JVM的内存中的堆和栈有啥区别呢?
Posted 小张乱侃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM的内存中的堆和栈有啥区别呢?相关的知识,希望对你有一定的参考价值。
时间:2019-01-24 14:00:00
地点:成都某高校
人物:A(学霸A,连续五年拿下年级第一),B(学霸B,连续五年拿下年级第二,一直想超越A)
今天,在篮球场上,A和B相遇了,看起来,一场大战在所难免。
A:哦,这不是万年老二的B吗?好久不见呀。
B:哼,休得嚣张,我今天就是专门来考你的?
A:考我?来呀,我上知天文下知地理,能打架能泡妞,怕你?
B:好,我问你,Java中是怎么加载类的?
A:是通过ClassLoader来加载的,其中重点需要知道的就是四类ClassLoader的双亲委托机制,可以参考我的前一篇文章
B:嗯,那么当ClassLoader给加载到了Jvm中,是怎么分配内存的呢?
A:分配内存的操作也是由JVM来做的,他会把Class,Method等信息放在永久代中,对象实例放在内存堆中。
B:永久代(PermGen)?可是据我所知,现在已经没有永久代这个说法了。
A:这个我当然知道,在JDK1.7及以后JVM中的永久代就已经变成了元空间了(MetaSpace),元空间相对与JVM的区别主要是:
元空间是用的本地内存,永久代是用的JVM虚拟机内存,所以相对而言使用永久代更容易出现性能问题和内存泄漏。同时呢,元空间使用本地内存不用指定大小,而永久代需要指定大小,但是呢由于永久代里面存储都是类和方法这些信息,大小难以确定,所以指定永久代的大小也很复杂。
B:就没啦?
A:当然有,但是一直都是你来问我,我也想问问你,这样,你一个问题,我一个问题,行吧。
B:OK。
A:元空间相对永久代而言更利于GC回收,为什么?
B:因为在1.7及以后的元空间中把原本在永久代中常量池移到了堆中,GC在回收的时候不必考虑常量池的数据,当然更快了。
A:嗯,我继续。JVM的内存模型是怎么样的?
B:如下图:
B:我们从线程的角度来看可以JVM内存模型分为两个部分,线程私有的和线程公有的,我具体说说每一个:
程序计数器:
顾名思义就是用来计数的,每个线程都有自己的程序计数器,它指向当前执行的字节码的行号,所以也可以通过改变程序计数器来执行下一行字节码。但是值得注意的是,程序计数器只是针对于Java代码,当Java代码调用native方法即其他语言编写的类库的时候程序计数器为undefined。
另外,程序计数器占用的内存空间很小,不会发生内存泄漏。
JVM虚拟机栈:
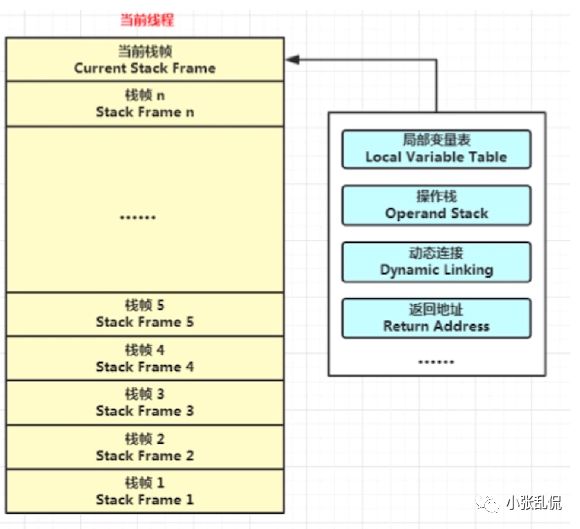
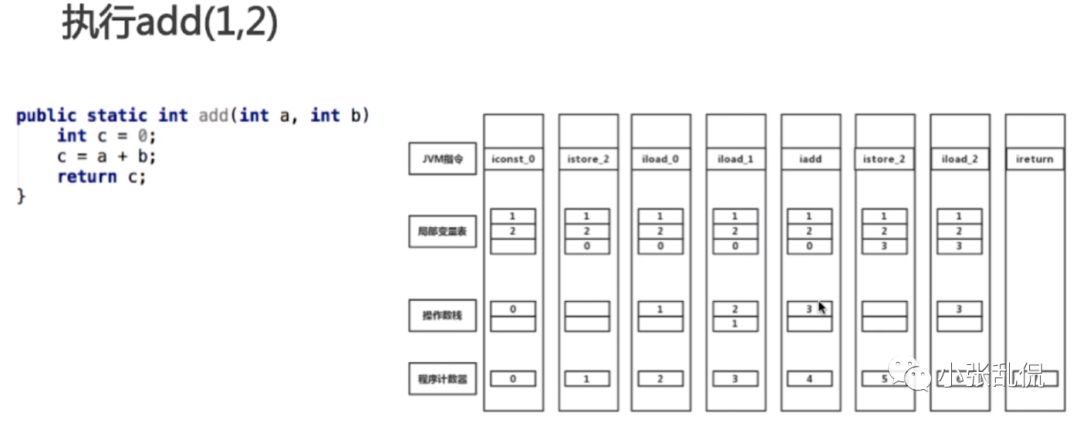
反编译左边代码可以看到调用iload等方法
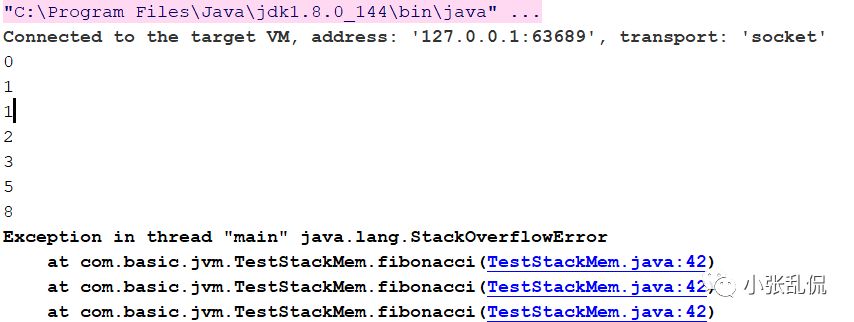
栈的内存空间相对堆而言很小,所以有时候可能会发生堆栈或者内存不够的异常:java.lang.StackOverflowError,java.lang.OutOfMemoryError
如下是我实现的费波纳茨函数,当递归层次过深的时候就会发生java.lang.StackOverflowError
private static void testStackOverflowError(){
// 实现一个费波纳茨函数
// 费波纳茨:1,1,2,3,5,8,13,21
System.out.println(fibonacci(0));;
System.out.println(fibonacci(1));;
System.out.println(fibonacci(2));;
System.out.println(fibonacci(3));;
System.out.println(fibonacci(4));;
System.out.println(fibonacci(5));;
System.out.println(fibonacci(6));;
System.out.println(fibonacci(100000));;
}
/**
* @Author: xingrui
* @Description: 费波纳茨函数
* @Date: 23:07 2019/1/23
*/
private static long fibonacci(int index){
if(index == 0)
return 0;
if(index == 1 || index == 2)
return 1;
return fibonacci(index - 1) + fibonacci(index - 2);
}
抛出的异常如下:
我们也可以让它抛出java.lang.OutOfMemoryError
private static void testOutOfMemoryError(){
while (true){
new Thread(){
public void run(){
while (true){
System.out.println("hello world");
}
}
}.start();
}
}
这个代码就不执行了,昨天执行了一下,电脑风扇一下就很大声了,赶紧把进程给结束了。
Java堆:
Java堆主要就是存储对象的实例了,它是JVM主要分配内存同时也是GC主要回收的区域。
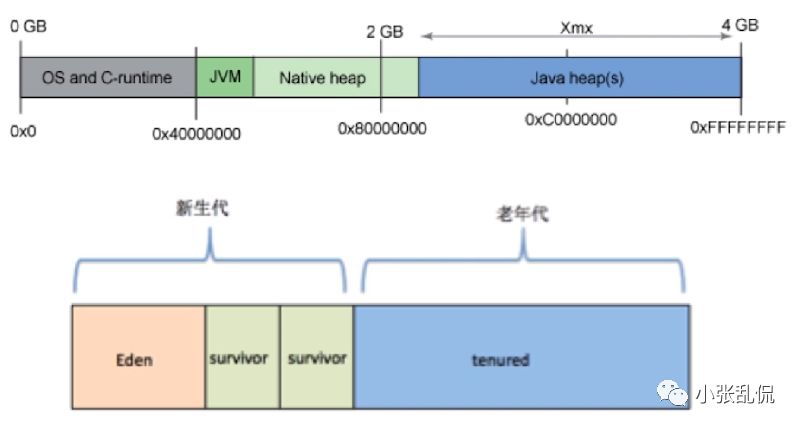
这里就可以说一下栈和堆的区别了:
栈的内存在方法执行完毕会自动释放(以为栈帧会出栈),而堆的内存要等到GC来回收,栈比堆小很多,但是效率要高很多,同时栈的内存在释放之后基本不会产生碎片。
另外之前你也说到在1.7以后把字符串常量池移到了堆中,那么如何得知呢?我写一下代码可以测试。
/**
* @Author: xingrui
* @Description: 测试1.7以后是否把字符串常量池放到了堆中
* @Date: 22:59 2019/1/23
*/
public static void main(String[] args) {
generateStr(100000000);
}
private static String generateStr(int len){
StringBuilder str = new StringBuilder();
for(int i = 0; i < len; ++i){
str.append("hello");
}
return str.toString();
}
上述代码会抛出如下异常:
可以看到该异常是在Java heap space中抛出的。
还有别的方法也可以佐证
/**
* @Author: xingrui
* @Description: 测试1.6以后的intern方法
* @Date: 22:58 2019/1/23
*/
public static void main(String[] args) {
// 会在堆中存储String对象,栈中存储对String对象的引用,字符串常量池中存储字符串
String s1 = new String("我爱祖国");
// 如果该字符串在字符串常量池中已经存在则返回,如果不存在则去看堆中有没有
// 如果堆中有则将此对象的引用添加到字符串常量池中,如果还是没有,
// 则在字符串常量池中添加该字符串并返回
s1.intern();
String s2 = "我爱祖国";
// s1指向堆中地址,s2指向字符串常量池中地址
System.out.println(s1 == s2);
String s3 = new String("我爱祖国") + new String("我爱祖国");
// 由于字符串常量池中没有 "我爱祖国我爱祖国" 这个字符串,则去堆中找,
// 堆中刚好有这个对象,则将对象的引用添加到字符串常量池中。
// 此时 s3 == s4,都是指向堆中的内存地址。
s3.intern();
String s4 = "我爱祖国我爱祖国";
System.out.println(s3 == s4);
}
就是字符串的intern方法的原理不同了:
以上是关于JVM的内存中的堆和栈有啥区别呢?的主要内容,如果未能解决你的问题,请参考以下文章