8.JVM系列-零拷贝
Posted 爱吃糖果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了8.JVM系列-零拷贝相关的知识,希望对你有一定的参考价值。
目录
一、背景
二、零拷贝的概念
三、Linux IO过程
四、零拷贝在mq中的应用
五、零拷贝在netty中的应用
一、背景
早些时间看netty了解一点点零拷贝,但是并没有深入的理解,现在想深入的了解,查了一些网络资料和书籍,发现全都是互相转来转去,没有一篇是我想要的答案,最后花了一些时间从基础做起,从操作系统io基础,再回应用层去理解才对所谓的零拷贝有一点点了解。
抽时间重新整理了下。
二、零拷贝的概念
零拷贝顾名思义就是不需要copy,但是继续追问下去,到底是从哪里到哪里不需要copy?难道应用读取文件就真的0次copy吗?
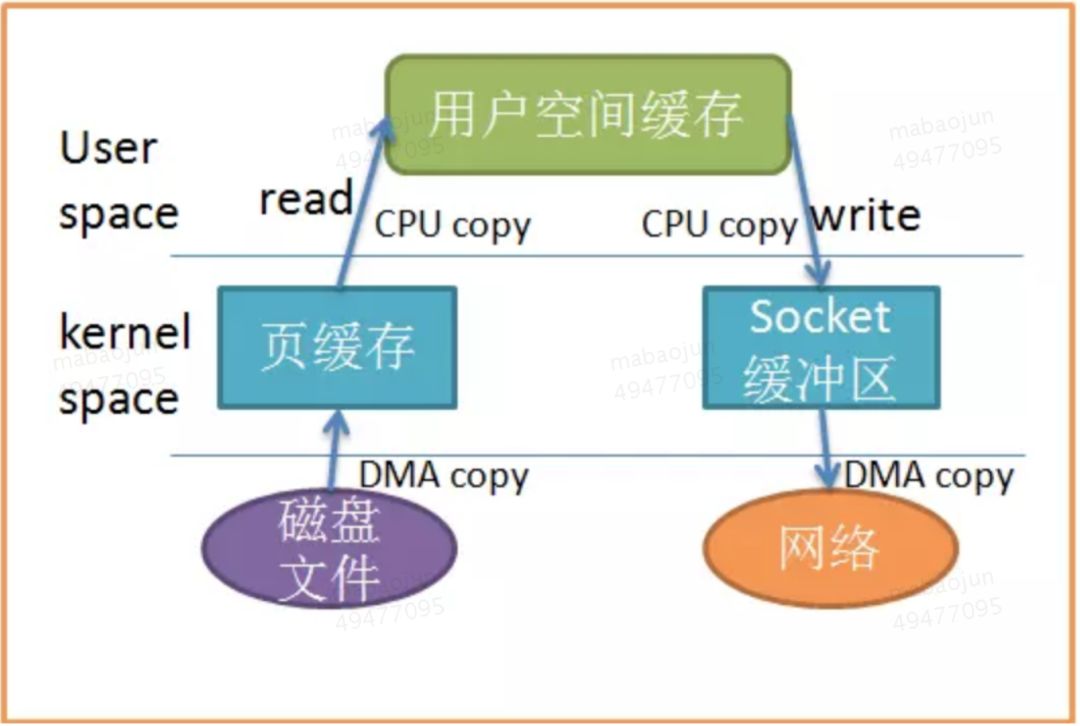
首先要明确一点,所谓的零拷贝是指,从网络/硬件设备->用户空间,需要cpu copy的次数为0,这种场景叫做零拷贝。注意用户空间内部的copy次数不包括在这里面。
而为什么从cpu copy的次数是0呢到底是怎么传输的?非零拷贝的cpu次数是多少?是怎么传输的?
要知道这些需要先了解Linux IO的过程。
三、Linux IO过程
先来看下Linux3种IO整体概况。
概念:
1>.Buffered IO(缓存IO也叫标准IO):
如上图,buffered IO以一次read系统调用为例,到达File System->Page Cache发现不存在,则继续请求到达BLOCK IO LAYER(设备块),在IO队列中排队(此处会排序合并请求),继续使用DMA的方式读取对应的磁盘扇区到Page Cache(), 因为Page Cache是内核态空间,还需要使用cpu copy到用户态空间,这时候用户程序就可以访问数据了。
注意DMA的方式读取对应的磁盘扇区到Page Cache,此处不需要CPU参与,内存之间的copy是需要CPU参与的。
次时,当前进程或者其他进程访问此数据,就可以在Page Cache命中直接返回了。 对于大部分文件系统都默认采用此种方式读文件。
同理对于写操作,会先写进Page Cache,数据是否立即写进磁盘取决于应用程序的写的方式,,如java调flush()则会强制写到磁盘,而默认是写进Page Cache则返回,OS异步定时刷进磁盘。
可以看出,buffered IO的优点是第一次缓存之后,后面读写会更高效,但是有时候我们并不需要缓存,或者在自己在应用层缓存比如数据库,这时候就很明显不希望OS再缓存一次,所以OS也提供了一种机制不缓存也就是Direct IO。
2>.Direct IO :
简而言之 Direct IO就是不使用内核缓存(Page Cache) ,以一次read系统调用为例,请求到达BLOCK IO LAYER(设备块),在IO队列中排队(此处会排序合并请求),继续使用DMA的方式读取对应的磁盘扇区到用户空间内存。可以看出这种方式省去了到Page Cache的一次copy。
在Linux中,在使用open()传入标识O_DIRECT则OS不会缓存,采用Direct IO的方式。
3>. mmap内存映射:
mmap的出现主要是考虑到从page cache到用户态的copy需要耗费cpu,所以为了避免此,想到用户态直接读写page cache的一种方式。
以一次read系统调用为例,请求到page cache其他同上,不同在于,不需要再从page cache copy到用户空间。
注意mmap一定要使用缓存机制,即使在使用open()传入标识O_DIRECT。
而对于网络IO原理同文件IO,如下图。
四、零拷贝在mq中的应用
通过上面了解了Linux io的过程对于一些特定的场景,就可以避免从用户态到内核态之间从copy,因为涉及到切换和耗费cpu。
注意对于一般场景是不存在零拷贝的,只有特定的场景。
如以下场景:
我们知道mq服务端,收到消息写进文件,而发送消息给关注者时,需要读取文件然后发送到网络上。
对于上面的场景,也就是读取文件发送到网络,或者反过亦可。因为读文件需要到磁盘->内核缓存->用户内存 写网络则用户内存->内核缓存->网络,所以人们想到是不是可以从磁盘读到内核之后直接发出去,而不要再copy到用户空间省去两次cpu介入的copy。
最终流程为:磁盘->DMA到内核缓存->DMA到网络,发现一次cpu介入的copy都没有,也不需要到用户态的切换。
上面这种方式就是所谓的零拷贝的一种实现。在kafka中使用此方式,因为rocketmq是参考了kafka的实现,rocketmq也采用了此方式。
五、零拷贝在netty中的应用
传统的IO流程如下:
用户数据->内核socket缓存区->DMA到网络
Netty中可以直接申请直接内存如下:
直接内存->DMA到网络
看上去netty这种方式的确是少了一次copy,我们先来看一段代码:
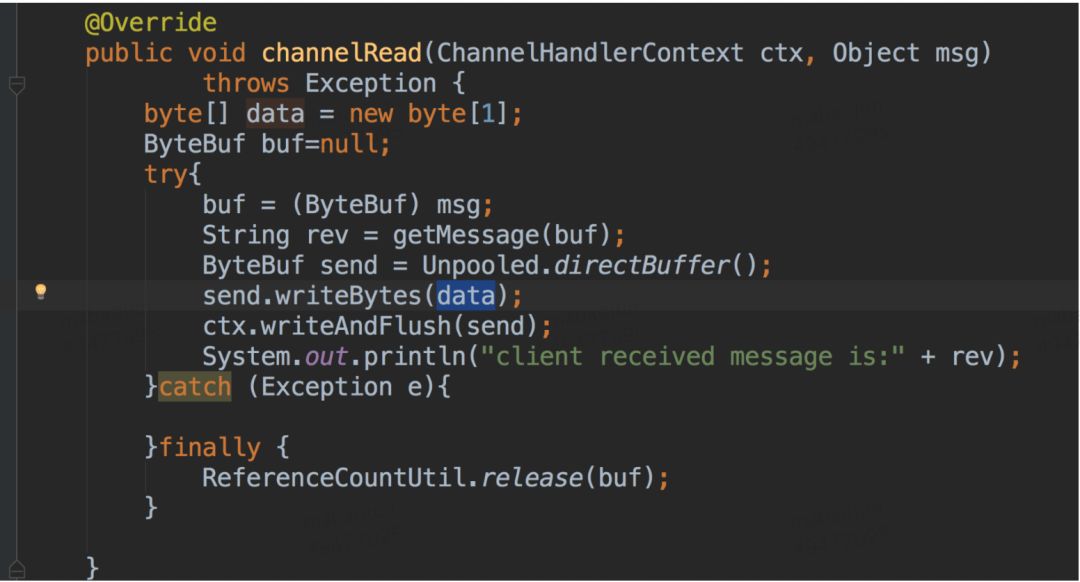
send.writBytes()底层实现,可以看出会copy到直接内存。
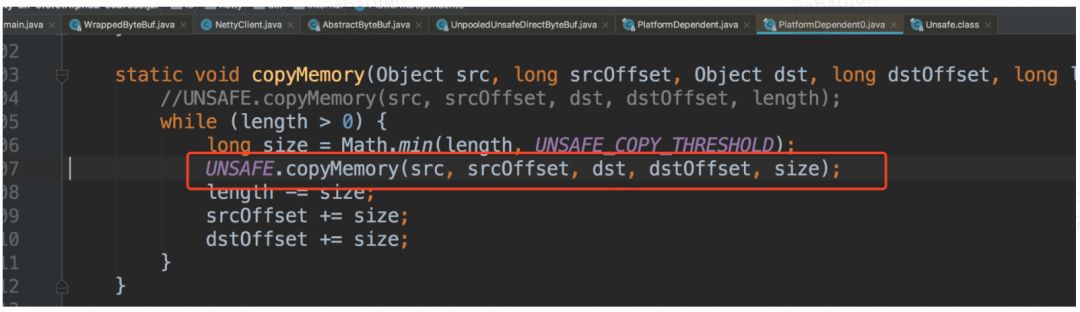
上面是一次普通的网络请求,事实上上面的流程并没有减少copy,虽然send是直接内存直接发送到网络上,没有发生cpu介入的copy。但是send对象的数据来自一个byte数组,而这个byte数组是在堆内存中,netty会主动将此byte数组copy到send所在的直接内存。也就是说并没有减少copy的次数。普通的网络请求无论使用堆内存还是使用直接内存都需要发生一次CPU的copy。
注意这里申请的直接内存还是属于用户空间。
而对于一些特定的场景,注意的特定的场景,使用直接内存的确是零拷贝。原理同上,就是接受到的数据,转发给其他系统。对于这种场景会提升不少效率,
先看代码:
可以看到接收到的msg直接转发出去就省去了堆空间的考近考出,也就是省去了2次copy,实现了零拷贝。
最后我一直被下面这句话摘自李林峰的一本书上困扰好久,如果是使用常规的网络请求无论是使用堆内存还是直接内存copy的次数是一样多,并没有减少,只有在上面说的特定场景下才会减少,所以这句话我认为说的是有问题的,容易误导人。
以上是关于8.JVM系列-零拷贝的主要内容,如果未能解决你的问题,请参考以下文章
#私藏项目实操分享# Java深层系列「技术盲区」让我们一起探索一下Netty(Java)底层的“零拷贝Zero-Copy”技术(上)