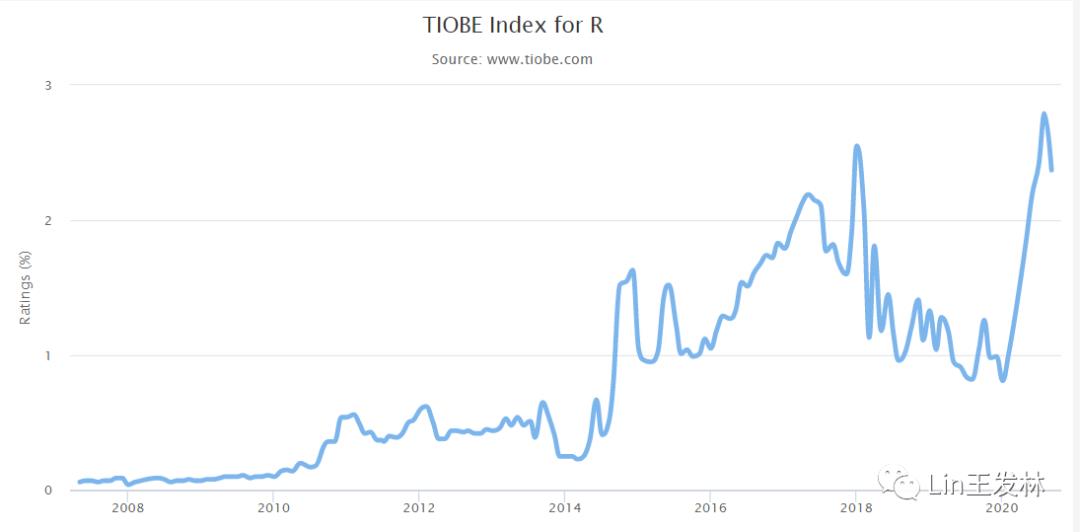
再看第二张和第三张图,都是新鲜出炉的数据啊。看看2018年到今年年初,多少无知的群众受Python小广告的欺骗,使得Python占比迅速增长,当然这其中所谓的大数据也是一个助推器,有几个公司真的用得上?有几个人会用嘛?都是搞几个技术人员,搞一个数据仓库,随便把数据拆分整合一下,给出一些毫无价值的报表,就号称我们有大数据支撑,是数据驱动的高科技企业。而实际业务呢?还是自己求着开发导点靠谱的明细数据,自己在Excel表格慢慢的操作,结果还是有点价值的。所以大数据是个好东西,就停留在最底层的技术端,毫无意义,应该让业务来主导啊,技术打好工就行了,但他们却自以为是的高高在上,产出一些毫无价值的垃圾,还洋洋得意。
扯远了,回来。今年的疫情让人还是理智了起来,R语言还是回到了正道上,这个2-3个点的占比就够了,足以让这门语言充满生机。
毕竟是开场,多打了点字。下面回到正题上,接下来会尽量系统的把R过一遍,参考了3本书,发现他们的布局都差不多,但是缺点是每个点介绍的都不是很全面深入。好在万能的互联网,后面整个结构和书上差不多,毕竟经过了这么多年的,基本上也成型了,然后会在这个结构的基础上,把每个点更丰满起来,毕竟这个不像书本那么有限,在这里多打点字、多放点图片完全不影响。
基础内容应该不多,就和大多数编程语言一样,基本数据类型、结构,基本语法。大概就这些基础,然后就是在此基础上的应用了。应用后面主要三个大的方面,传统统计、机器学习和可视化。基础不多,但要灵活使用需要不断实践。
好了,第一个基础内容:【向量】
【向量的创建】
1.直接创建
x1<- 1:10 #输出:[1] 1 2 3 4 5 6 7 8 9 10x2<- 666 #只包含一个值的向量x3<- TRUE #逻辑型向量x4 <- "WangFalin" #字符串
2.使用c()函数创建
c1 <- c(101,123,987,999)> [1] 101 123 987 999
c2 <- c(5:8)> [1] 5 6 7 8
#字符串型向量c3 <- c("叶子","驹子","直子","绿子","万里子")> [1] "叶子" "驹子" "直子" "绿子" "万里子"
#逻辑型向量c4 <- c(TRUE,FALSE,T,T,F)>[1] TRUE FALSE TRUE TRUE FALSE
说明一下,R语言里面TRUE、FALSE都是大写,可以简写成T和F
#一个不包含任何值的向量输出NULLc5 <-c()> NULL
3.使用rep函数创建重复序列的向量
rep(x, #要重复的序列对象times=1, #重复的次数,默认为1length.out=NA, #产生的向量长度,默认为 NAeach=1) #每个元素重复的次数,默认为1
rep(2:3,times=3)>[1] 2 3 2 3 2 3rep(2:3,each=3)>[1] 2 2 2 3 3 3rep(2:3,times=c(2,4))>[1] 2 2 3 3 3 3rep(1:10,length.out=3)>[1] 1 2 3
4.使用seq函数生成等差序列的向量
seq(from=1, #from是首项,默认为1;to=1, #to是末项,默认为1;by=((to - from)/(length.out - 1)), #by是步长或等差增量,可以为负数;length.out = NULL, #length.out是向量的长度;along.with = NULL, #along.with:用于指明该向量与另外一个向量的长度相同...)
seq(from=5,to=10)>[1] 5 6 7 8 9 10seq(from=2,to=15,by=3)>[1] 2 5 8 11 14seq(from=2,to=30,length.out=6)>[1] 2.0 7.6 13.2 18.8 24.4 30.0seq(from=2,by=4,length.out=5)>[1] 2 6 10 14 18seq(from=100,by=-10,length.out=6)>[1] 100 90 80 70 60 50c1 <- 1:5seq(from=2,by=5,along.with=c1)>[1] 2 7 12 17 22
【元素命名】
subject <- c('经济学','管理学','R语言','Excel','财务管理')score <- c(66,77,88,99,85)names(score) <- subjectscore

【向量元素访问】
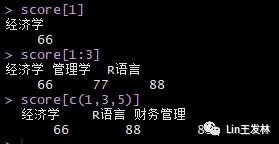
1.使用元素的位置引用
score[1]score[1:3]score[c(1,3,5)]
2.使用逻辑向量
score[c(T,F,F,T,T)]score[c(T,F)]
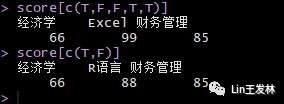
score[c(T,F)],这个会自动循环补齐
3.使用元素名字
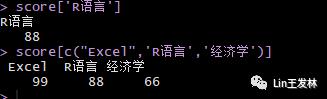
score['R语言']score[c("Excel",'R语言','经济学')]
4.使用which函数进行筛选
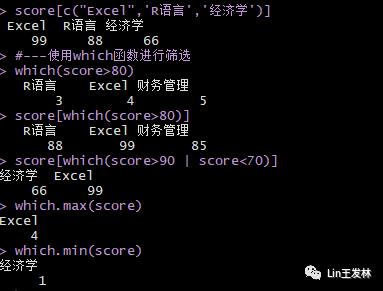
which(score>80)score[which(score>80)]score[which(score>90 | score<70)]which.max(score)which.min(score)
5.使用subset函数索引
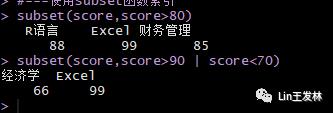
subset(score,score>80)subset(score,score>90 | score<70)
【向量编辑】
1.扩展向量
a <- c(1,2,3)c(a,c(100,200))>[1] 1 2 3 100 200append(a,c(10,22))>[1] 1 2 3 10 22
2.改变元素的值
a[1] <- 999>[1] 999 2 3a[1:2] <- 222>[1] 222 222 3
3.删除元素的值
score1 <- score[-1]
score2 <- score[c(1,3,5)]
【向量排序】
sort(x, #要排序的对象decreasing=FALSE, #排序顺序,是否为降序,默认为FALSE,即升序na.last=NA, #对NA值的处理,若为TRUE,则NA值将放在最后;若为FALSE,NA值将放在最前面;若为NA,则排序时剔除掉NA值index.return=FALSE #逻辑值,设置是否显示排序序列对应的元素值在未排序前序列中的对应位置索引,默认为FALSE)
sort(score)
sort(score,decreasing=T)
score1 <- append(score,NA)score1sort(score1,na.last = F)

end <- sort(score,index.return=T)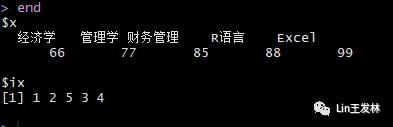
order.按照升序排序,当前位置的值来源于原始向量中哪个位置上的元素
order(score)>[1] 1 2 5 3 4order(score,decreasing = T)[1] 4 3 5 2 1
score[order(score,decreasing=T)]
rank.返回的是向量中每个数值对应的秩
rank(score)
rev.将向量倒序,即将原向量的元素按位置翻转
rev(score)
End
以上是关于R语言_001向量的主要内容,如果未能解决你的问题,请参考以下文章