R语言实战.2
Posted 云深之无迹
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言实战.2相关的知识,希望对你有一定的参考价值。
q
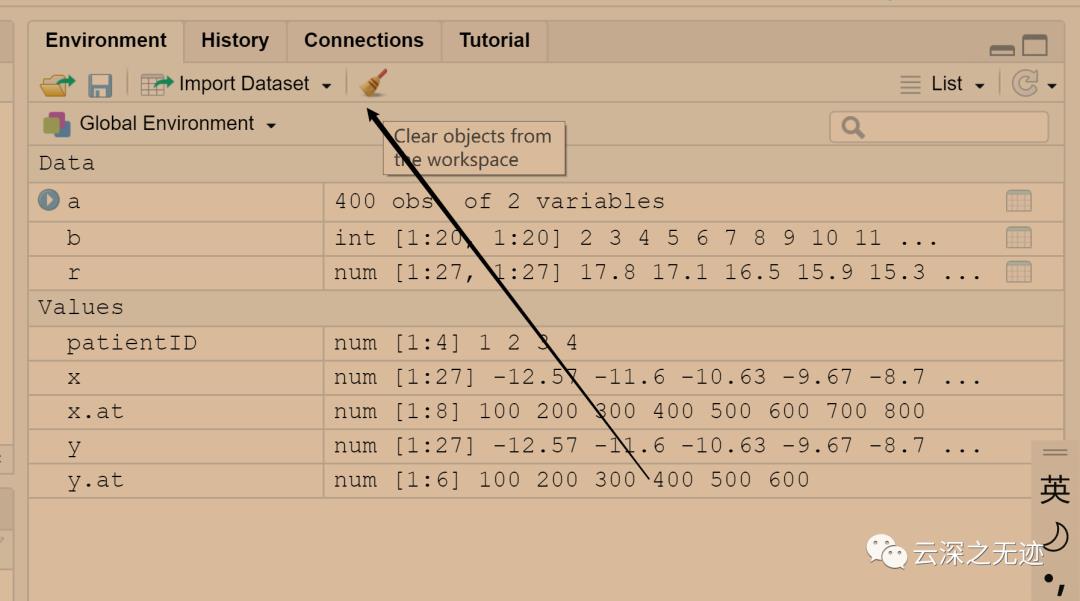
点这里是清除变量
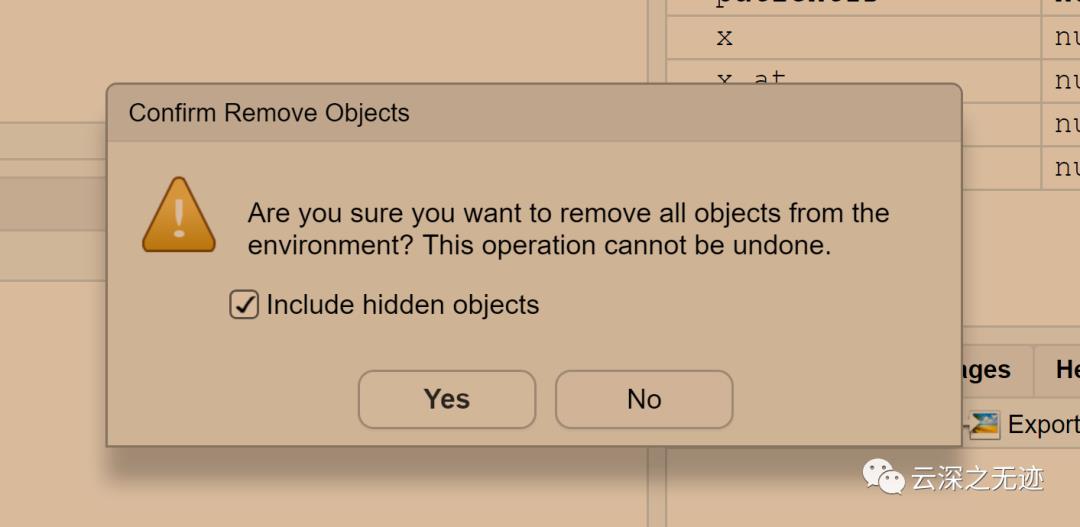
让确认
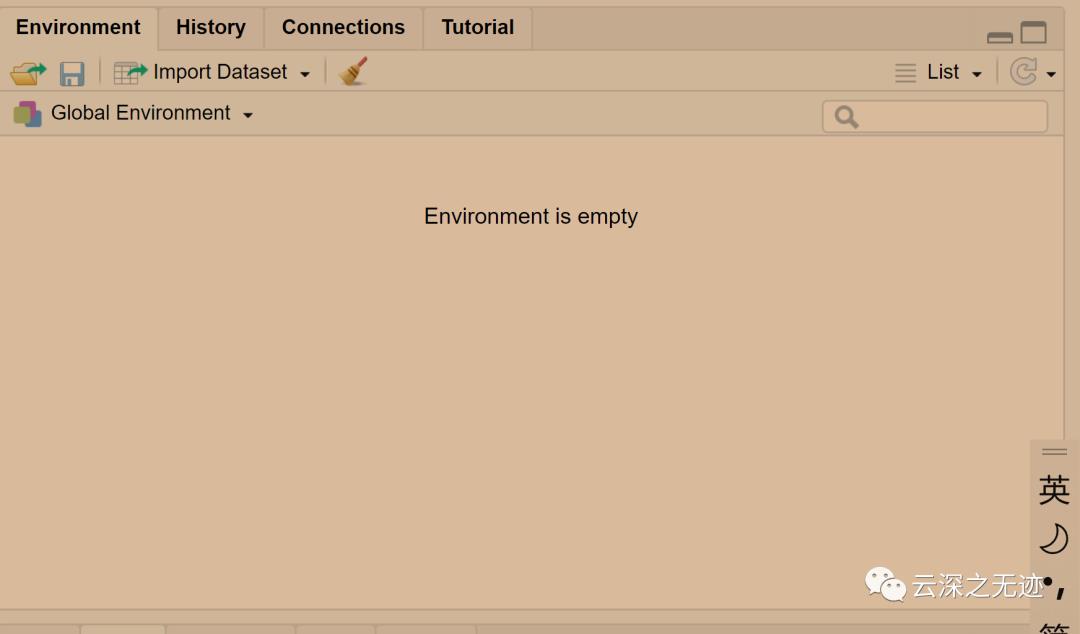


Ctrl+L是清屏
这个是对当前软件窗口的一些排列,看自己的需求去设置
我就先按照默认使用

可以看到每一步进行的中间结果都可以被导出
这个功能可能在多机工作时比较有用
可以看到支持的文件格式也很ok
文本
增强文本
excel
spss
sas
...........听说你还不够用?和Python集成,你懂得吧
这个地方是一个过滤器
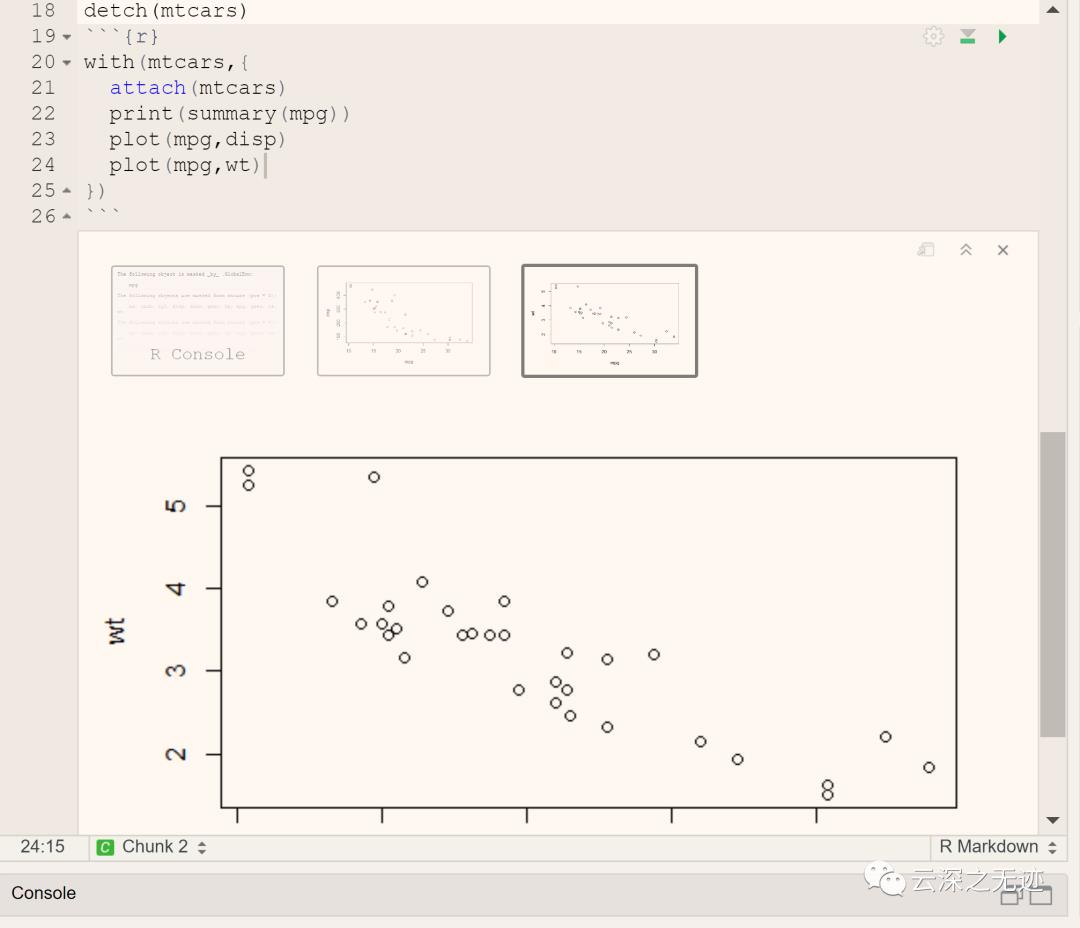
事实上输出的东西是很多的,你需要在纷杂里面找到自己的❤
bibi 这么多木九十想让你用个过滤器
这是对缓存文件的展现方式
说一下我对其的理解,文件就是在这个狭小的空间就是两种理念
List是显示的比较少,但是对数据的描述很齐全.
Grid是是用类似于二维矩阵的方式去描述.
要是我去写这个东西,我会尽力展现数据之间的相关关系
牺牲性能也在所不辞

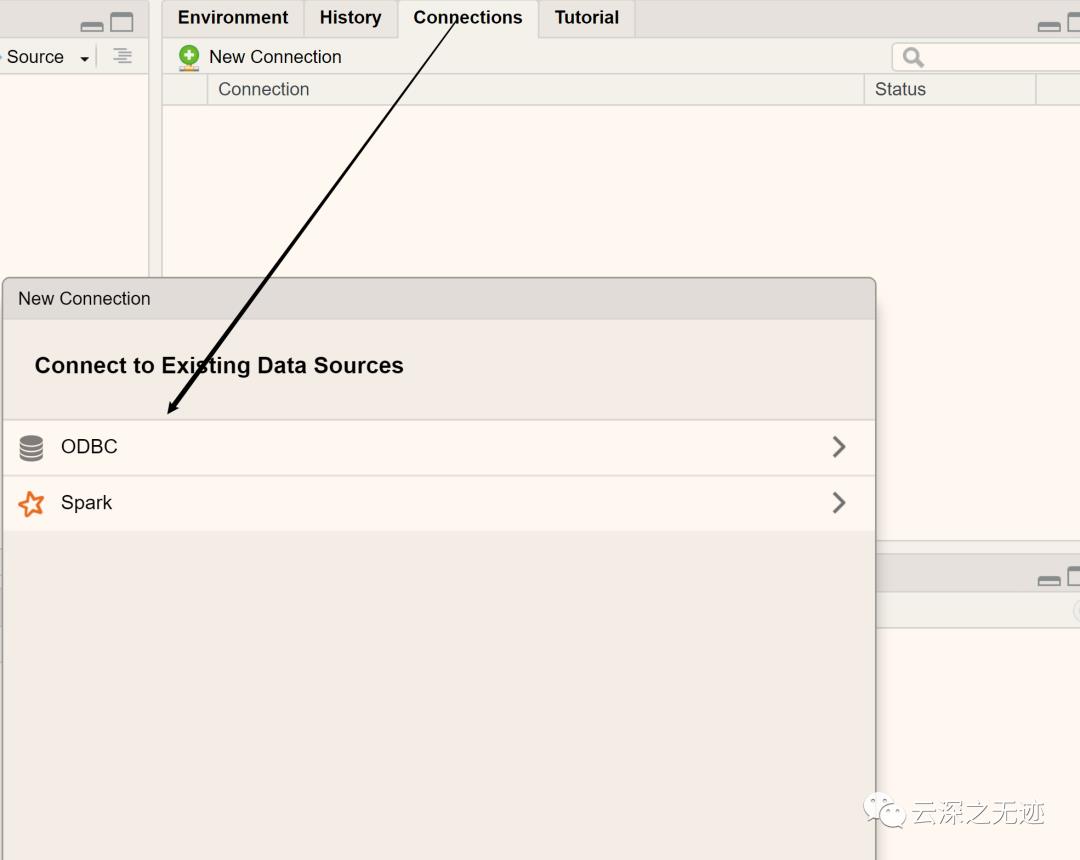
ODBC
开放数据库连接(Open Database Connectivity,ODBC)是为解决异构数据库间的数据共享而产生的,现已成为WOSA(The Windows Open System Architecture(Windows开放系统体系结构))的主要部分和基于Windows环境的一种数据库访问接口标准ODBC 为异构数据库访问提供统一接口,允许应用程序以SQL 为数据存取标准,存取不同DBMS管理的数据;使应用程序直接操纵DB中的数据,免除随DB的改变而改变。用ODBC 可以访问各类计算机上的DB文件,甚至访问如Excel 表和ASCI I数据文件这类非数据库对象。
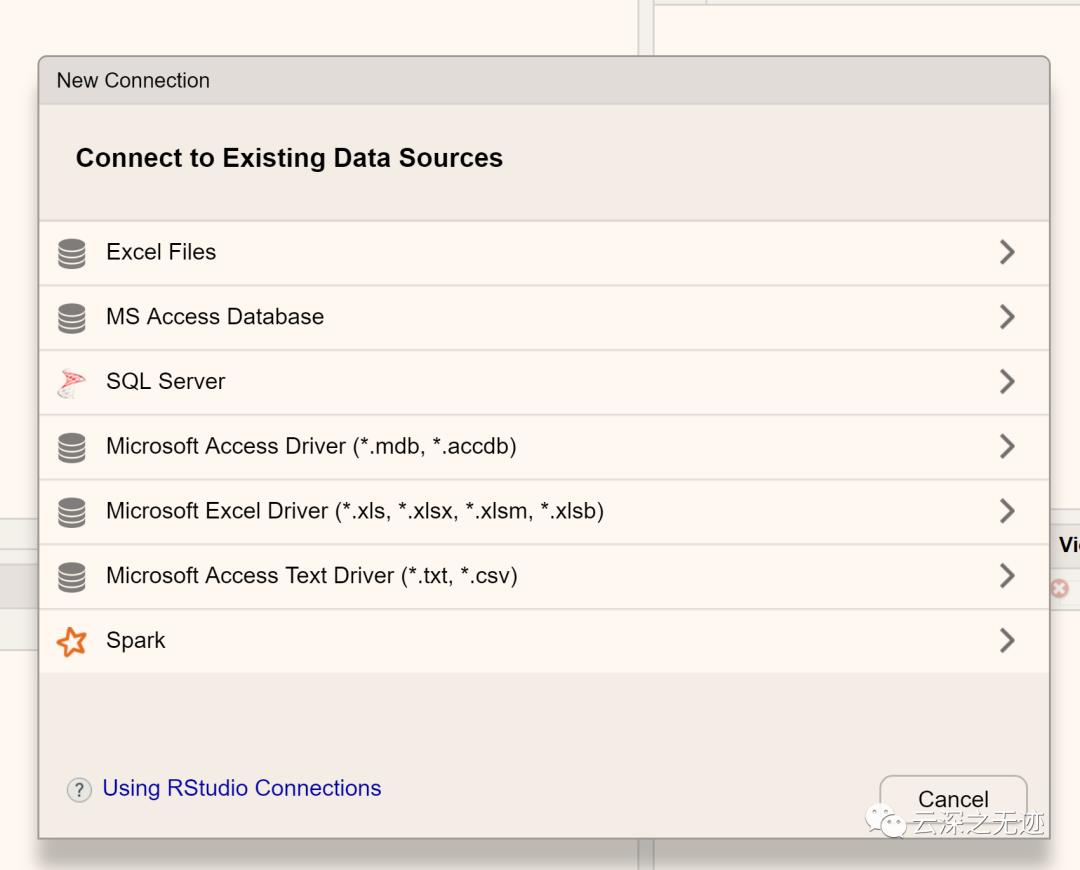
可以看到是一些常用的小型数据库,很齐全了
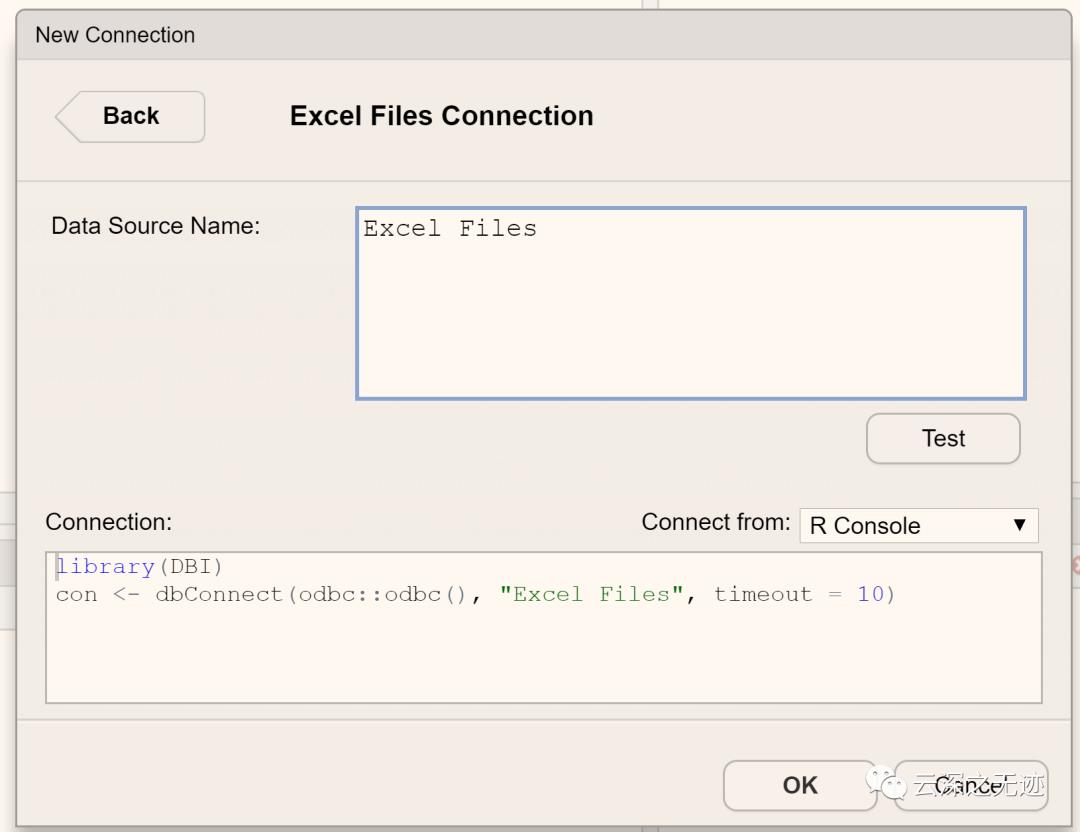
我们先看Excel,比较常见的文件类型
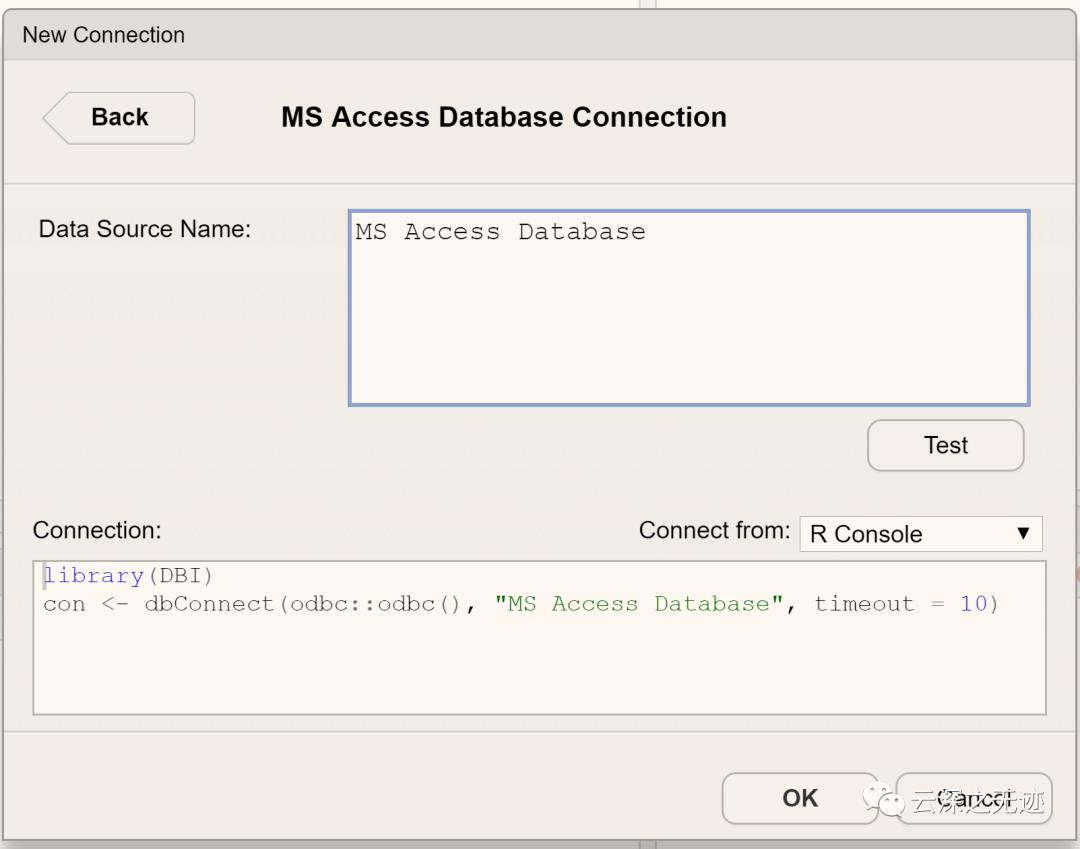
一个数据库
下面就是实际调用的时的命令
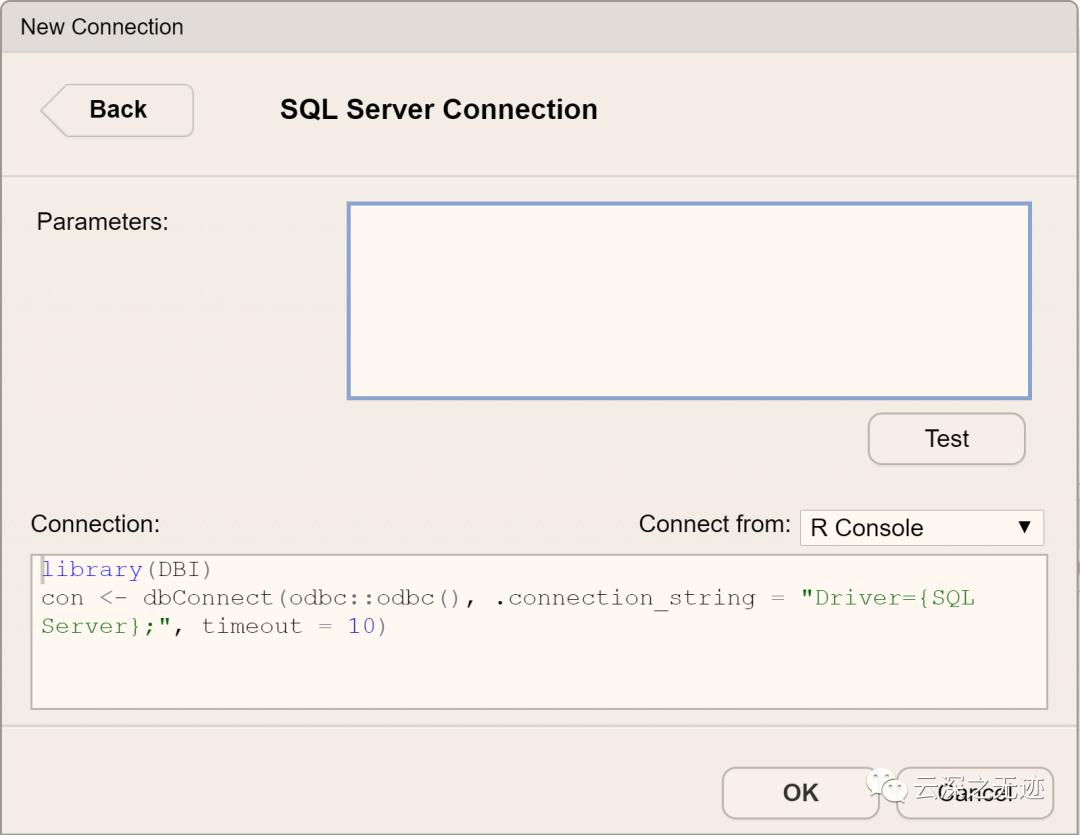
SQL server是微软家的数据库
这个自己看吧
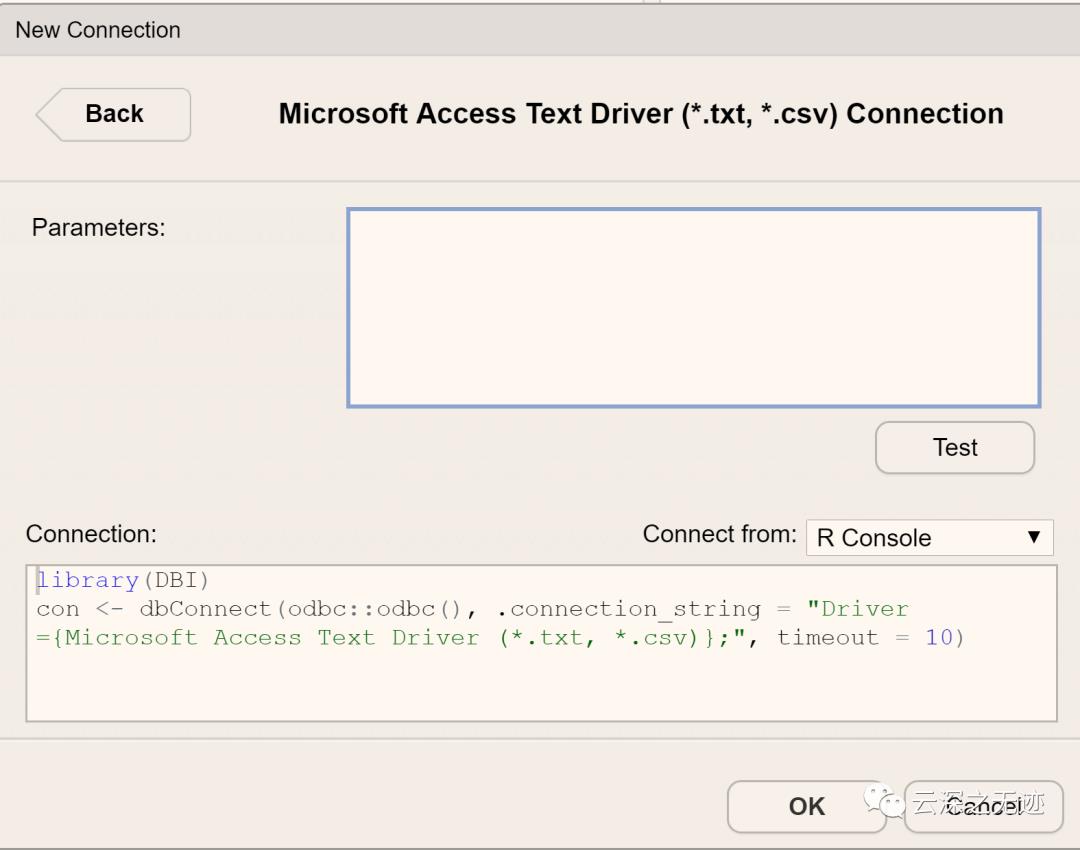
一些普通的文本类型
可以看到具体的命令要流向那些地方
就是unix系统里面的文件流
现在可以认为是重定向

这个是打开一个帮助
可以看到是从清华的数据库里面调用包
这个 是成功的时候的输出的日志(老实讲)真受不了这个红色
我老是以为我写的东西又抛锚了
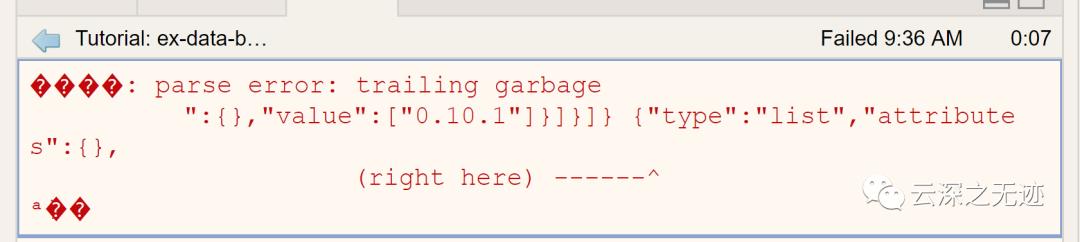
这个错误了,这个是输出了一些错误
大致看的意思是解析错误,大致可以理解为这个地方是传输数据过程受损
在这个窗口,可以看到点这里是打开在线的浏览器
可以看到有下拉框,名字说的很清楚了

这是从 IDE开启时所有的执行的Job 的一个概览

这是输出的日志
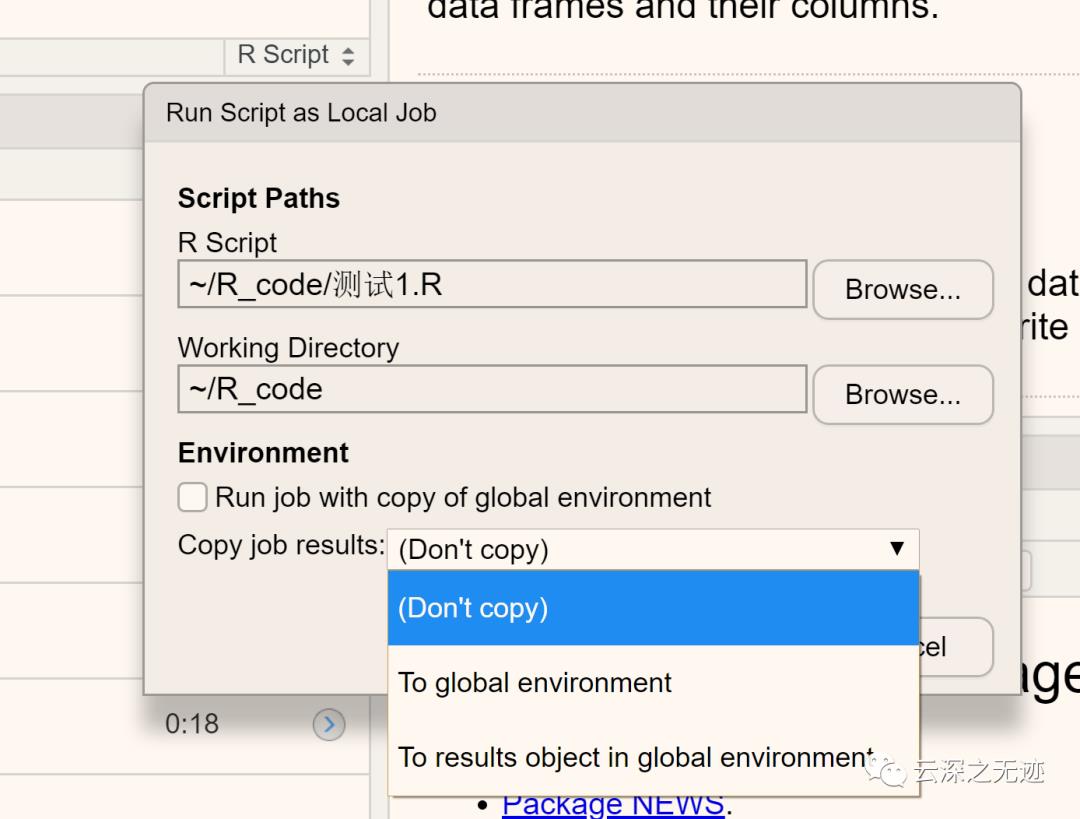
开启一个本地的job

https://www.forbes.com/billionaires/
老师听说我没有数据,给我甩了个网站,一打开.人都傻了.财富?????我个穷逼看这个????浏览器很卡顿,把我卡出去了,我没有拿到数据集
在R中,对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。对象都拥有某种模式,描述了此对象是如何存储的,以及某个类,像print这样的泛型函数表明如何处理此对象。
与其他标准统计软件(如SAS、SPSS和Stata)中的数据集类似,数据框(data frame)是R中用于存储数据的一种结构:列表示变量,行表示观测。在同一个数据框中可以存储不同类型(如数值型、字符型)的变量。数据框将是你用来存储数据集的主要数据结构。
因子(factor)是名义型变量或有序型变量。它们在R中被特殊地存储和处理。
其他多数术语你应该比较熟悉了,它们基本都遵循统计和计算中术语的定义。
这些具体的举例可以看我上篇文章最后的部分。
由于不同的列可以包含不同模式(数值型、字符型等)的数据,数据框的概念较矩阵来说更为一般。它与你通常在SAS、SPSS和Stata中看到的数据集类似。数据框将是你在R中最常处理的数据结构。
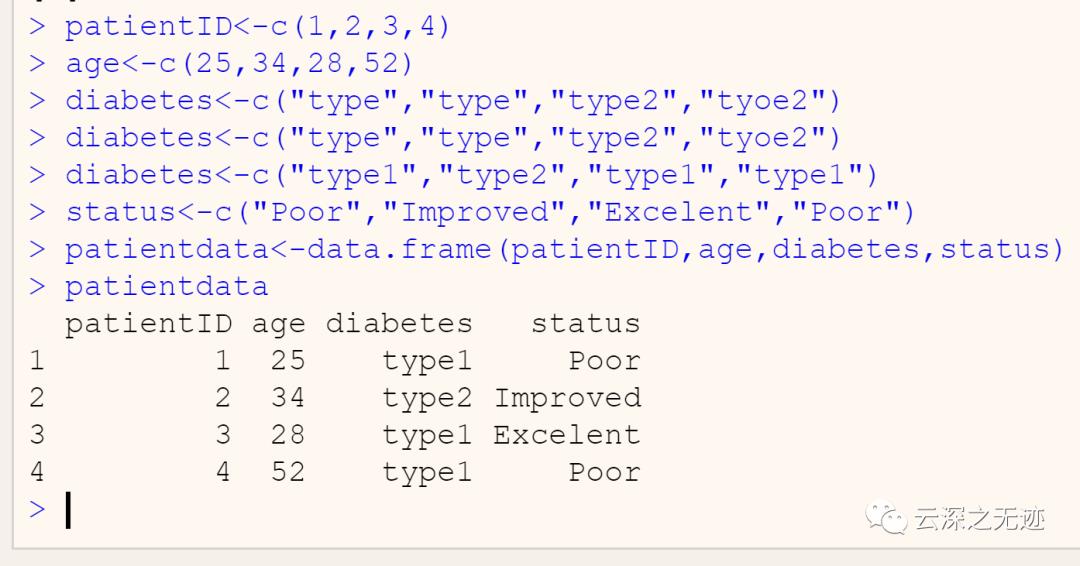
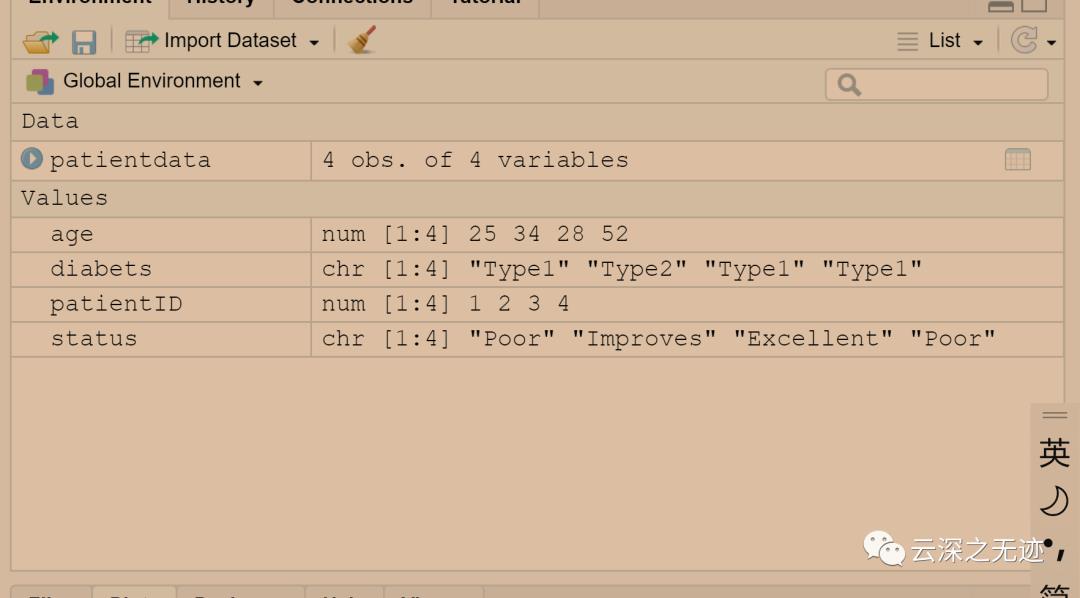
写一个数据框
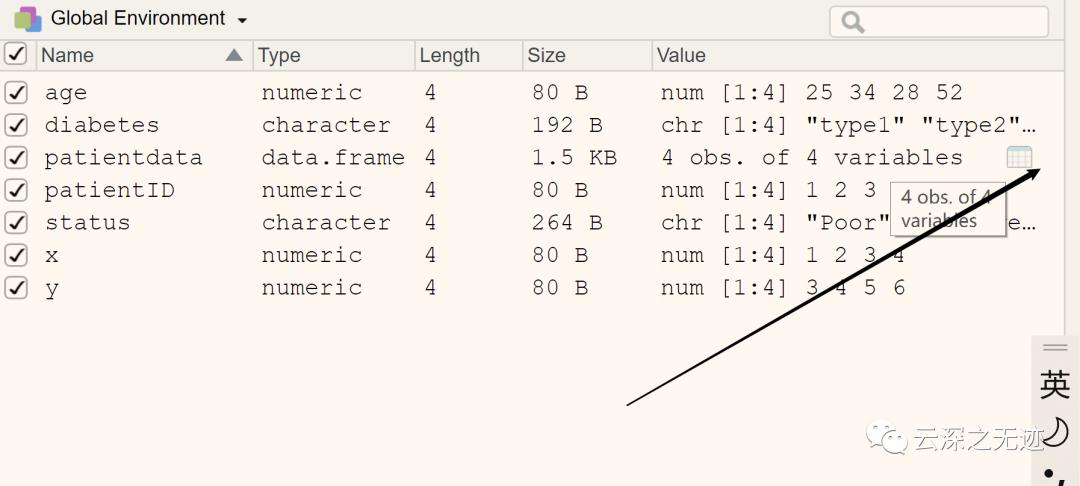
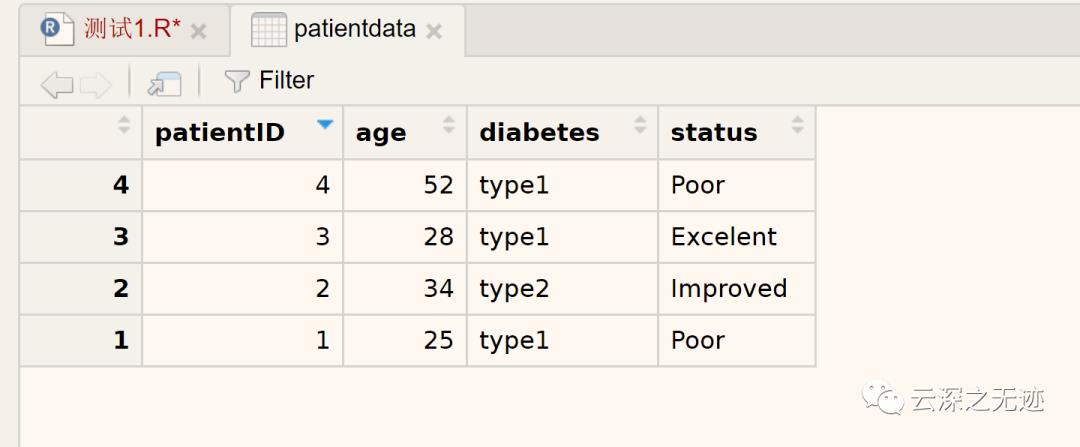
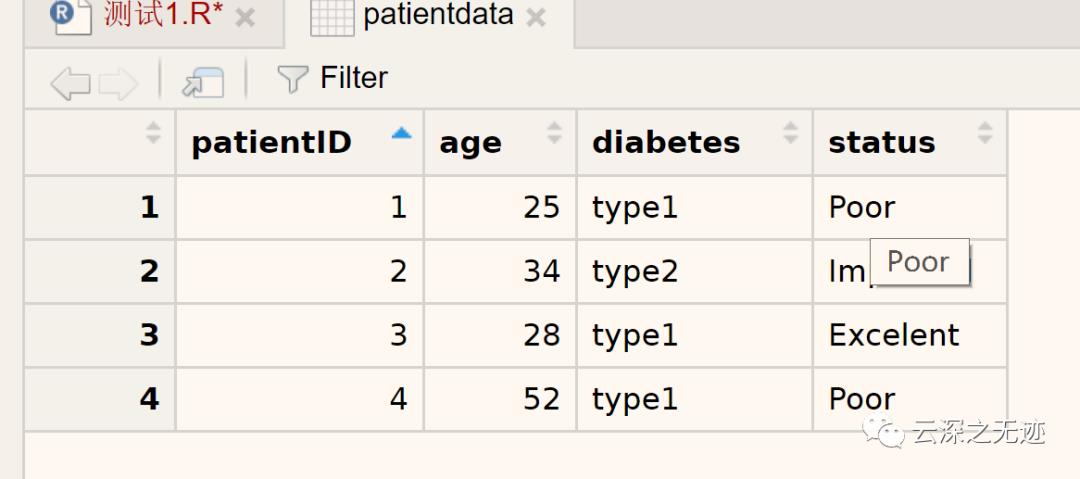
如你所见,变量可归结为名义型、有序型或连续型变量。名义型变量是没有顺序之分的类别变量。糖尿病类型Diabetes(Type1、Type2)是名义型变量的一例。即使在数据中Type1编码为1而Type2编码为2,这也并不意味着二者是有序的。有序型变量表示一种顺序关系,而非数量关系。病情Status(poor、improved、excellent)是顺序型变量的一个上佳示例。我们明白,病情为poor(较差)病人的状态不如improved(病情好转)的病人,但并不知道相差多少。连续型变量可以呈现为某个范围内的任意值,并同时表示了顺序和数量。年龄Age就是一个连续型变量,它能够表示像14.5或22.8这样的值以及其间的其他任意值。很清楚,15岁的人比14岁的人年长一岁。
类别(名义型)变量和有序类别(有序型)变量在R中称为因子(factor)。因子在R中非常重要,因为它决定了数据的分析方式以及如何进行视觉呈现。
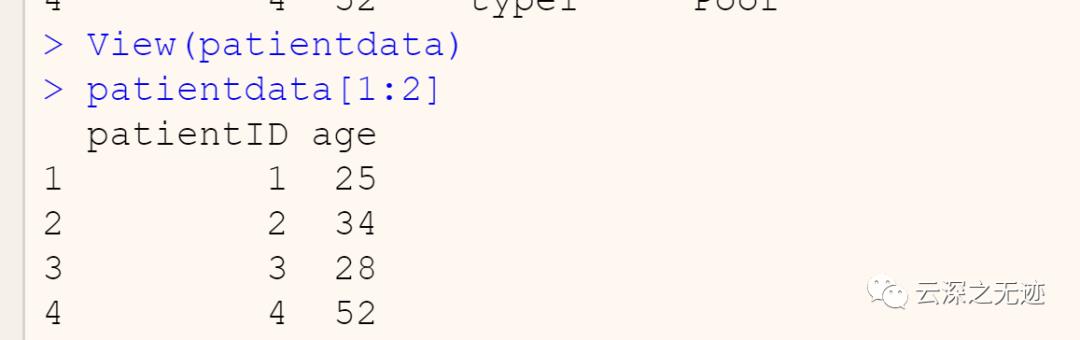

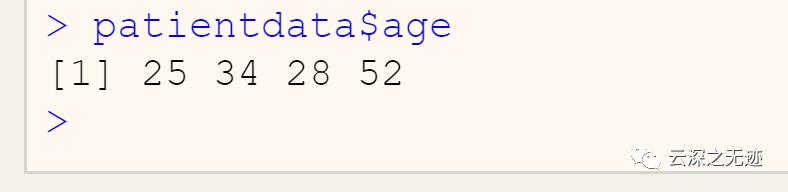
$是用来选取一个变量时用的符号

生成列联表
这样写是不是觉得有点费劲?
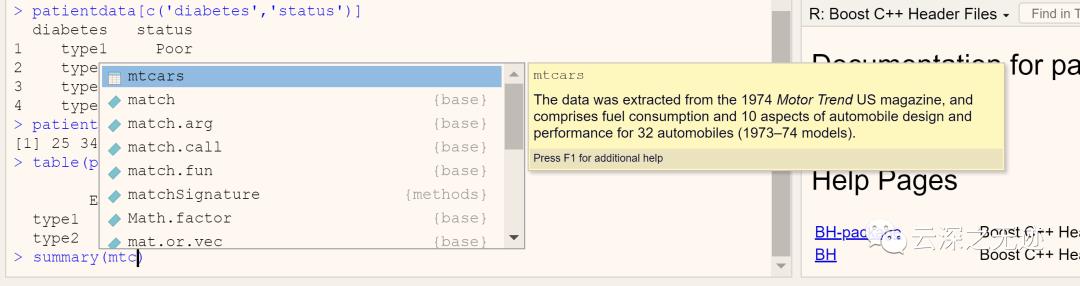
看一下数据集的概览

这个是输出结果
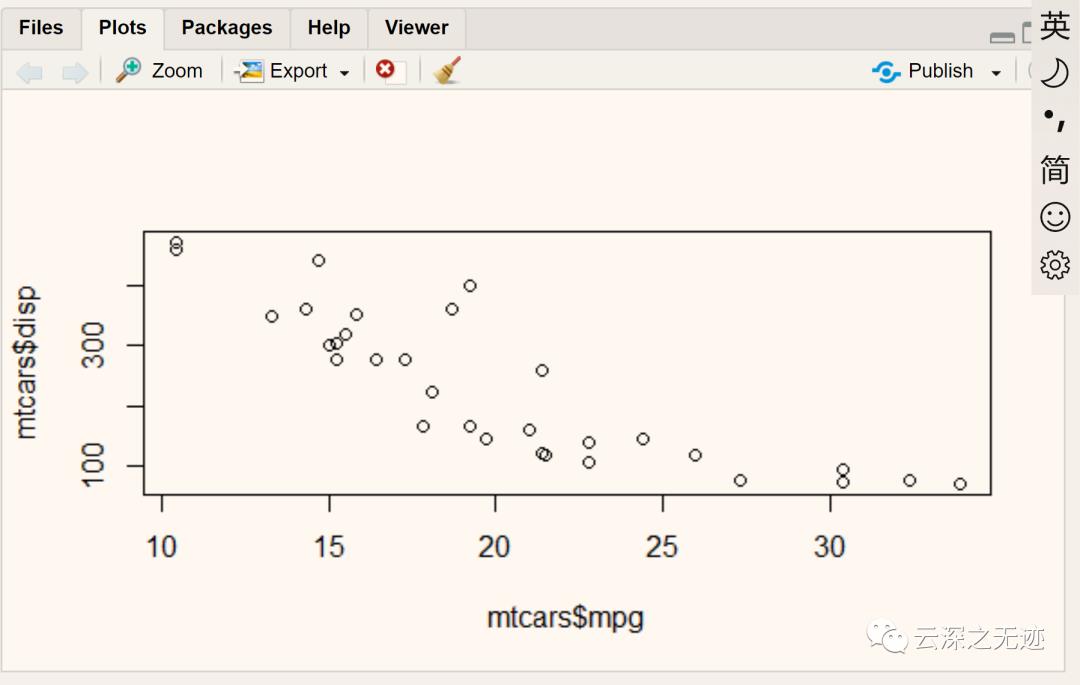
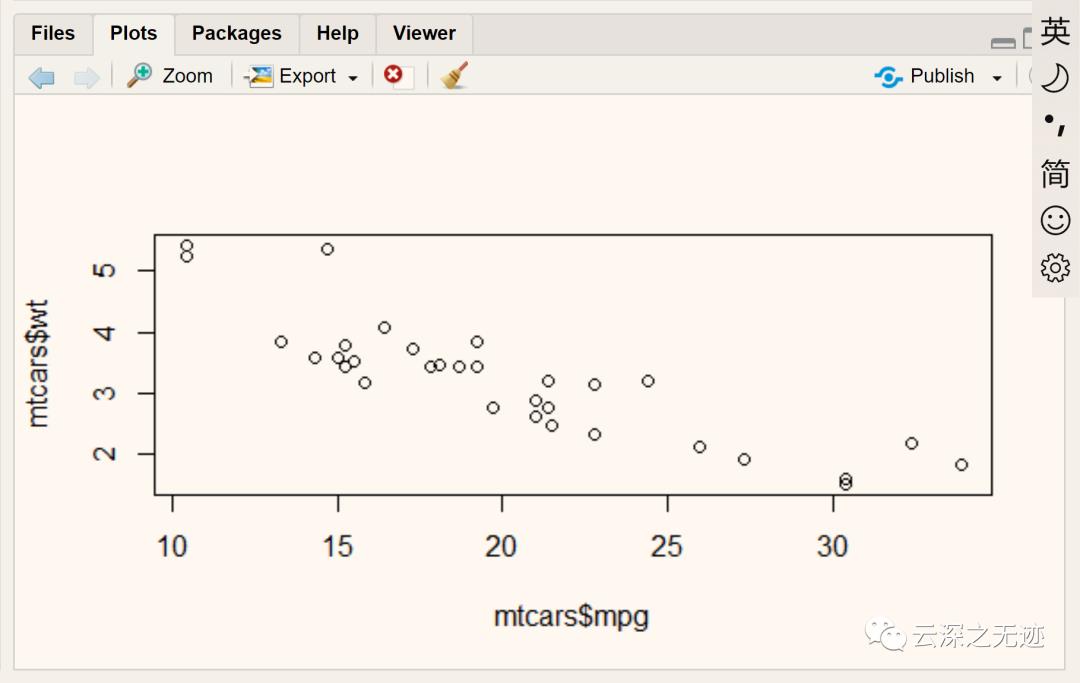

我们可以取
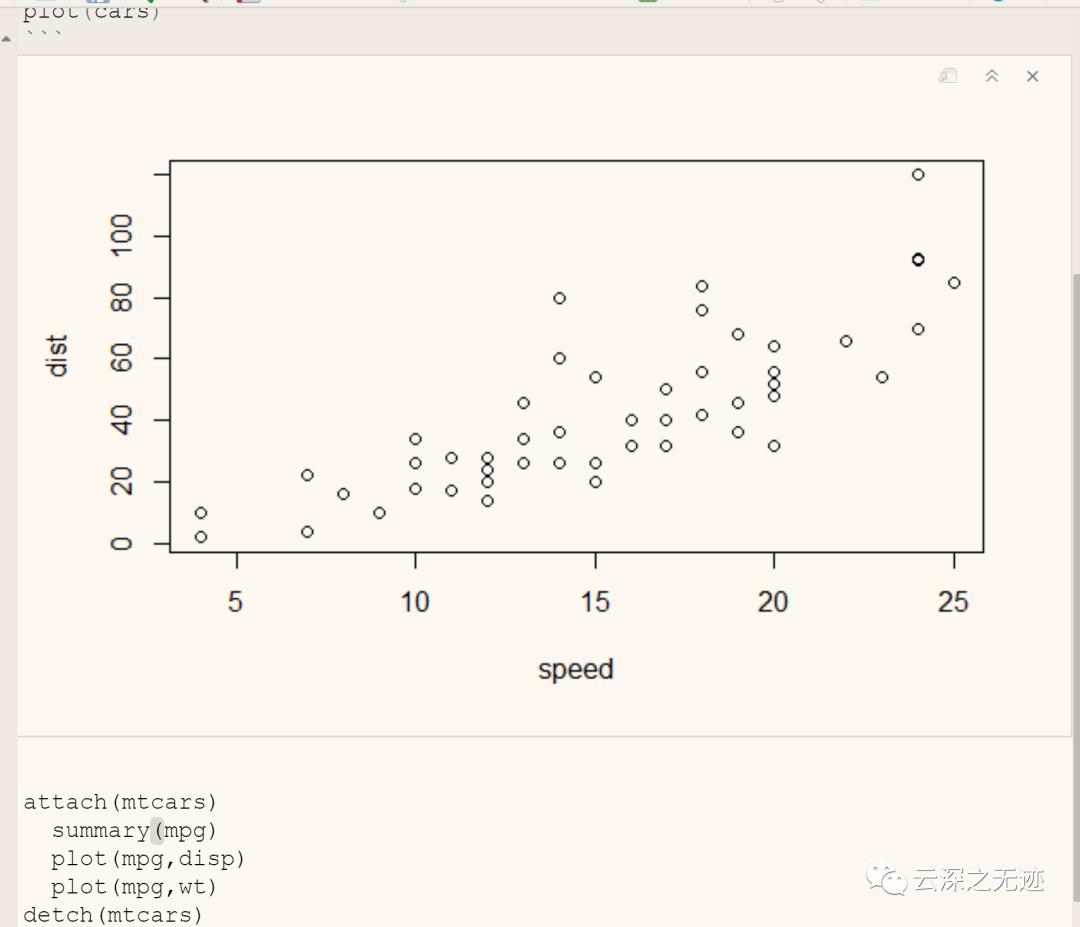

这个是代码
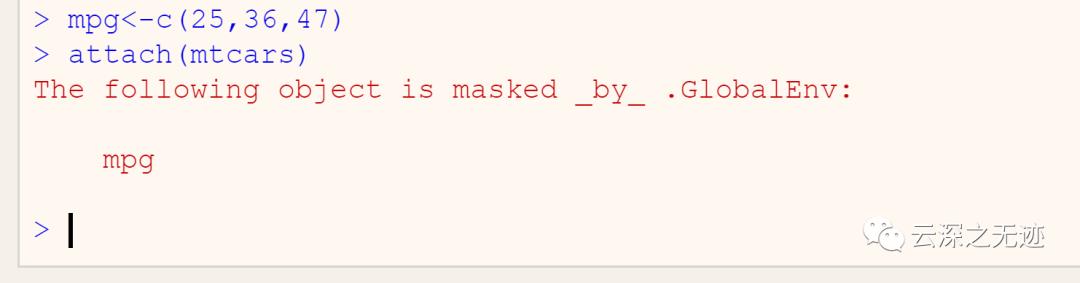

这个是

语句diabetes <- factor(diabetes)将此向量存储为(1, 2, 1, 1),并在内部将其关联为1=Type1和2=Type2(具体赋值根据字母顺序而定)。针对向量diabetes进行的任何分析都会将其作为名义型变量对待,并自动选择适合这一测量尺度[插图]的统计方法。
要表示有序型变量,需要为函数factor()指定参数ordered=TRUE。给定向量:

语句status <- factor(status, ordered=TRUE)会将向量编码为(3, 2, 1, 3),并在内部将这些值关联为1=Excellent、2=Improved以及3=Poor。另外,针对此向量进行的任何分析都会将其作为有序型变量对待,并自动选择合适的统计方法。
对于字符型向量,因子的水平默认依字母顺序创建。这对于因子status是有意义的,因为“Excellent”“Improved”“Poor”的排序方式恰好与逻辑顺序相一致。如果“Poor”被编码为“Ailing”,会有问题,因为顺序将为“Ailing”“Excellent”“Improved”。如果理想中的顺序是“Poor”“Improved”“Excellent”,则会出现类似的问题。按默认的字母顺序排序的因子很少能够让人满意。
你可以通过指定levels选项来覆盖默认排序。例如:
各水平的赋值将为1=Poor、2=Improved、3=Excellent。请保证指定的水平与数据中的真实值相匹配,因为任何在数据中出现而未在参数中列举的数据都将被设为缺失值。
数值型变量可以用levels和labels参数来编码成因子。如果男性被编码成1,女性被编码成2,则以下语句:
sex <- factor(sex, levels=c(1, 2), labels=c("Male", "Female"))
把变量转换成一个无序因子。注意到标签的顺序必须和水平相一致。在这个例子中,性别将被当成类别型变量,标签“Male”和“Female”将替代1和2在结果中输出,而且所有不是1或2的性别变量将被设为缺失值。
以上是关于R语言实战.2的主要内容,如果未能解决你的问题,请参考以下文章