Java面试- JVM 内存模型讲解
Posted 健程之道
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java面试- JVM 内存模型讲解相关的知识,希望对你有一定的参考价值。
经常有人会有这么一个疑惑,难道 Java 开发就一定要懂得 JVM 的原理吗?我不懂 JVM ,但我照样可以开发。确实,但如果懂得了 JVM ,可以让你在技术的这条路上走的更远一些。
JVM 的重要性
首先你应该知道,运行一个 Java 应用程序,我们必须要先安装 JDK 或者 JRE 。这是因为 Java 应用在编译后会变成字节码,然后通过字节码运行在 JVM 中,而 JVM 是 JRE 的核心组成部分。
优点
JVM 不仅承担了 Java 字节码的分析(JIT compiler)和执行(Runtime),同时也内置了自动内存分配管理机制。这个机制可以大大降低手动分配回收机制可能带来的内存泄露和内存溢出风险,使 Java 开发人员不需要关注每个对象的内存分配以及回收,从而更专注于业务本身。
缺点
这个机制在提升 Java 开发效率的同时,也容易使 Java 开发人员过度依赖于自动化,弱化对内存的管理能力,这样系统就很容易发生 JVM 的堆内存异常、垃圾回收(GC)的不合适以及 GC 次数过于频繁等问题,这些都将直接影响到应用服务的性能。
内存模型
JVM 内存模型共分为5个区:堆(Heap)、方法区(Method Area)、程序计数器(Program Counter Register)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack)。
其中,堆(Heap)、方法区(Method Area)为线程共享,程序计数器(Program Counter Register)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack)为线程隔离。
堆(Heap)
堆是 JVM 内存中最大的一块内存空间,该内存被所有线程共享,几乎所有对象和数组都被分配到了堆内存中。
堆被划分为新生代和老年代,新生代又被进一步划分为 Eden 区和 Survivor 区,最后 Survivor 由 From Survivor 和 To Survivor 组成。
随着 Java 版本的更新,其内容又有了一些新的变化:
在 Java6 版本中,永久代在非堆内存区;到了 Java7 版本,永久代的静态变量和运行时常量池被合并到了堆中;而到了 Java8,永久代被
元空间(处于本地内存)取代了。
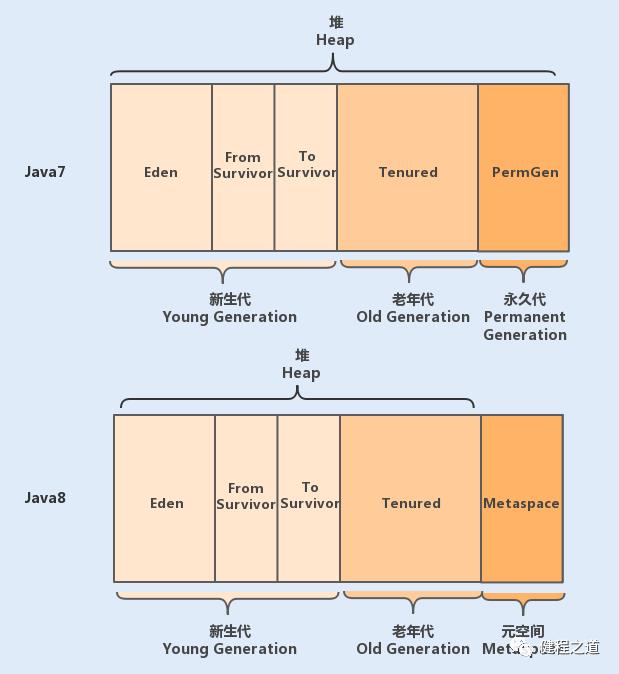
为什么要用元空间替换永久代呢?
为了融合 HotSpot JVM 与 JRockit VM,因为 JRockit 没有永久代,所以不需要配置永久代。
永久代内存经常不够用或发生内存溢出(应该是 JVM 中占用内存最大的一块),产生异常
java.lang.OutOfMemoryError: PermGen。在 JDK1.7 版本中,指定的 PermGen 区大小为 8M,由于 PermGen 中类的元数据信息在每次 FullGC 的时候都可能被收集,回收率都偏低,成绩很难令人满意;还有,为 PermGen 分配多大的空间很难确定,PermSize 的大小依赖于很多因素,比如,JVM 加载的 class 总数、常量池的大小和方法的大小等。
看到这儿,自然就想到了 GC 回收算法,不用急,我会在之后的文章中进行讲解,现在还是以 JVM 内存模型为主。
方法区(Method Area)
什么是方法区?
方法区主要是用来存放已被虚拟机加载的类相关信息,包括
类信息、常量池(字符串常量池以及所有基本类型都有其相应的常量池)、运行时常量池。这其中,类信息又包括了类的版本、字段、方法、接口和父类等信息。
类信息
JVM 在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。
在加载类的时候,JVM 会先加载 class 文件,而在 class 文件中便有类的版本、字段、方法和接口等描述信息,这就是类信息。
常量池
在 class 文件中,除了类信息,还有一项信息是常量池 (Constant Pool Table),用于存放编译期间生成的各种字面量和符号引用。
那字面量和符号引用又是什么呢?
字面量包括字符串(String a=“b”)、基本类型的常量(final 修饰的变量),符号引用则包括类和方法的全限定名(例如 String 这个类,它的全限定名就是 Java/lang/String)、字段的名称和描述符以及方法的名称和描述符。
运行时常量池
当类加载到内存后,JVM 就会将 class 文件常量池中的内容存放到运行时常量池中;在解析阶段,JVM 会把符号引用替换为直接引用(对象的索引值)。
例如:
类中的一个字符串常量在 class 文件中时,存放在 class 文件常量池中的。
在 JVM 加载完类之后,JVM 会将这个
字符串常量放到运行时常量池中,并在解析阶段,指定该字符串对象的索引值。
运行时常量池是全局共享的,多个类共用一个运行时常量池,因此,class 文件中常量池多个相同的字符串在运行时常量池只会存在一份。
讲到这里,大家是不是有些头晕了,说实话,我在看到这些内容的时候,也是云里雾里的,这里举个例子帮助大家理解:
public static void main(String[] args) {
String str = "Hello";
System.out.println((str == ("Hel" + "lo")));
String loStr = "lo";
System.out.println((str == ("Hel" + loStr)));
System.out.println(str == ("Hel" + loStr).intern());
}
其运行结果为:
true
false
true
第一个为 true,是因为在编译成 class 文件时,能够识别为同一字符串的, JVM 会将其自动优化成字符串常量,引用自同一 String 对象。
最后一个为 true,是因为 String 的 intern() 方法会查找在常量池中是否存在一个相等(调用 equals() 方法结果相等)的字符串,如果有则返回该字符串的引用,如果没有则添加自己的字符串进入常量池。
涉及到的Error
OutOfMemoryError出现在方法区无法满足内存分配需求的时候,比如一直往常量池中加入数据,运行时常量池就会溢出,从而报错。
程序计数器(Program Counter Register)
由于 Java 是多线程语言,当执行的线程数量超过 CPU 数量时,线程之间会根据时间片轮询争夺 CPU 资源。如果一个线程的时间片用完了,或者是其它原因导致这个线程的 CPU 资源被提前抢夺,那么这个退出的线程就需要单独的一个程序计数器,来记录下一条运行的指令。
由此可见,程序计数器和上下文切换有关。
虚拟机栈(VM Stack)
虚拟机栈是线程私有的内存空间,它和 Java 线程一起创建。
每一个方法的调用都伴随着栈帧的入栈操作,方法的返回则是栈帧的出栈操作。
可以这么理解,虚拟机栈针对当前 Java 应用中所有线程,都有一个其相应的线程栈,每一个线程栈都互相独立、互不影响,里面存储了该线程中独有的信息。
涉及到的Error
StackOverflowError出现在栈内存设置成固定值的时候,当程序执行需要的栈内存超过设定的固定值时会抛出这个错误。OutOfMemoryError出现在栈内存设置成动态增长的时候,当JVM尝试申请的内存大小超过了其可用内存时会抛出这个错误。
本地方法栈(Native Method Stack)
本地方法栈跟虚拟机栈的功能类似,虚拟机栈用于管理 Java 方法的调用,而本地方法栈则用于管理本地方法的调用。
但本地方法并不是用 Java 实现的,而是由 C 语言实现的。
也就是说,本地方法栈中并没有我们写的代码逻辑,其由native修饰,由 C 语言实现。
总结
以上就是 JVM 内存模型的基本介绍,大致了解了一下5个分区及其相应的含义和功能,由此可以继续延伸出 Java 内存模型、 GC 算法等等,我也会在之后的文章中进行讲解。如果你有什么想法,欢迎在下方留言。
https://death00.github.io/
以上是关于Java面试- JVM 内存模型讲解的主要内容,如果未能解决你的问题,请参考以下文章