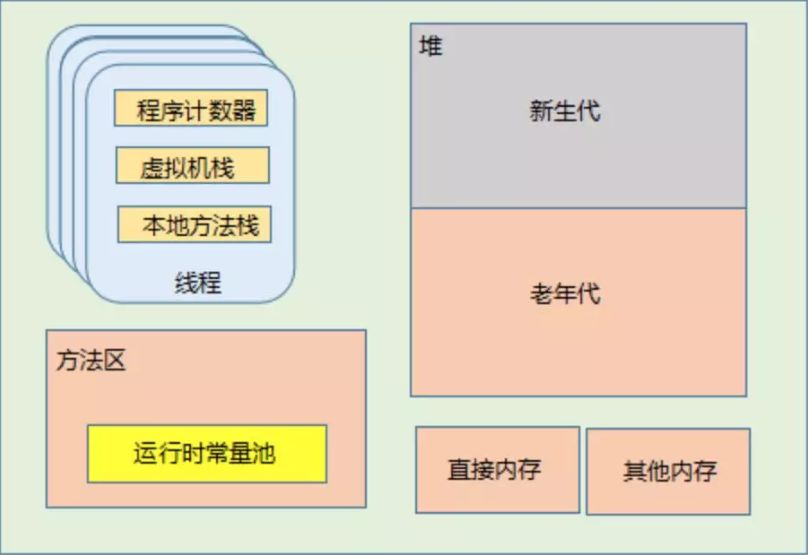
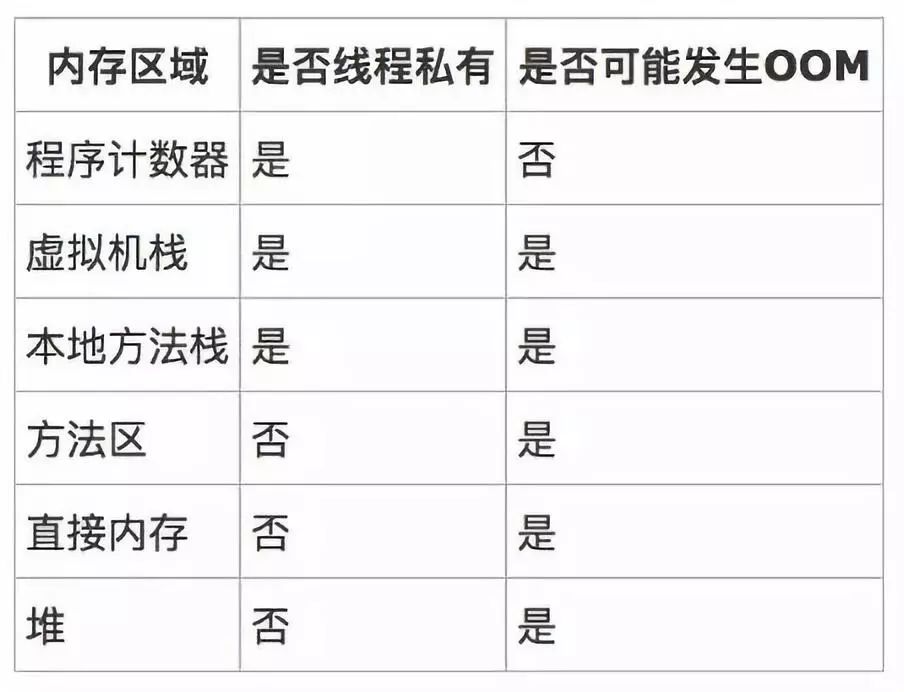
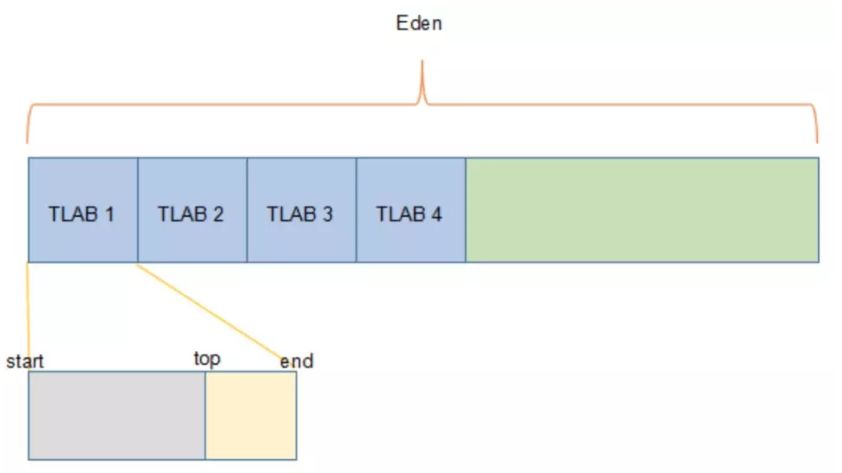
关于内存的监控与诊断,在后面会进行深入了解。现在来看下一个问题:堆内的结构是怎么的呢?,这篇推荐看下。 站在垃圾收集器的角度来看,可以把内存分为新生代与老年代。内存的分配规则取决于当前使用的是哪种垃圾收集器的组合,以及内存相关的参数配置。往大的方向说,对象优先分配在新生代的Eden区域,而大对象直接进入老年代。 第一, 新生代的Eden区域,对象优先分配在该区域,同时JVM可以为每个线程分配一个私有的缓存区域,称为TLAB(Thread Local Allocation Buffer),避免多线程同时分配内存时需要使用加锁等机制而影响分配速度。TLAB在堆上分配,位于Eden中。TLAB的结构如下:
// ThreadLocalAllocBuffer: a descriptor for thread-local storage used by // the threads for allocation. // It is thread-private at any time, but maybe multiplexed over // time across multiple threads. The park()/unpark() pair is // used to make it avaiable for such multiplexing. classThreadLocalAllocBuffer:public CHeapObj<mtThread> { friendclassVMStructs; private: HeapWord* _start; // address of TLAB HeapWord* _top; // address after last allocation HeapWord* _pf_top; // allocation prefetch watermark HeapWord* _end; // allocation end (excluding alignment_reserve) size_t _desired_size; // desired size (including alignment_reserve) size_t _refill_waste_limit; // hold onto tlab if free() is larger than this
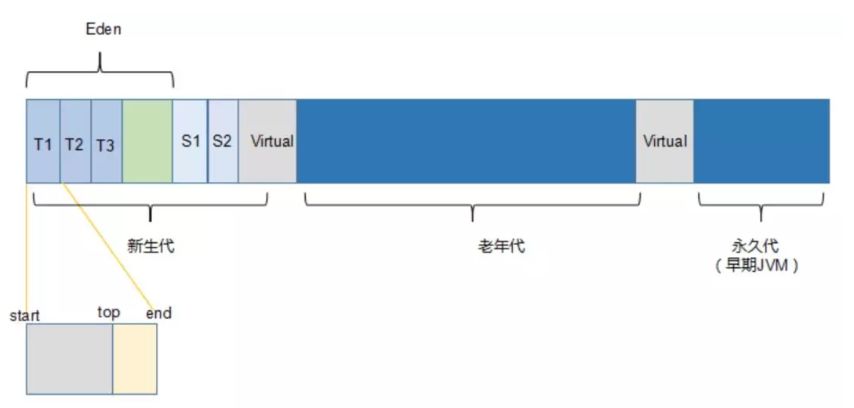
-XX:NewRatio = value 老年代与新生代的大小比例。默认情况下,这个比例是2,也就是说老年代是新生代的2倍大。老年代过大的时候,Full GC的时间会很长;老年代过小,则很容易触发Full GC,Full GC频率过高,这就是这个参数会造成的影响。
-XX:SurvivorRation = value . 设置Eden与Srivivor的大小比例,如果该值为8,代表一个Survivor是Eden的1/8,是整个新生代的1/10。
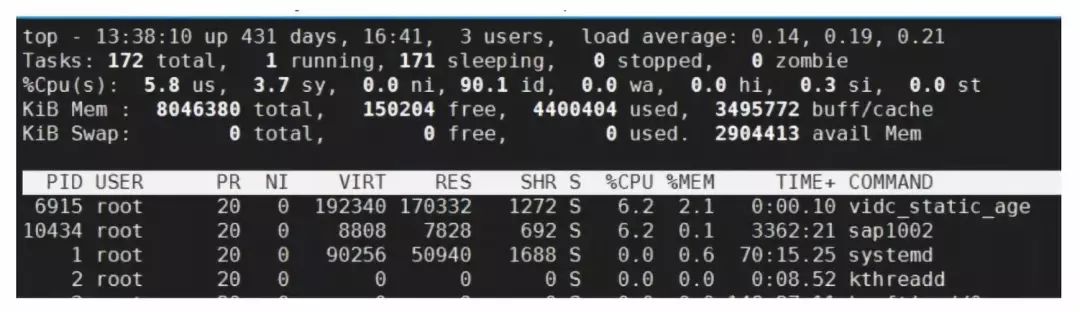
4、常用的性能监控与问题定位工具有哪些? 在系统的性能分析中,、内存与IO是主要的关注项。很多时候服务出现问题,在这三者上会体现出现,比如飙升,内存不足发生等,这时候需要使用对应的工具,来对性能进行监控,对问题进行定位。 对于CPU的监控,首先可以使用top命令来进行查看,下面是使用top查看负载的一个截图: load average 代表1分钟、5分钟、15分钟的系统平均负载,从这三个数字,可以判断系统负荷是大还是小。当完全空闲的时候,平均负荷为0;当工作量饱和的时候,平均负荷为1。 因此 load average 这三个数值越低,代表系统负荷越小,那么什么时候能看出系统负荷比较重呢?这篇文章(Understanding Linux CPU Load – when should you be worried)里解释得非常通俗。如果电脑里只有一个,把看成一条单行桥,桥上只有一个车道,所有的车都必须从这个桥上通过。那么 系统负荷为0,代表桥上一辆车也没有 系统负荷0.5,意味着桥上一半路段上有车 系统负荷1,意味着桥上道路已经被车占满 系统负荷1.7,代表着在桥上车子已经满了(100%),同时还有70%的车子在等待从桥上通过: