R语言:利用机器学习建立信用卡反欺诈模型
Posted 数据小匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言:利用机器学习建立信用卡反欺诈模型相关的知识,希望对你有一定的参考价值。
今天我们将讨论使用机器学习和R概念的信用卡欺诈检测项目。在此R项目中,我们将学习如何进行信用卡检测。我们将介绍各种算法,例如决策树,逻辑回归,人工神经网络,最后是梯度提升分类器。为了进行信用卡欺诈检测,我们将使用包含欺诈行为和非欺诈性交易的Card Transactions数据集。
机器学习项目–如何检测信用卡欺诈
这个R项目的目的是建立一个可以检测信用卡欺诈交易的分类器。我们将使用各种机器学习算法,这些算法将能够区分欺诈性和非欺诈性。在本机器学习项目结束时,您将学习如何实现机器学习算法来执行分类。
此项目中使用的数据集可在此处 – 欺诈检测数据集和代码
1.导入数据集
我们正在导入包含信用卡交易的数据集-
码:
library(ranger)
library(caret)
library(data.table)
creditcard_data <- read.csv("/home/dataflair/data/Credit Card/creditcard.csv")
输入截图:
在继续之前,您必须修改R数据框的概念
2.数据探索
在欺诈检测ML项目的此部分中,我们将探索creditcard_data数据框中包含的数据。我们将使用head()函数和tail()函数显示creditcard_data。然后,我们将继续探索该数据框的其他组成部分–
码:
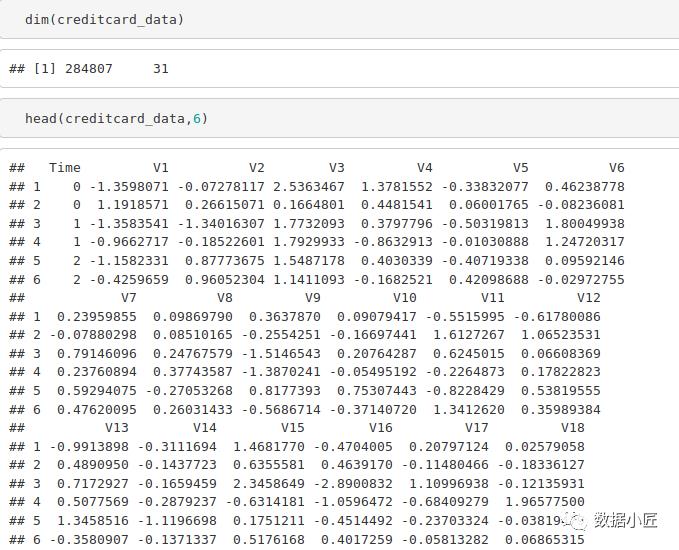
dim(creditcard_data)
head(creditcard_data,6)
输出截图:
码:
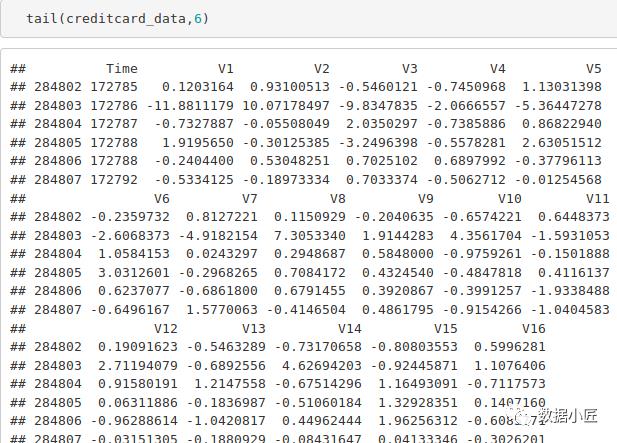
tail(creditcard_data,6)
输出截图:
码:
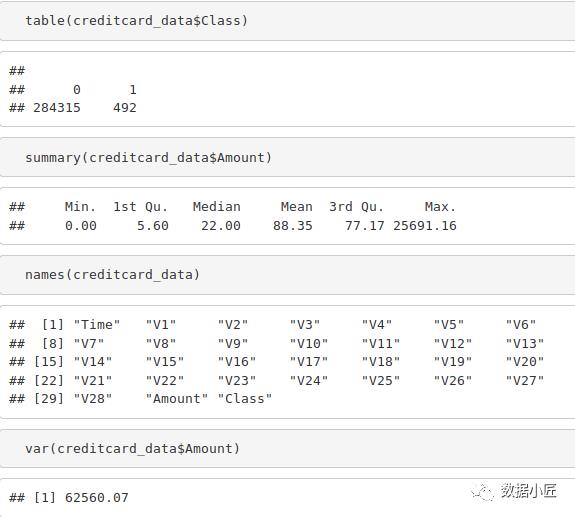
table(creditcard_data$Class)
summary(creditcard_data$Amount)
names(creditcard_data)
var(creditcard_data$Amount)
输出截图:
码:
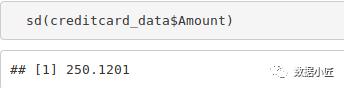
sd(creditcard_data$Amount)
输出截图:
免费学习有关R的所有知识并掌握技术
3.数据处理
在R数据科学项目的这一部分中,我们将使用scale()函数缩放数据。我们会将其应用于creditcard_data金额中的金额部分。缩放也称为特征标准化。借助缩放,可以根据指定范围来构造数据。因此,我们的数据集中没有极值可能会干扰我们模型的功能。我们将执行以下操作:
码:
head(creditcard_data)
输出截图:
码:
creditcard_data$Amount=scale(creditcard_data$Amount)
NewData=creditcard_data[,-c(1)]
head(NewData)
输出截图:
4.数据建模
在对整个数据集进行标准化之后,我们将数据集分为训练集和测试集,分割比率为0.8。这意味着我们80%的数据将归因于train_data,而20%的将归因于测试数据。然后,我们将使用dim()函数找到尺寸
码:
library(caTools)
set.seed(123)
data_sample = sample.split(NewData$Class,SplitRatio=0.80)
train_data = subset(NewData,data_sample==TRUE)
test_data = subset(NewData,data_sample==FALSE)
dim(train_data)
dim(test_data)
输出截图:
5.拟合逻辑回归模型
在此部分的信用卡欺诈检测项目中,我们将训练我们的第一个模型。我们将从逻辑回归开始。Logistic回归用于对分类结果的通过概率进行建模,例如通过/失败,正/负,在我们的案例中为欺诈/非欺诈。我们继续在测试数据上实施以下模型
码:
Logistic_Model=glm(Class~.,test_data,family=binomial())
summary(Logistic_Model
输出截图:
总结完模型后,我们将通过以下图表将其可视化–
码:
plot(Logistic_Model)
输入截图:
![]()
输出:
输出:
输出:
输出:
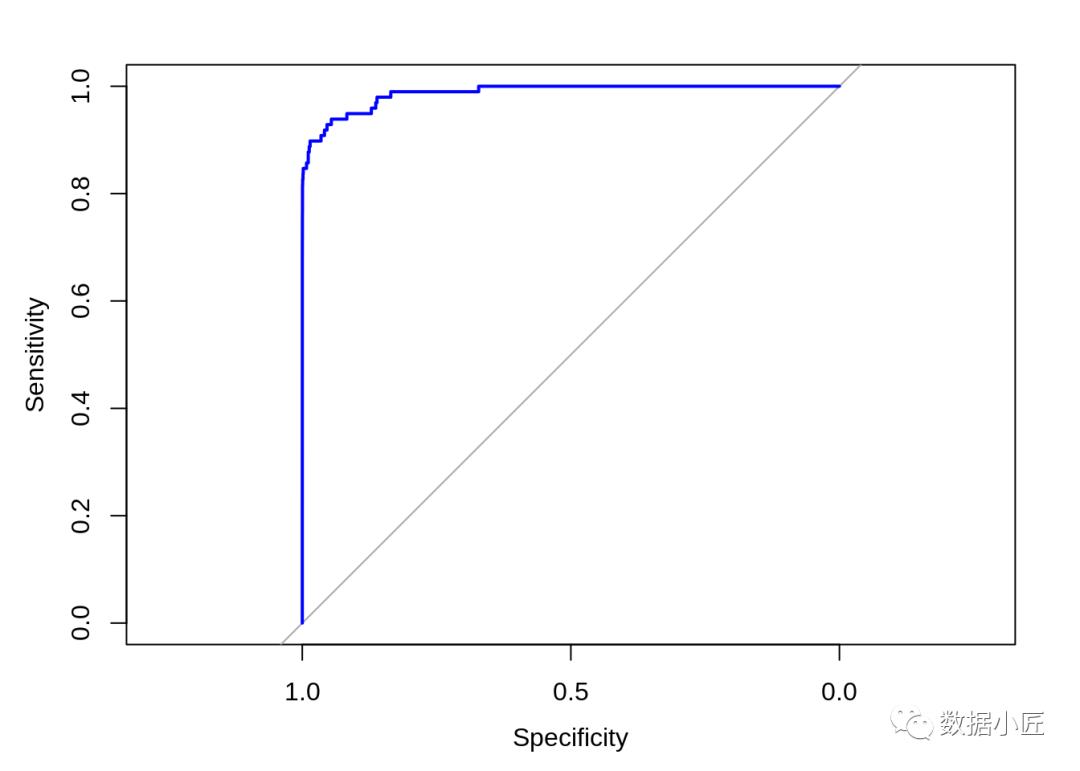
为了评估模型的性能,我们将画出ROC曲线。ROC也称为接收器乐观特征。为此,我们将首先导入ROC程序包,然后绘制ROC曲线以分析其性能。
码:
library(pROC)
lr.predict <- predict(Logistic_Model,test_data, probability = TRUE)
auc.gbm = roc(test_data$Class, lr.predict, plot = TRUE, col = "blue")
输出截图:

输出:
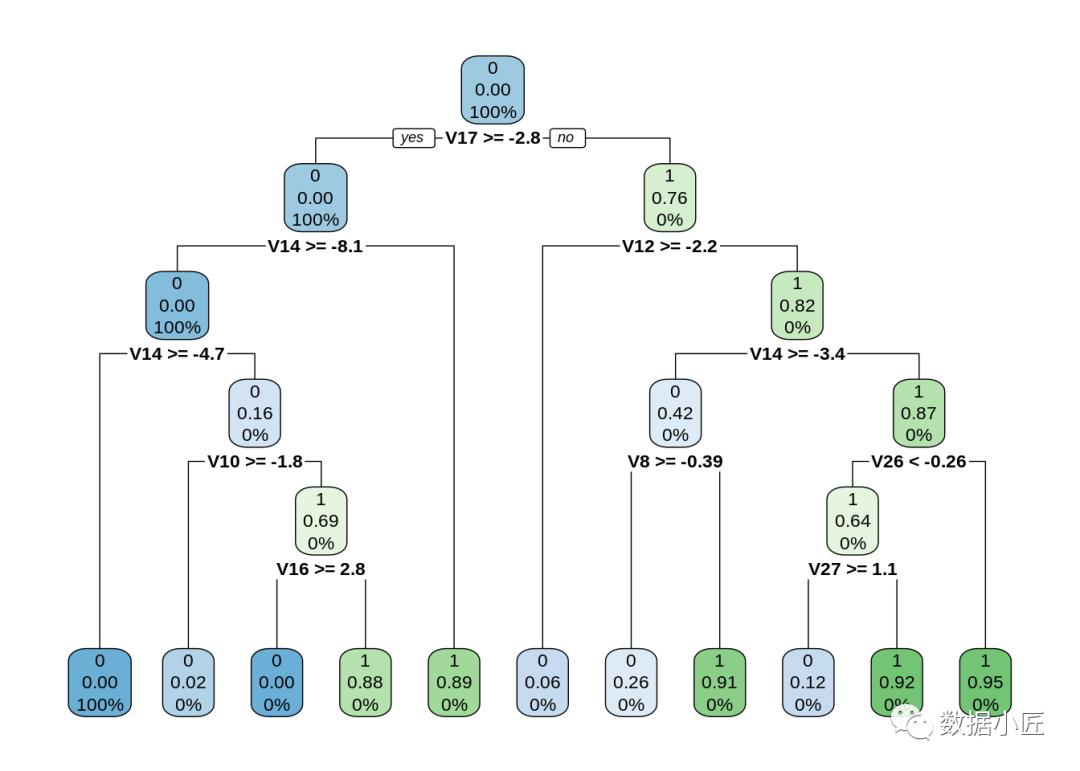
6.拟合决策树模型
在本节中,我们将实现决策树算法。决策树,用于绘制决策结果。这些结果基本上是一种结果,通过它我们可以得出对象所属的类的结论。现在,我们将实现决策树模型,并使用rpart.plot()函数对其进行绘制。我们将特别使用递归分型来绘制决策树。
码:
library(rpart)
library(rpart.plot)
decisionTree_model <- rpart(Class ~ . , creditcard_data, method = 'class')
predicted_val <- predict(decisionTree_model, creditcard_data, type = 'class')
probability <- predict(decisionTree_model, creditcard_data, type = 'prob')
rpart.plot(decisionTree_model
输入截图:

输出:
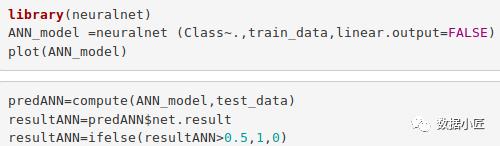
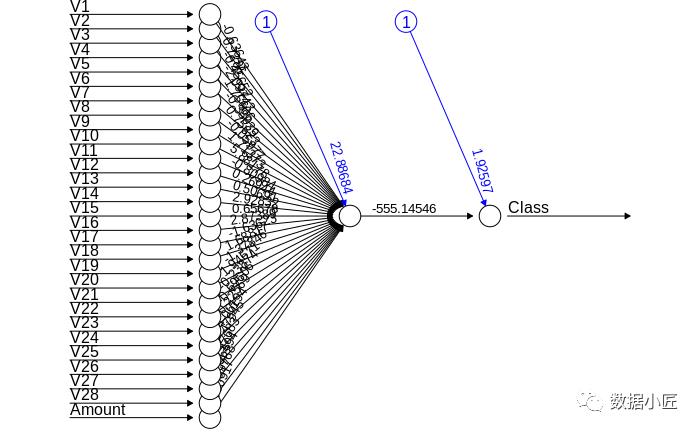
7.人工神经网络
人工神经网络是一种模仿人类神经系统的机器学习算法。人工神经网络模型能够使用历史数据学习模式,并能够对输入数据进行分类。 我们导入了Neuronet软件包,该软件包将允许我们实现ANN。然后,我们使用plot()函数对其进行绘制。现在,在人工神经网络的情况下,存在一个介于1到0之间的值。我们将阈值设置为0.5,即,大于0.5的值将对应于1,其余的将为0。我们实现了这一点。如下 -
码:
library(neuralnet)
ANN_model =neuralnet (Class~.,train_data,linear.output=FALSE)
plot(ANN_model)
predANN=compute(ANN_model,test_data)
resultANN=predANN$net.result
resultANN=ifelse(resultANN>0.5,1,0)
输入截图:
输出:
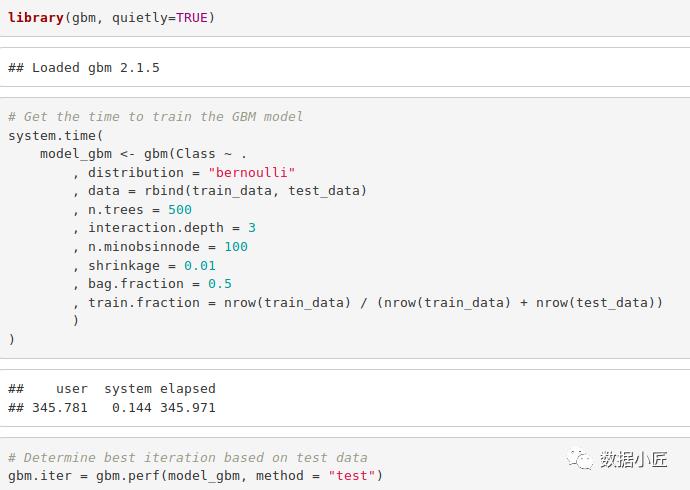
8.Gradient Boosting(GBM)
Gradient Boosting (梯度提升)是一种流行的机器学习算法,用于执行分类和回归任务。该模型由几个基础集成模型组成,例如弱决策树。这些决策树组合在一起,形成一个强大的梯度提升模型。我们将在我们的模型中实现梯度下降算法,如下所示–
码:
library(gbm, quietly=TRUE)
# Get the time to train the GBM model
system.time(
model_gbm <- gbm(Class ~ .
, distribution = "bernoulli"
, data = rbind(train_data, test_data)
, n.trees = 500
, interaction.depth = 3
, n.minobsinnode = 100
, shrinkage = 0.01
, bag.fraction = 0.5
, train.fraction = nrow(train_data) / (nrow(train_data) + nrow(test_data))
)
)
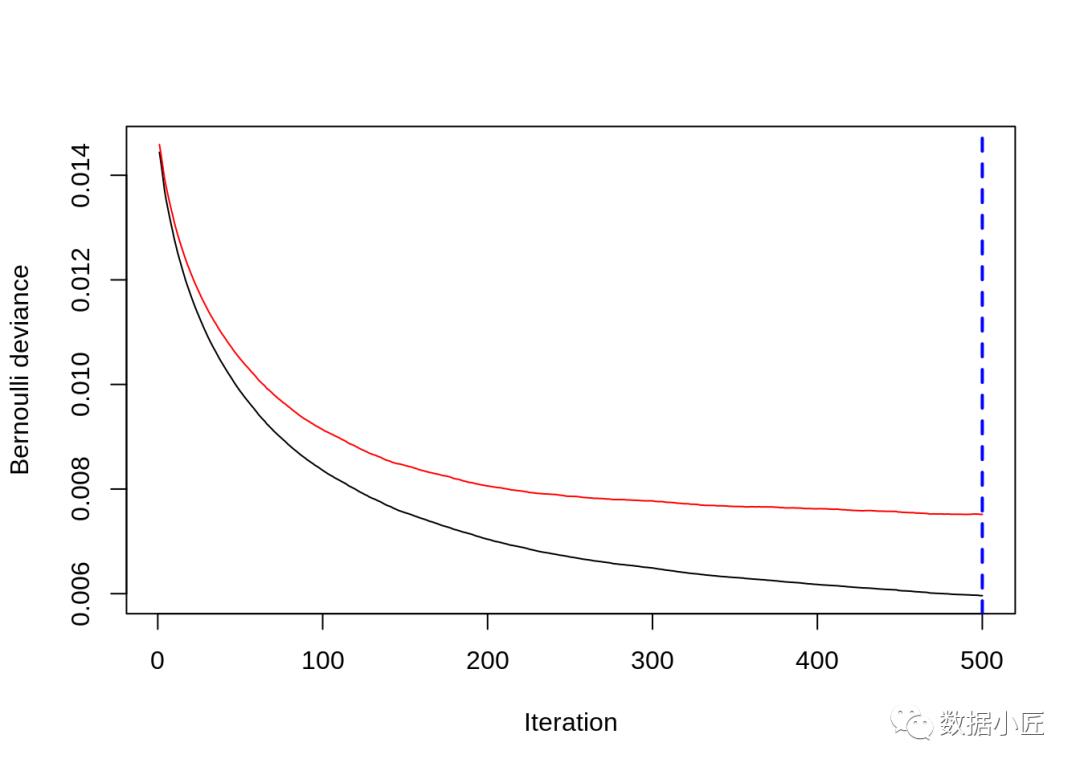
# Determine best iteration based on test data
gbm.iter = gbm.perf(model_gbm, method = "test")
输入截图:
码:
model.influence = relative.influence(model_gbm, n.trees = gbm.iter, sort. = TRUE)
#Plot the gbm model
plot(model_gbm)
输入截图:

输出:
输出:
码:
#根据测试数据绘制并计算AUC
gbm_test = predict(model_gbm, newdata = test_data, n.trees = gbm.iter)
gbm_auc = roc(test_data$Class, gbm_test, plot = TRUE, col = "red")
输出截图:
码:
print(gbm_auc)
输出截图:
总结
在完成R Data Science项目之后,我们学习了如何使用机器学习开发信用卡欺诈检测模型。我们使用了多种ML算法来实现该模型,并绘制了模型的各自性能曲线。我们了解了如何分析和可视化数据以区分其他类型数据的欺诈性交易。
因此,现在您可以检测到欺诈了。
以上是关于R语言:利用机器学习建立信用卡反欺诈模型的主要内容,如果未能解决你的问题,请参考以下文章