细说JVM内存模型
Posted 技术和人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了细说JVM内存模型相关的知识,希望对你有一定的参考价值。
前言
在正式学习 JVM 内存模型之前,先注意以下几个是问题:
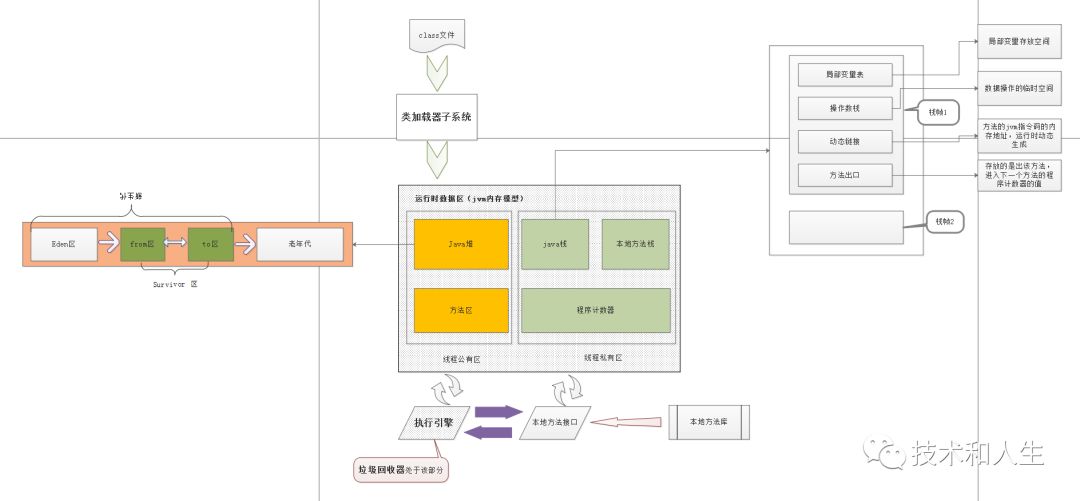
JVM 内存模型与 JAVA 内存模型不是同一个概念。JVM 内存模型是从运行时数据区的结构的角度描述的概念;而 JAVA 内存模型是从主内存和线程私有内存角度的描述。从以下两张图可以看出:
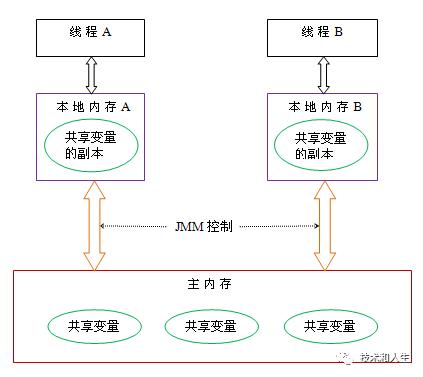
java内存模型
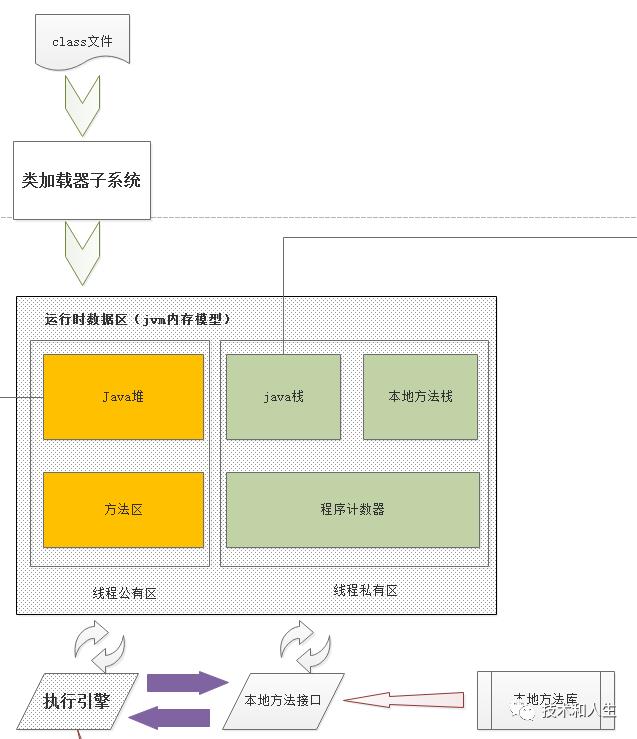
Java虚拟机总共由三大模块组成:
本篇我们介绍第二大模块——运行时数据区(JVM内存模型)。
类加载器子系统
运行时数据区执行引擎
其实虚拟机的这些模块并不是独立的,都是相互联系的。java 文件编译为 class 文件,通过类加载子系统加载,信息再到 JVM 托管的内存中(部分操作会与本地内存交互)的流转,再到垃圾回收等等,都是一系列的操作。
本系列的博客为了更加清晰的描述清楚功能和原理,将其分为几个章节写作。
概览
运行时数据区分为几大模块(如上图所示):
线程共享区:
JAVA堆
方法区
线程私有区:
JAVA栈
本地方法栈
程序计数器
本文中,我们将从以下几个方法面来分析各个区域:
功能
存储的内容
是否有内存溢出和内存泄露
是否进行垃圾回收
对应的垃圾回收算法
垃圾回收流程
性能调优
线程私有区
程序计数器
程序计数器是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过该计数器的值来选择选取下一条需要执行的字节码的指令,分支、循环、跳转、异常处理、线程恢复都需要依赖该区域。
当执行完一行指令码,JVM执行引擎会更新程序计数器的值。
由于Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。(方法的调用,方法中又调用另调用另外一个方法,正式满足栈的“先进先出,后进后出”的模型)。
OutOfMemoryError:无
虚拟机栈
它描述的是java方法执行的内存模型,其生命周期与线程相同。
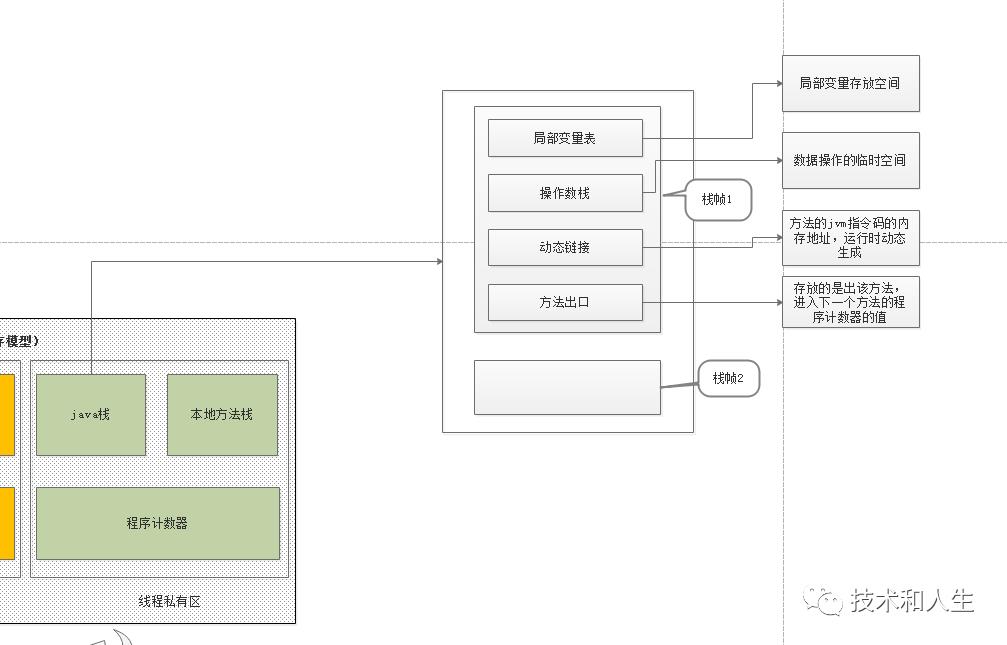
每个方法在执行的同时都会创建一个栈帧(StackFrame),每一个栈帧又包括局部变量表、操作数栈、动态链接、方法出口等。方法的调用,方法中又调用另外一个方法,正式满足栈的“先进先出,后进后出”的模型。即每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
以上都只是几个很机械的概念,难以深入理解。下面我通过一个示例,来分析虚拟机栈的存储内容。
首先创建一个简单的程序:
package com.sunwin.robotcloud.test;
/**
* Created by 追梦1819 on 2019-11-01.
*/
public class CalculateMain {
public int calculate(){
int a = 3;
int b=4;
int c = a+b;
return c;
}
public static void main(String[] args) {
CalculateMain main = new CalculateMain();
int d = main.calculate();
System.out.println(d);
}
}
对于以上程序,线程启动时,虚拟机会给主线程 main 分配一个大的内存空间,然后给main方法分配一个栈帧,存放该方法的局部变量;执行calculate()方法时又分配一个calculate()的栈帧,存放对应方法的局部变量。
要注意的是,一个方法分配一个单独的内存区域,即栈帧。
Java 属于高级语言,难以直接通过代码看出它的执行过程。我们通过底层的字节码,反解析出执行的指令码,来分析底层执行过程。
进入 CalculateMain.class 文件目录,执行命令:
将指令码直接输出到文件 CalculateMain.txt:
Compiled from "CalculateMain.java"
public class com.sunwin.robotcloud.test.CalculateMain {
public com.sunwin.robotcloud.test.CalculateMain();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int calculate();
Code:
0: iconst_3
1: istore_1
2: iconst_4
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: istore_3
8: iload_3
9: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class com/sunwin/robotcloud/test/CalculateMain
3: dup
4: invokespecial #3 // Method "<init>":()V
7: astore_1
8: aload_1
9: invokevirtual #4 // Method calculate:()I
12: istore_2
13: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream;
16: iload_2
17: invokevirtual #6 // Method java/io/PrintStream.println:(I)V
20: return
}
先看看calculate()方法,根据以上指令,查询JVM指令手册,可以得到以上程序的执行流程:
0.将int类型常量3压入(操作数)栈;
1.将int类型值3存入局部变量1(1是数组下标),也就是在局部变量表中给a分配一块内存(用以存储3);
2.将int类型常量4压入(操作数)栈;
3.将int类型值4存入局部变量2;
4.从局部变量1中装载int类型值,也就是将局部变量表的值3,拿出来加载到操作数栈;
5.从局部变量2中装载int类型值;
6.两值相加;
7.(将数存入到操作数栈?)将int类型值7存入局部变量3;
8.从局部变量3中装载int类型值;
9.返回计算值。
以上是方法执行时的局部变量在内存中的流转过程。总结就是:操作数栈相当于数据在操作时的临时中转站。
局部变量表:局部变量存放空间。是一个字长为单位、从0开始计数的数组。类型为int、float、reference、retrueAddress的值,只占据一项。类型为byte、short、char的值存入数组前都被转化为int值。类型为long、double的值在其中占据连续的两项。索引指向第一个值即可。不过需要注意的是,虚拟机对byte、short、char是直接支持的,只不过在局部变量表和操作数栈中是被转化为了int值,在堆和方法区中,依然是原来的类型。
操作数栈:数据操作的临时空间。与局部变量表类似。唯一不同的是,它并非是通过索引来访问的,而是通过压栈和出栈来访问的。
方法出口:存放的是出该方法,进入下一个方法的程序计数器的值。
异常情况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError 异常;如果虚拟机栈可以动态扩展(当前大部分的Java 虚拟机都可动态扩展,只不过Java 虚拟机规范中也允许固定长度的虚拟机栈),当扩展时无法申请到足够的内存时会抛出OutOfMemoryError 异常。
本地方法栈
本地方法栈其实与java虚拟机栈极其相似。唯一的区别就是java虚拟机栈是为java方法服务,本地方法栈是为本地方法服务,虚拟机规范中对本地方法栈中的方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。
也会抛出StackOverflowError和OutOfMemoryError异常。
线程共享区
方法区
该区域是存储虚拟机加载的类信息(字段方法的字节码、部分方法的构造器)、常量、静态变量、编译后的代码信息等,类的所有字段和方法字节码。以及一些特殊方法如构造函数,接口的代码也在此定义。简而言之,所有定义的方法的信息都保存在该区域。静态变量+常量+类信息(构造方法/接口定义)+运行时常量池都存在。
可不连续,可固定大小,可扩展,也可不选择垃圾回收器。垃圾回收存在在该区域,但是出现较少。
方法区是一种定义,概念,而永久代或者元空间是一种实现机制。
OutOfMemoryError:有
运行时常量池
Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
OutOfMemoryError:有
JAVA堆
堆是Java虚拟机所管理的内存中最大的一块,它唯一的功能就是存储对象实例。几乎所有的对象(包含常量池),都会在堆上分配内存。
如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError 异常。
垃圾回收器的主要管理区域。
该区域,从垃圾回收的角度看,又分为新生代和老年代,新生代又分为 伊甸区(Eden space)和幸存者区(Survivor pace) ,Survivor 区又分为Survivor From 区和 Survivor To 区。如下图所示:
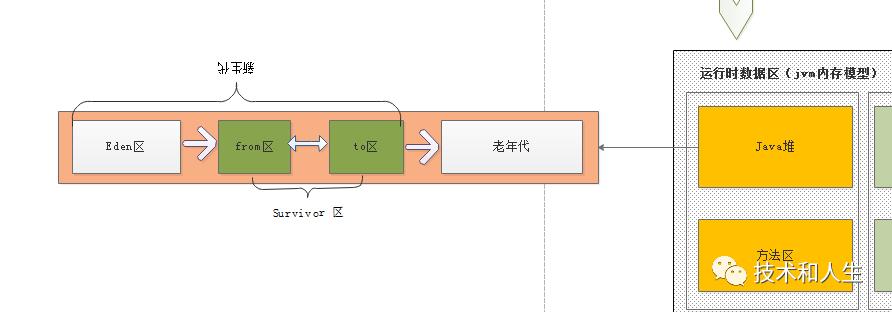
以上区域的大小分配是:
新生代:堆的 1/3
老年代:堆的 2/3
Eden 区:新生代的 8/10
Survivor From 区:新生代的 1/10
Survivor To区:新生代的 1/10
如果是从内存分配的角度来看,可以划分多个线程私有的分配缓冲区。
对于堆空间来说,本质都是存储对象实例。不过如何分区,都只是为了更好地分配和管理对象实例。关于堆空间对对象实例的管理和回收,在下一章节阐述。
同时,物理上可以不连续,但是逻辑上必须是连续的。
对象回收流程
下图摘自网络:
所有的类都是在伊甸区被 new 出来的,等到 Eden 区满的时候,会触发 Minor GC,将不需要再被其他对象引用的对象进行销毁,将剩余的对象移动到 From Survivor 区,每触发一次 Minor GC,对象的分代年龄会+1(分代年龄是存放在对象头里面的),From Survivor 区满的时候, From Survivor 区触发 Minor GC,未被回收的对象,分代年龄会继续+1,会移至 to survior 区,此时Eden的未被回收的对象也是移至 To Survivor 区,To Survivor 区满的时候,被移至 From Survivor 区,以此类推。
对象的分代年龄到15的时候,对象会进入到老年代(静态变量(对象类型)、数据库连接池等)。若老年代也满了,这个时候会产生 Major GC(Full GC),进行老年区的内存清理。若老年区执行了 Full GC之后发现依然无法进行对象的保存,就会产生OOM 异常 OutOfMemoryError。
注意事项
运行时数据区,版本不同,会有细微的差别,具体如下:
元数据区:元数据区取代了永久代(jdk1.8以前),本质和永久代类似,都是对JVM规范中方法区的实现,区别在于元数据区并不在虚拟机中,而是使用本地物理内存,永久代在虚拟机中,永久代逻辑结构上属于堆,但是物理上不属于堆,堆大小=新生代+老年代。元数据区也有可能发生OutOfMemory异常;
jdk1.6及以前:有永久代,常量池在方法区;
jdk1.7:有永久代,但已经逐步“去永久代”,常量池在堆;
jdk1.8及以后:无永久代,常量池在元空间(用的是计算机的直接内存,而不是虚拟机管理的内存)。
为什么jdk1.8用元数据区取代了永久代?
官方解释:移除永久代是为融合HotSpot JVM与JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。(简单说,就是两者竞争,谁赢了就听谁的。)
元数据区的动态扩展,默认–XX:MetaspaceSize值为21MB的高水位线。一旦触及则Full GC将被触发并卸载没有用的类(类对应的类加载器不再存活),然后高水位线将会重置。新的高水位线的值取决于GC后释放的元空间。如果释放的空间少,这个高水位线则上升。如果释放空间过多,则高水位线下降。
以上是关于细说JVM内存模型的主要内容,如果未能解决你的问题,请参考以下文章