JVM——四种垃圾收集算法详解
Posted 青城博雅教育科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM——四种垃圾收集算法详解相关的知识,希望对你有一定的参考价值。
之前几篇博客介绍了内存模型以及判断对象是否存活的两种算法,当一个对象死亡的时候,就要被当做垃圾回收。那么今天我们就来了解一下垃圾收集算法,看看都是怎么将这些死亡的对象给回收了去。
目前主要的垃圾收集算法有四种,分别是标记-清除算法、复制算法、标记整理算法以及分代收集算法。下面我们就来看看这四种算法都是啥。
1.标记-清除算法
标记-清除算法是最基础的收集算法。从它的名字我们可以看出来,这个算法分为“标记”和“清除”两个阶段。
首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。
之所以说它是最基础的算法,那是因为后面要介绍的几种算法都是基于这种算法的思路并对其不足进行改进而得到的。
那它有什么不足呢?它的主要不足有两个:
标记-清除算法的执行过程如下图所示:
一是效率问题,标记和清除两个过程的效率都不高;
二是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配大对象的时候,无法找到足够的连续内存而不得不提前触发下一次垃圾收集动作(这可划不来,毕竟垃圾收集的开销很大)。
从上图我们可以发现,通过标记-清除进行垃圾收集之后,会产生很多的零散的空间,这不利于很多后续操作。
而为了解决效率问题,“复制算法”腾空而出。
2.复制算法
复制算法是为了解决标记-清除算法的效率问题而出现的。
复制算法将可用内存按照容量划分为大小相等的两块,每一次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另一块内存上去,然后再把已经使用过的内存空间一次清理掉。
复制算法使得每次都是对整个半区进行内存回收,这样的话在内存分配时也就不必想标记-清除算法那样,考虑内存碎片等复杂情况啦。只要移动堆顶指针,按照顺序分配内存就能完事。
如图:

Survivor Space 是两块等大的内存空间。
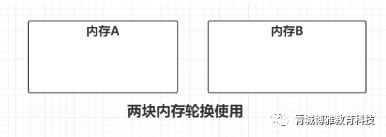
当使用内存A的时候,B不使用。当需要进行GC的时候,将内存A中仍然存活的对象复制到B中,然后再将A中的所有使用过的内存都回收。下一次则使用内存B,当要GC的时候,再将B中仍然存活的对象复制到A中,再将B中使用过的内存回收,不断轮换。
这种算法的实现简单,运行高效,但也有代价,它将内存缩小到原来的一半,这着实有些高了。
下面是复制算法的执行过程。
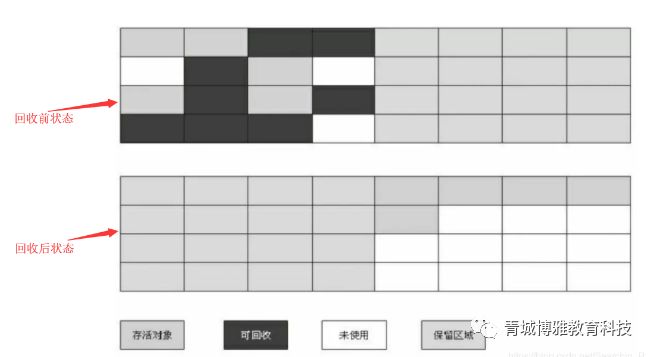
也许看图不太明白,那么再看两张图吧~
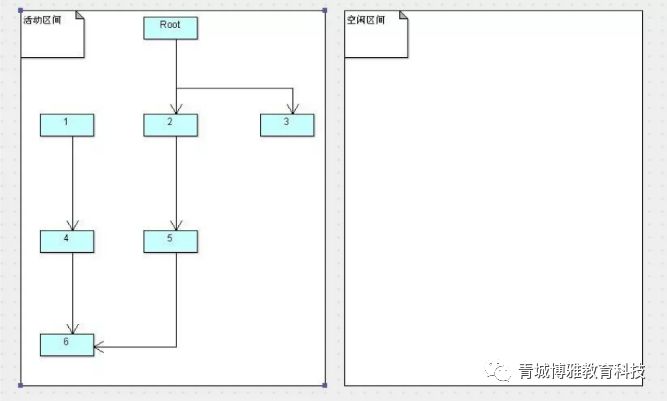
当复制算法的GC线程处理之后,两个区域会变成什么样子呢?如下所示。
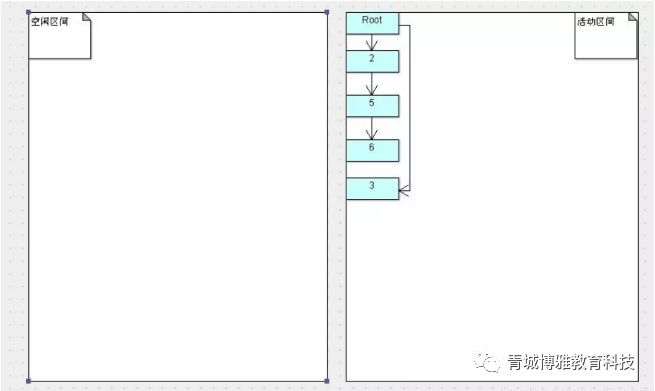
可以看到,1和4号对象被清除了,而2、3、5、6号对象则是规则的排列在刚才的空闲区间,也就是现在的活动区间之内。此时左半部分已经变成了空闲区间,不难想象,在下一次GC之后,左边将会再次变成活动区间。
很明显,复制算法弥补了标记/清除算法中,内存布局混乱的缺点。不过与此同时,它的缺点也是相当明显的。
上文说到,复制算法将内存分为两份,则每次可使用的内存只有原来的一半,这样不太好。所以现在大部分的商用虚拟机都采用这种收集算法来回收新生代。
由于新生代中的对象都是朝生夕死的(IBM公司的专门研究表明新生代中的对象98%都是“朝生夕死”的),所以并不需要按照1:1的比例来划分内存空间,而是江内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收的时候则将Eden和Survivor中还存活着的对象一次性地复制到另外一个Survivor空间上,最后再清理掉Eden和刚才用过的Survivor空间。
我们常用的HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是说,每次新生代中可用内存空间为整个新生代容量的90%(即80%+10%) ,只有10%的内存会被浪费。
当然啦,这只是针对大多数情况下的安排,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用的时候,需要依赖老年代进行分配担保。
什么叫分配担保呢?它就好比我们去银行借小钱钱,如果我们信誉很好,比如本帅博主这样的,那么在98%的情况下都能够按时偿还,所以银行可能会默认我们下一次也能够按时偿还贷款。但是这样的话银行要承受的风险还是很大,万一本帅博主哪一天携着巨款跑路呢?所以还需要一个担保人,当本帅博主不能够按时偿还贷款的时候,可以从他的账户里扣钱,那么这样的话银行就几乎没有风险啦。
内存的分配担保也是这个样子,如果另外一块Survivor空间没有足够空间存放上一次新生代收集下来的存活对象,那么这些对象将直接通过分配担保机制直接进入老年代。这个时候,就不关新生代的事了,而是需要老年代烦恼了。
但上文我们说到,复制算法是为了提升标记-清除算法效率才有的算法,在大部分情况下,复制算法适用于新生代的垃圾收集,但是当对象存活率比较高的时候它就需要进行很多的复制操作,这样一来效率也低了。
更关键的是,如果我们不想浪费50%的空间,就需要有额外的空间进行担保,以应对使用的内存中所有对象都100%存活的极端情况。
由此看来,复制算法不适合老年代。怎么办呢?还是用标记-整理算法吧。
3.标记-整理算法
对于老年代来说,它们的存活时间长,而且占据的内存常常较大,这样的该怎么办呢?
复制算法显然不适用于老年代的对象,难道用最基础的标记-清除算法咩?
我们知道,标记-清除算法会在垃圾回收之后留下很多碎片空间,而咱们老年代的对象往往占据的内存较大,如果用标记-清除算法的话恐怕会经常找不到足够大的连续内存空间,因此要提前触发下一次垃圾收集,这样的消耗显然太大。那怎么办呢?
根据老年代的特点,有人提出了“标记-整理”算法。
显然,“标记-整理”算法也是从“标记-清除”算法的基础上改进的,它们的标记过程一样,只是“标记-整理”算法的后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后再清理掉端边界以外的内存,即“先移动后清除”。
“标记-清除”算法的示意图如下:
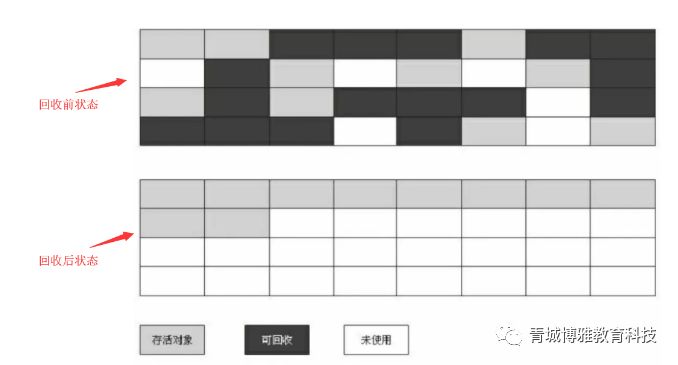
具体流程时什么样的呢?
GC前内存中对象的状态与布局,如下图所示。

标记阶段过后对象的状态,如下图。
我们来看当整理阶段处理完以后,内存的布局是如何的,如下图。
4.三种算法的异同点总结
共同点:
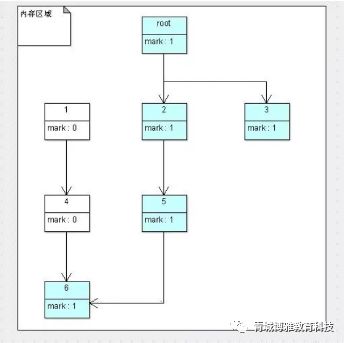
三个算法都基于根搜索算法去判断一个对象是否应该被回收,而支撑根搜索算法可以正常工作的理论依据,就是语法中变量作用域的相关内容。因此,要想防止内存泄露,最根本的办法就是掌握好变量作用域,而不应该使用前面内存管理杂谈一章中所提到的C/C++式内存管理方式。
在GC线程开启时,或者说GC过程开始时,它们都要暂停应用程序(stop the world)。
不同点:
效率不同:复制算法>标记-整理算法>标记-清除算法(此处的效率只是简单的对比时间复杂度,实际情况不一定如此)。
内存整齐度不同:复制算法=标记-整理算法>标记-清除算法。
内存利用率不同:标记/整理算法=标记-清除算法>复制算法。
看完这三种算法的异同点,我们会发现,它们似乎针对于不同的内存区域有着各自的强大力量。为了让垃圾收集得更好,分代收集算法就出来了。
5.分代收集算法
当前商业虚拟机的垃圾收集都采用的是“分代收集”算法。
这种算法其实并没有什么新的思想,它只不过是根据对象存活皱起的不同而将内存划分为了多个块。
一般是将Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
在新生代中,由于每次垃圾收集都发现有大量的对象死去,对象存活率很低,因此采用复制算法,这样只需要付出少量存活对象的复制成本就可以完成收集;而在老年代中,由于对象存活率很高,而且没有额外的空间对它们进行分配担保,因此必须使用“标记-清理”或者“标记-整理”算法来进行回收。(一般是用标记-整理算法。)
以上是关于JVM——四种垃圾收集算法详解的主要内容,如果未能解决你的问题,请参考以下文章