用菜鸟的视角,去窥视JVM虚拟机的微观和宏观世界
Posted 耄耋少年矣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用菜鸟的视角,去窥视JVM虚拟机的微观和宏观世界相关的知识,希望对你有一定的参考价值。
什么是jvm:
JVM就是java虚拟机,它是一个虚构出来的计算机,可在实际的计算机上模拟各种计算机的功能。JVM有自己完善的硬件结构,例如处理器、堆栈和寄存器等,还具有相应的指令系统。
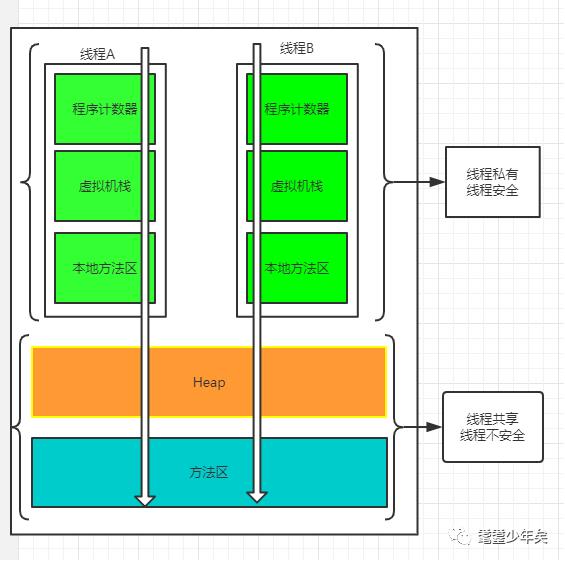
讲到jvm肯定会讲到 jvm的“运行时数据区”:
如上图:
又可以把其分为:数据区、指令区。(程序写的不外乎就是:数据、指令、控制)
指令区:
程序计数器:
1. 每个线程拥有一个程序计数器,并线程私有(线程安全);
2. 可以看作是当前线程所执行的字节码文件(class)的行号“指示器”。
为什么需要这个程序计数器呢?
因为CUP的执行程序的时候,是以时间片段的方式进行线程的调度,在多线程的程序中,线程与线程之间会不断的切换,当线程A在执行的时候,线程B争取到了CPU的资源,此时线程B执行,线程A被挂起,那么这时线程A的程序计数器会标记一下当前线程所执行到的地方,当下一次线程A争取到CPU的资源要执行的时候,就需要这个程序计数器告诉线程A该从哪里开始继续执行。
虚拟机栈(JVM栈):
1. 每当启动一个新线程的时候,java虚拟机都会给它分配一个java栈,所以也是线程安全的。
2. 虚拟机栈描述的是Java方法执行的内存模型。(这句话具体是什么意思呢?如下)
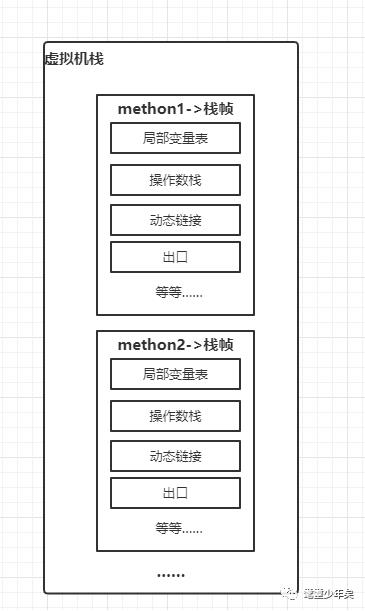
且看虚拟机栈里面装的是什么?
其里面装着是栈帧,每当线程执行到一个方法的时候,就会创建一个栈帧,压入虚拟机栈。
栈帧里面又包含了:局部变量表、操作栈数、动态链接、出口,等等信息
1. 操作数栈:其实它也是个栈,线程在执行方法的时候(基本数据类型),如执行到int i = 1的时候,向操作数栈里压栈压入1。局部变量表会记录此局部变量i。
2. 局部变量表:然后操作数栈出栈1,并装载到局部变量表的某个位置,这个位置是和变量对应的。
把局部变量表和操作栈结合起来理解一下,如下面的例子:

当线程执行到methond1的时候,它的执行过程:
1、执行methond1的时候,创建一个栈帧1
2、把形参i的值装载在局部变量表的第1个位置-> i(初始位置是1,不是0)
3、把0压倒操作数栈
4、0从操作数栈出栈,装载到局部表露表的第2个位置-> j
5、先把i的值压入操作数栈,再把j的值压入操作数栈
6、对压入的这两个值进行相加得出一个结果值,再对此结果值压入操作数栈
7、此结果值从操作数栈出栈,并装载到局部变量表的第3个位置-> sum
8、执行到methond2方法时,即使是methond1里嵌套了方法methond2,故又会创建一个栈帧2压入虚拟机栈中,等执行完methond2后,栈帧2从虚拟机栈出栈,methond1执行完后栈帧1也从虚拟机栈中出栈(栈是先进后出)
动态链表:
学过java应该都知道多态,如下面的代码
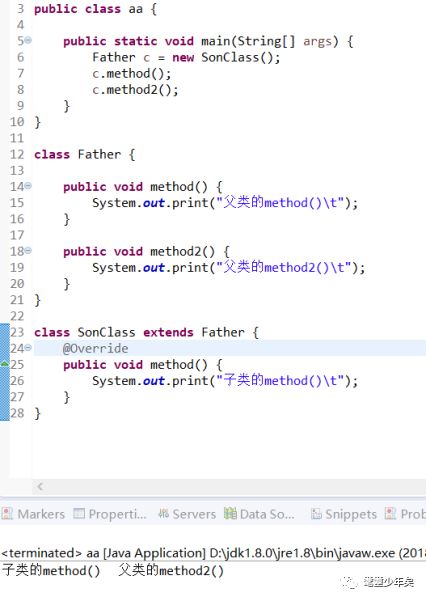
多态的时候在编译期间,是确定不了要执行哪个方法的,Father.methond()还是SonClass.method(),只有在运行是才能确定到底要执行谁。
这里就是动态链接所做的事情了,这里它会到常量池(常量池不只包含常量的引用)找具体类对象的符号,即类信息的引用,然后确定到底执行谁。
出口:就是执行完方法后的出口,如return回去,还是从抛出异常出去等等
本地方法栈:
本地方法栈描述的是本地方法,带有native修饰的方法,本地方法是不会被java去实现的,其是被C 、C++去实现的。
方法区:
存放着类型信息(class),比如类的版本号,类的字段属性等等,还有常量、静态变量、JIT(即时编译器(JIT compiler,just-in-time compiler)是一个把Java的字节码转换成可以直接发送给处理器的指令的程序)等等
终于来到重头戏了:堆(Heap)
讲到堆就离不开JVM内存模式:
Jdk1.8(不包括8)之前的内存模式:
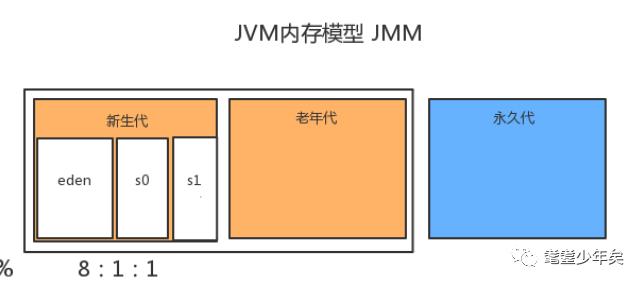
Jdk1.8之后的内存模式:
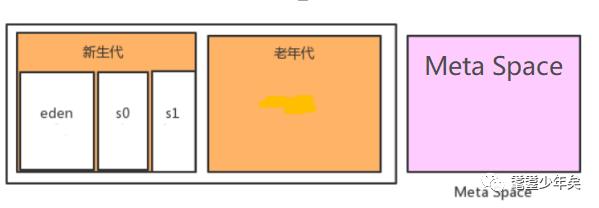
新生代和老年存在堆里面,而永久代是存在方法区里。
而Jdk1.8之后,Meta Space取而代之,Meta Space是直接裸漏在内存里,它规避了永久代溢出的问题。
Meta Space是可以可以自动扩容的,从而就可能会引起另外一个问题,当Meta Space扩容大到一定的程度的时候,就会占用新生代和老年代的内存空间,所以说Meta Space并不是越大越好,把握好度。
我们注意到,新生代里分为eden区、s0区(survivor form区)、s1区(survivor to区),其空间大小比例是8:1:1,都是存放对象的区域。那为什么会有不同的三个区呢。这就涉及到GC的回收机制了。
在新生代涉及的垃圾回收算法是:该算法会划分两块同样大小的内存区域,区域1存放对象,并对此区域进行垃圾回收,然后,没有被回收到的对象,被复制到区域2,如图:
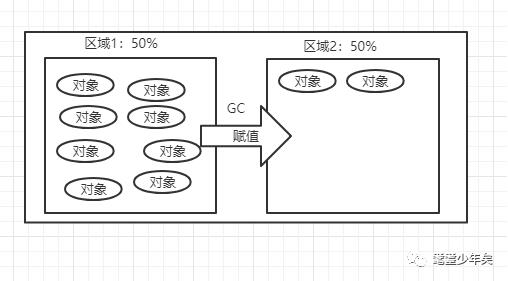
那什么样的对象需要被GC(回收)?
一般来说,有两种算法(强引用,弱引用,软引用,虚引用不在此算法讨轮范围内):
1. 引用计算法:
当一个对象被引用一次就进行加1,如 :Object o =new Object(),就进行加1,当Object a = o 的时候(对象又被引用了一次),再加1,此时等于2,如果进行操作:o = null 置空的时候,少了一个对象的引用,就进行减1,然后在a = null,又减1,此时对象的引用计算为0了,就可以被回收了。
此时让我联想到了,以前框架代码中business层的相互嵌套引用,事务层的相互嵌套引用,导致了引用计算不会等于0,即导致不能被回收。所以一般使用第二种算法
2. 可达性分析算法,如图:
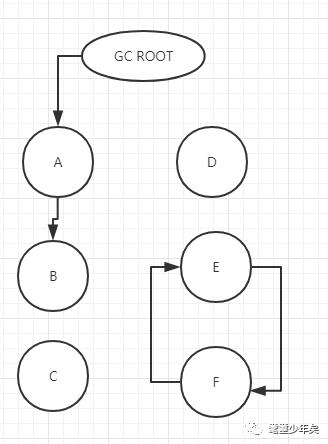
当哪个对象不能回溯到GC ROOT的,就需要回收了,C、D、E、F都不能回溯到GC ROOT,所以它们都需要被回收。
那么谁可以成为GC ROOT呢?
1. 虚拟机栈中本地表量表的引用对象,即正在执行方法中被直接引用的对象。
2. 方法区中,类静态变量引用的对象、常量引用的对象
3. 本地方法栈中JNI引用的对象
不可达是不是就一定会被会收?
不一定。而且类在被回收前,会执行一次finalize()方法,可在此做一些引用的操作,达到可达状态,挽救此对象,不被回收。但杜绝这种挽救。至于为什么,《高效编程》一书中有说明。
接下来就要讨论一下“对象”的这辈子:

Object object =new Object()的时候,生成一个对象,在eden区域开发一块区域存放此对象,这里就涉及到一个内存分配问题:新生代的eden是属于堆里面的,是线程共享,线程不安全的,每个线程都可以来到这里为自己对象划分空间,那这样是不是要对划分空间进行同步?必须的,即同一时刻,只能允许一个线程来到此地进行空间划分,这样子就会导致其他线程阻塞,造成性能低下的问题。
因此在为对象分配上采用一种栈上分配的策略,即是每个线程都会在此内存空间有一个属于自己栈(Thread Local Allaction Buffer),在属于自己的栈上进行为对象分配空间,这样就不会造成以上的问题啦,机智如我。
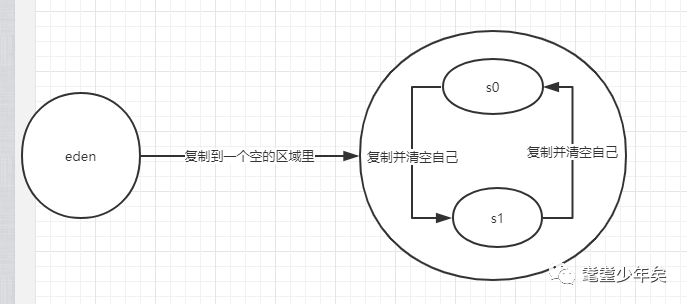
分配完成后,新生代是如何进行GC回收的呢?
如上图,当eden区域快要满的时候,启动一次GC回收,回收算法是复制回收算法,然后一小部分不能被回收的对象,复制到s0区域,eden清空自己。
一段时间后,eden区域又满了,又进行同样的回收,不能被回收的对象,此时是被复制到s1区,然后,s0把存在自己的对象,复制到s1区,s0并清空自己。
又一段时间后,eden清空后又满了又进行GC回收,不能回收的对象复制到了s0区,然后s1区也把自己对象复制s0区,如此反复。
当s0 或s1区域也满了的时候,或者在s0、s1经过多次Minor GC回收后还存活的对象,就把其对象复制到老年代,在复制到老年代之前,新生代会看老年代的空间够不够用,这个机制叫作,分配担保,够用则担保成功,复制到老年代。如老年的空间不够用了,则担保失败,就触发一系列更大GC回收,以至可以s0或s1的对象可以复制到老年代(则空间够用)。
此间少年又有个问题了,为什么要设计s0区和s1区,并做如此反复繁琐的操作?(为什么要有Survivor区)
设置两个Survivor区最大的好处就是解决了碎片化。
下面我们来分析一下。 为什么一个Survivor区不行?
假设现在只有一个survivor区,我们来模拟一下流程: 刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。这样继续循环下去,下一次Eden满了的时候,问题来了,此时Survivor区也进行Minor GC回收,Eden和Survivor各有一些存活对象,如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。
绘制了一幅图来表明这个过程。其中色块代表对象,白色框分别代表Eden区(大)和Survivor区(小)。Eden区理所当然大一些,否则新建对象很快就导致Eden区满,进而触发Minor GC,有悖于初衷。
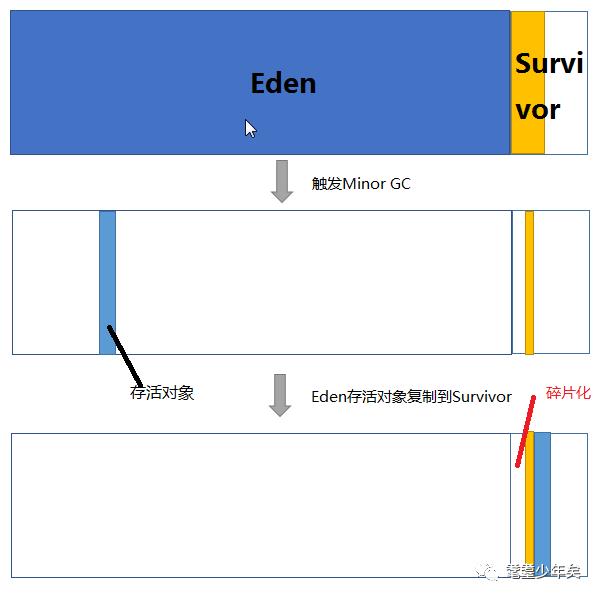
碎片化带来的风险是极大的,严重影响Java程序的性能。堆空间被散布的对象占据不连续的内存,最直接的结果就是,堆中没有足够大的连续内存空间,接下去如果程序需要给一个内存需求很大的对象分配内存。。。画面太美不敢看。。。
这就好比我们爬山的时候,背包里所有东西紧挨着放,最后就可能省出一块完整的空间放相机。如果每件行李之间隔一点空隙乱放,很可能最后就要一路把相机挂在脖子上了。
关于对象回收还有一个知识点,就是强引用、软引用、弱引用、虚引用(以下讨论的前提都是GC ROOT可达的情况下)
强引用:就是我们经常用到的,Object 0 = new Object();生成对象,并引用;
软引用(SoftReference ):在进行GC回收的时候,会判断内存空间够不够,如果不够了进行回收(使用场景:做缓存感觉不错)
弱引用(WeakReference):在进行GC回收的时候,无论内存空间够不够,都进行回收
虚引用(PhantomReference):顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。 虚引用主要用来跟踪对象被垃圾回收器回收的活动。
虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关联的引用队列中。
时光飞逝,日月如梭,内存最终变得满满的了,这时又是怎样的一个回收呢?
先来看一下回收的方法论:
标记-清除算法
复制回收算法
标记-整理算法
再看一下JVM垃圾回收器:
Serial、ParNew、Parallel Scavenge、CMS、Serial Old、Parallel Old、G1
主要看下面四种:
1. Serial 串行垃圾回收器 (单线程)
2. Parallel 并行垃圾回收器 (多线程)
3. CMS 并发标记扫描垃圾回收器
4. G1 G1垃圾回收器
然而,垃圾回收器和回收算法是什么样的关系呢?
我的理解是:某种机器采用了某种算法的运行方式,进行对某种产品进行操作。
标记-清除算法:
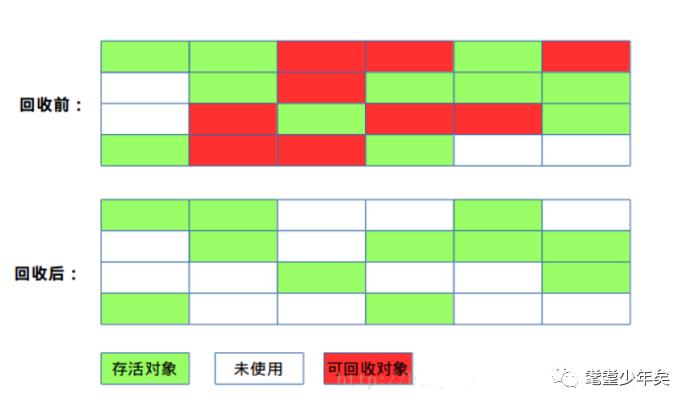
有两个不连续内存中有两个对象被标记了需要回收,进行标记-清除算法被标记了进行GC回收,有些被标记的对象进行回收了,有些并没有。此算法会产生碎片空间。
复制回收算法:上面已经解释过,补充一点:此算法会把对象赋值到连续的内存空间里,不会产生碎片空间。
标记-整理算法:
此算法进行标记需要回收对象之后,并对该回收的对象进行回收,并且会对存活的对象进行整理:并对象移到连续的内存空间,避免产出碎片空间,让空间利用最大化。即所谓的内存压缩。
四种主要回收器的理解,如下图:
新生代:
Serial 串行垃圾回收器 (单线程):
只有一个GC回收线程进行垃圾回收,而且在进行垃圾回收的时候,用户的线程阻塞,当此次GC完成之后,用户线程才能再次进入运行状态。用于新生代的单线程收集器,用复制算法。
优点:简单高效
缺点:垃圾收集的过程中会Stop The World(用户线程阻塞),停顿时间长。
ParNew收集器:其实就是Serial收集器的多线程版本。用于新生代,也是复制算法。
Parallel 并行垃圾回收器 (多线程):在Serial基础上,开启了多线程进行对垃圾回收,提高了多核cpu的利用率
Parallel Scavenge:新生代收集器,复制算法,几乎和ParNew没啥区别。但是,他主要追求高吞吐量,高效利用CPU。吞吐量一般为99%, 吞吐量= 用户线程时间/(用户线程时间+GC线程时间)。适合后台应用等对交互相应要求不高的场景。
老年代:
Serial Old:用于老年代的单线程收集器。用标记-整理算法。
Parallel Old:是作用于老年代的Parallel Scavenge收集器版本,并行收集器,吞吐量优先。用标记-整理算法。
CMS 并发标记扫描垃圾回收器 :如图有几个阶段
1. 单线程快速标记可达对象,为什么会快速呢,因为此阶段只标记直接和GC ROOT关联的对象,此时用户线程是阻塞的
2. 并行标记,此时用户线程和标记线程并行执行,此阶段标记是在1的基础上继续标记其他可达GC ROOT的对象,并且此时用户线程也是在运行的,可达对象可能会发生变化,故需要再进行标记。
3. 然后用户线程阻塞,进行并发线程标记,时间会比1和2快,标记后,进行垃圾回收完成后(图中没画出此阶段),用户线程进入运行状态。 这种机制减少了用户线程停顿的时间。
CMS 回收器:高并发、低停顿,追求最短GC回收停顿时间。适合重视服务响应速度的应用(如网站),和 Parallel Old的追求目标相反。基于标记-清除算法。
优点:并发收集、低停顿
缺点:产生大量空间碎片、并发阶段会降低吞吐量
G1
G1回收器是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。
与CMS收集器相比G1收集器有以下特点:
并行并发,充分利用硬件的多核硬件优势,大大缩短Stop-The-World时间,使得GC时,Java程序可以继续执行。
空间整合,G1收集器从整理看,是基于标记整理算法,从局部(两个Region)看,是基于复制算法,但无论如何,都不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
分代收集,上面提到的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合。
以上是关于用菜鸟的视角,去窥视JVM虚拟机的微观和宏观世界的主要内容,如果未能解决你的问题,请参考以下文章