R语言做K均值聚类的一个简单小例子
Posted 小明的数据分析笔记本
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言做K均值聚类的一个简单小例子相关的知识,希望对你有一定的参考价值。
参考链接
-
https://www.guru99.com/r-k-means-clustering.html
-
https://datascienceplus.com/k-means-clustering-in-r/
-
https://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/
k均值聚类是一种比较常用的聚类方法,R语言里做k均值聚类比较常用的函数是kmeans(),需要输入3个参数,第一个是聚类用到的数据,第二个是你想将数据聚成几类k,第三个参数是nstarthttps://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/
这篇链接里提到
默认的nstart是1,推荐使用较大的值,以获得一个稳定的结果。比如可以使用25或者50。
那如果想使用k均值聚类的话,就可以分成两种情况,
-
第一种是知道我自己想聚成几类,比如鸢尾花的数据集,明确想聚为3类。这时候直接指定k 下面用鸢尾花数据集做k均值聚类
df<-iris[,1:4]
iris.kmeans<-kmeans(df,centers=3,nstart = 25)
names(iris.kmeans)
iris.kmeans结果里存储9个结果,可能会用到的是iris.kmeans$cluster存储的是每个样本被归为哪一类iris.kmeans$size存储的是每一个大类有多少个样本
使用散点图展示结果,借助factoextra包中的fviz_cluster()函数
library(factoextra)
fviz_cluster(object=iris.kmeans,data=iris[,1:4],
ellipse.type = "euclid",star.plot=T,repel=T,
geom = ("point"),palette='jco',main="",
ggtheme=theme_minimal())+
theme(axis.title = element_blank())
作图代码参考 https://degreesofbelief.roryquinn.com/clustering-analysis-in-r-part-2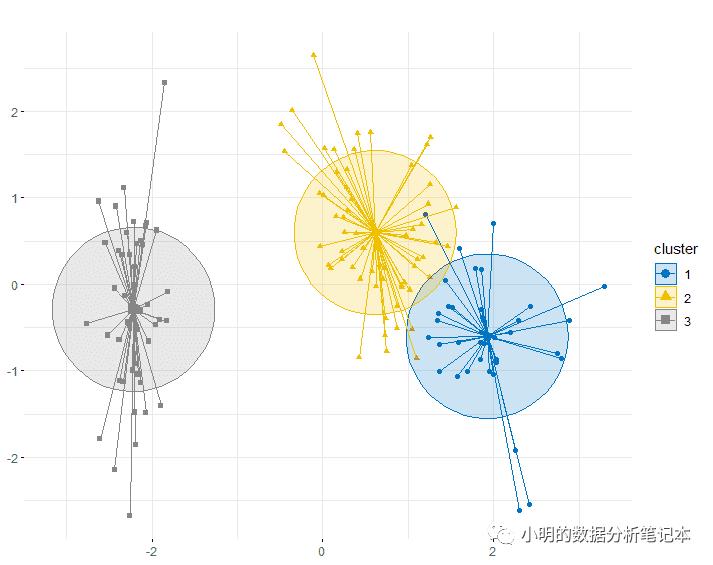
-
第二种情况是我不知道想要聚成几类,这个时候就可以将k值设置为一定的范围,然后根据聚类结果里的一些参数来筛选最优的结果 比如这篇文章 https://www.guru99.com/r-k-means-clustering.html 他提到可以使用 cluster$tot.withinss这个参数,选择出现平滑变化的那个点,他起的名字是 elbow method,英文解释是
This method uses within-group homogeneity or within-group heterogeneity to evaluate the variability. In other words, you are interested in the percentage of the variance explained by each cluster. You can expect the variability to increase with the number of clusters, alternatively, heterogeneity decreases. Our challenge is to find the k that is beyond the diminishing returns. Adding a new cluster does not improve the variability in the data because very few information is left to explain.
这个英文解释我也没有看明白。实际操作的代码是
下面用USArrests这个数据集是美国50个州1973年每10万人中因某种罪被捕的人数,共4个变量
df<-USArrests
kmean_withinss <- function(k) {
cluster <- kmeans(df, k,nstart = 25)
return (cluster$tot.withinss)
}
wss<-sapply(2:20, kmean_withinss)
wss
elbow<-data.frame(A=2:20,B=wss)
library(ggplot2)
ggplot(elbow,aes(x=A,y=B))+
geom_point()+
geom_line()+
scale_x_continuous(breaks = seq(1, 20, by = 1))+theme_bw()
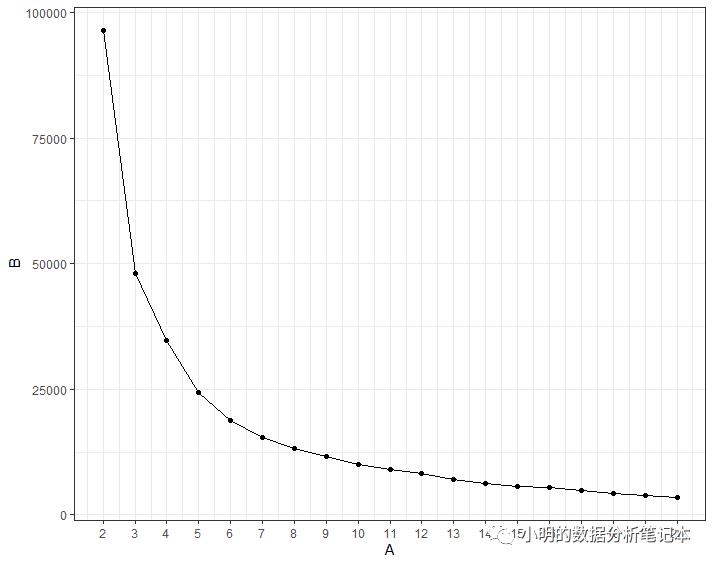
从上图看,7到8好像是变得比较平滑的,那我们先选7看看
usa.kmeans<-kmeans(df,centers=7,nstart = 25)
fviz_cluster(object=usa.kmeans,df,
ellipse.type = "euclid",star.plot=T,repel=T,
geom = c("point","text"),palette='jco',main="",
ggtheme=theme_minimal())+
theme(axis.title = element_blank())
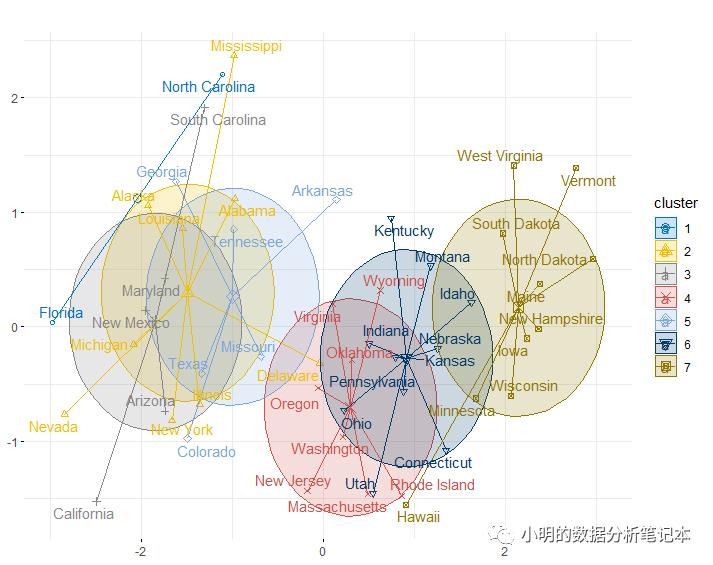
从图上看划分成7类有点多了
https://www.datanovia.com/en/lessons/k-means-clustering-in-r-algorith-and-practical-examples/
这个链接里提到factoextra这个包里有一个函数fviz_nbclust()直接可以选择最优的k
fviz_nbclust(df, kmeans, method = "wss")
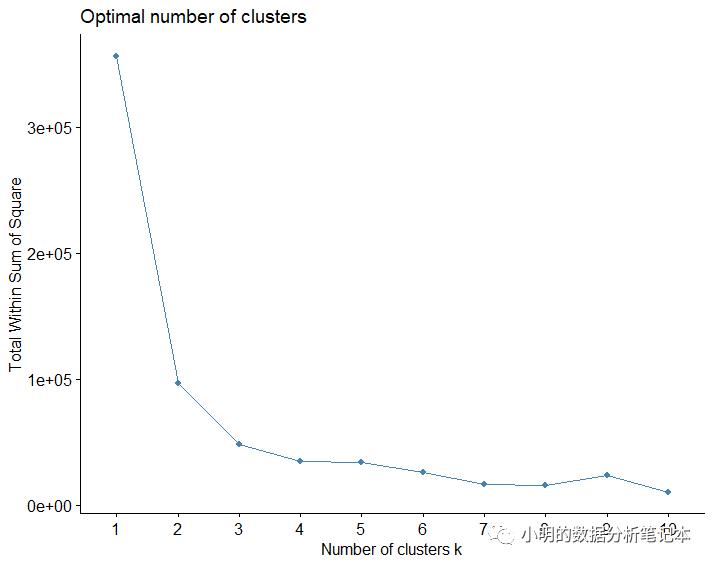
从图上看4到5变得平滑了,选择4试一下
usa.kmeans<-kmeans(df,centers=4,nstart = 25)
fviz_cluster(object=usa.kmeans,df,
ellipse.type = "euclid",star.plot=T,repel=T,
geom = c("point","text"),palette='jco',main="",
ggtheme=theme_minimal())+
theme(axis.title = element_blank())
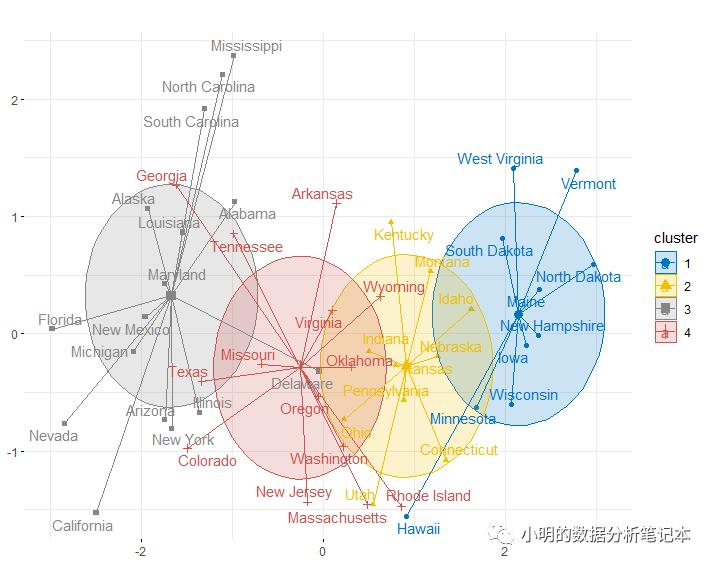
从图上看有部分重叠的地方,还有一种办法就是把数据标准化一下
df1<-scale(df)
usa.kmeans<-kmeans(df1,centers=4,nstart = 25)
fviz_cluster(object=usa.kmeans,df,
ellipse.type = "euclid",star.plot=T,repel=T,
geom = c("point","text"),palette='jco',main="",
ggtheme=theme_minimal())+
theme(axis.title = element_blank())
标准化以后的效果看起来好了很多
好了,今天就到这里了。
小明的数据分析笔记本
以上是关于R语言做K均值聚类的一个简单小例子的主要内容,如果未能解决你的问题,请参考以下文章