深入理解jvm虚拟机一
Posted Android开发大杂烩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入理解jvm虚拟机一相关的知识,希望对你有一定的参考价值。
(深入理解jvm虚拟机一)
JVM
Java与Jvm的关系似鱼和水,而开发者与Jvm的关系似情侣相爱相杀。爱它不用像C、C++摆弄指针,把内存控制的权利交给它,恨它一旦出现内存泄漏和溢出方面的问题,如果不理解它的话,无从下手,更别谈优化了。
Jvm基本概念
JVM及Java虚拟机,是可运行Java代码的假象计算机,Jvm是运行在操作系统之上的,它与硬件没有直接交互。
运行过程
我们都知道Java源文件,通过编译器,能够生成相应的.class文件,也就是字节码文件,而字节码文件又能通过jvm的解释器,编译成机器上的机器码,大概流程如下:Java源文件—>编译器—>字节码文件—>jvm—>机器码,虽然每个平台的解释器不同,但是虚拟机是相同的,这也就是为什么java是跨平台的。
内存区域
Jvm把Java程序运行时的内存划分为不同的数据区域,如图所示: jvm内存区域主要分为线程私有(程序计数器、虚拟机栈、本地方法栈)、线程共享(堆、方法区)、直接内存,线程私有的生命周期与线程相同,依赖用户线程的启动/结束而创建/销毁,线程共享随虚拟机开启/关闭而创建/销毁。直接内存并不是jvm运行时数据区的一部分,在 JDK 1.4 引入的 NIO 提供了基于 Channel 与 Buffer 的 IO 方式, 它可以使用 Native 函数库直接分配堆外内存,然后使用DirectByteBuffer 对象作为这块内存的引用进行操作,这样就避免了在 Java堆和 Native 堆中来回复制数据,因此在一些场景中可以显著提高性能。
程序计数器
一块较小的内存空间,是当前线程所执行到的字节码的行号指令器,每个线程都是独立运行的,如果正在执行的是Java方法,则记录的是正在执行的虚拟机字节码行号,如果是native方法,则为空,此区域也是唯一一个在虚拟机中没有规定任何 OOM 情况的区域。
虚拟机栈
生命周期与线程相同,是描述Java方法执行的内存模型,每个方法在执行的时候都会创建一个栈针,用于存放局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行结束对应栈针在虚拟机中的入栈和出栈。如果虚拟机栈请求栈深度大于虚拟机所允许的深度,将抛出StrakOverflowError异常;如果扩展时无法申请到足够的内存,将抛出OOM异常,可以通过xss参数来调节大小,默认1M。
本地方法栈
与虚拟机中作用相似,区别是虚拟机栈为Java方法服务的,而本地方法栈是为native服务的,它也会抛出同虚拟机栈一样的异常。
堆
是用来存放被创建的对象、数组,也是垃圾回收器进行垃圾回收的主要内存区域,可以通过xms、xmx来设置初始化堆大小、最大堆大小,默认是最小1/64,最大1/4。由于现代的垃圾回收器都是采用分代回收,因此堆从GC的角度还可以细分为:新生代(Eden区、From Survivor区、To Survivor区)和老年代。
方法区/永久代
用来存放被Jvm加载的类信息、常量、静态变量、即时编译器编译后的代码数据,HotSpot VM把GC分代收集扩展至方法区, 即使用Java堆的永久代来实现方法区, 这样 HotSpot 的垃圾收集器就可以像管理 Java 堆一样管理这部分内存,而不必为方法区开发专门的内存管理器(永久带的内存回收的主要目标是针对常量池的回收和类型的卸载,因此收益一般很小),通过设置PermSize和MaxPermSize设置初始化和最大上限(1.7以前)。
1.8元数据区
在Jdk1.8取消了永久代,不在使用虚拟机内的永久代而是改用本地内存——元数据区(Metaspace),通过MetaspaceSize和MaxMetaspaceSize来设置初始化和最大上限。至于为什么不使用,理由如下: 1. 永久代调优很难,会为 GC 带来不必要的复杂度,并且回收效率偏低。2. 字符串存在永久代中,容易出现性能问题和内存溢出。3. 类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。4. Oracle 可能会将HotSpot 与 JRockit 合二为一。
回收与收集
两大回收
在堆里几乎存放了所有的实例,垃圾回收前,需要判断哪些对象“活着”,哪些对象“死去”。
引用计数法
在java中引用和对象是有关联的,如果操作对象就必须用引用来进行。因此通过引用计数法来判断一个对象是否可以被回收,被引用则计数器+1,引用失效则计数器-1,直到引用计数为0,这是基本的也是比较高效的,但是无法避免相互引用。
可达性分析
为了避免相互引用问题,Java使用的可达性分析的方法,通过“GC roots”对象作为起点搜索,如果没有可达路径,则该对象不可达,可以被回收。即使这样,也不是说必须回收,如果该对象覆盖了finalize()方法,重新引用对象可以进行自救,只会自救一次。因为这个方法对运行代价高,不稳定性,因此也不推荐使用。在Java中GC roots对象包括下面四种: 1. 虚拟机栈(栈针中变量表)引用的对象 2. 本地方法栈(JNI)引用的对象 3. 方法区中类静态属性引用的对象 4. 方法区中常量引用的对象
四大引用
无论是引用计数法还是可达性分析,都与Java中引用有关。
强引用
Java中常见的引用,Object obj=new Object,即使虚拟机抛出OOM(内存溢出)也不会释放这部分引用,这部分容易造成内存泄漏。
软引用
需要用SoftReference类实现,描述一些还有用但非必需的对象,当系统内存足够时,是不会回收这部分资源,只有在系统内存不够时,这部分则会被回收。
弱引用
需要用WeakReference类实现,它比软引用存活时间更短,它的生命周期只存活在下一次垃圾回收之前。
虚引用
需要 PhantomReference 类来实现,随时被回收,它不能单独使用,必须和引用队列联合使用,虚引用的主要作用是跟踪对象被垃圾回收的状态。
回收算法
标记-清除(Mark-Sweep)
最基本的垃圾回收算法,分为两个阶段:标记、清除。标记可以被回收的对象,清除所有被标记的对象。缺点:空间碎片化严重,标记清除,效率都不高。 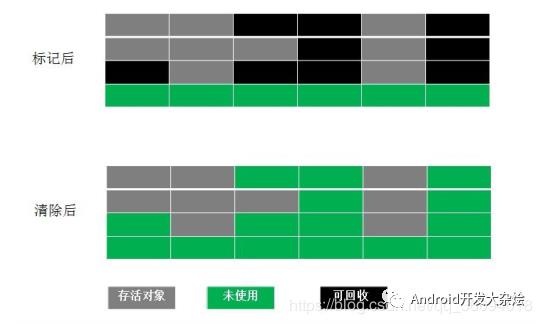
复制(Copying)
为了解决碎片化问题,按内存容量一分为二,每次只用其中的一块,当一块存满时候,把存活的对象复制到另外一块上,把已使用的内存块清除。缺点:内存使用率低。 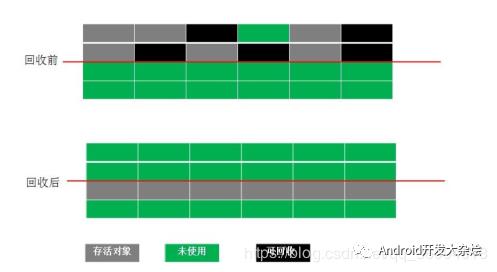
标记-整理(Mark-Compact)
结合以上两个算法,标记类似于Mark-Sweep,标记后不是清理对象,而是把存活的对象移向内存的一端,把端以外的对象清除。
分代算法
分代算法是目前大多数JVM使用的回收算法,根据对象存活的不同生命周期来划分内存区域,一般化为老年代和新生代,老年代特点每次垃圾回收只有少量对象被回收,新生代特点每次垃圾回收都会有大量对象被回收,这样就可以根据不同区域来选择不同的回收算法。
新生代
目前大多数JVM新生代都是采用复制算法,因为新生代需要回收大部分对象,并不是按照1:1来划分新生代,而是划分为一块较大的Eden空间和两个较小的Survivor空间(from ,to),每次都使用Eden和一部分Survivor区域,当进行回收时,把存活的对象复制到另一块Survivor空间,通过xmn调整新生代大小。 对象优先分配在新生代,大对象直接则进入老年代(设置-xx:PretenureSizeThreshold参数),长期存活的对象进入老年代(设置-xx:MaxTenuringThreshold,默认15次),为了更加适应程序的内存状态,并不是要求年龄必须到15才会进入老年代,如果在Survivor空间中所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象也可以直接进入老年代。
老年代
老年代存放生命周期比较长的,对象相对稳定,所以采用标记清除或者整理。 Minor GC:当新生代内存不足,回收新生代(Ende区和两个Survivor)内存。Major GC:清理老年代,一般伴随着一次Minor,效率比Minor要慢。Full GC:清理整个堆空间,一般调优也就是堆fullGC进行优化,因为它会停止操作,单一线程进行GC。
以上是关于深入理解jvm虚拟机一的主要内容,如果未能解决你的问题,请参考以下文章