JVM笔记-HotSpot的算法细节实现
Posted WriteOnRead
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM笔记-HotSpot的算法细节实现相关的知识,希望对你有一定的参考价值。
1. 根节点枚举
1.1 暂停用户线程
迄今为止,所有收集器在根节点枚举这一步骤都是必须暂停用户线程的。即便是号称停顿时间可控、或者(几乎)不会发生停顿的 CMS、G1、ZGC 等收集器,枚举根节点时也必须要停顿。
这也是导致垃圾收集过程必须停顿所有用户线程的一个重要原因。
1.2 如何高效查找引用链
目前主流 JVM 使用的都是准确式垃圾收集,因此虚拟机有办法直接知道哪些地方存放着对象的引用。而 HotSpot 是使用一组称为 OopMap 的数据结构来实现的。
一旦类加载动作完成,HotSpot 就会把对象内什么偏移量上是什么类型的数据计算出来(在即时编译过程中,也会在「特定的位置」记录下栈和寄存器中哪些位置是引用),这样收集器在扫描时就能直接得知这些信息,不必挨个从方法区等 GC Roots 开始查找了。从而可以提高查找效率。
普通对象指针:Ordinary Object Pointer, OOP
2. 安全点
2.1 概述
前面「特定的位置」记录了引用信息,这些位置被称为安全点(Safepoint)。
用户程序执行时,并非在代码指令流的任意位置都能停下来开始垃圾收集,而是强制要求必须执行到安全点后才能暂停。
可以用高速公路上行驶的汽车做类比:高速公路上行驶的汽车(用户线程)不是在任何地方都能停下来的,只有到了服务区(安全点)才能停下。
2.2 安全点选取
安全点的选取既不能太多,也不能太少:
若太少,收集器会等待过长时间;
若太多,则会过分增加运行时的内存负荷。
安全点位置的选取标准:是否具有让程序长时间执行的特征。什么样的程序会长时间执行呢?
最明显的特征就是指令序列的复用,如方法调用、循环跳转、异常跳转等,只有具备这些功能的指令才会产生安全点。
2.3 如何让线程跑到最近的安全点
垃圾收集发生时,如何让所有线程(不包括 JNI 调用的线程)都跑到最近的安全点、然后停顿下来呢?有如下两种方案可以采用。
2.3.1 抢先式中断
思想:无需用户线程代码配合,垃圾收集时,系统首先把所有用户线程全部中断;此时若有用户线程不在安全点,则恢复执行,直至它到达安全点再中断。
这种方案现在几乎不用了。
2.3.2 主动式中断
思想:垃圾收集需要中断线程时,不直接操作线程,只是设置一个标志位,各个线程执行过程中不停地主动轮询该标志位,若标志位为真,则在自己最近的安全点主动中断挂起。
轮询标志的地方和安全点是重合的。
如何高效轮询呢?HotSpot 使用内存保护陷阱的方式,通过一条汇编指令来完成安全点轮询和触发线程中断。
2.4 优缺点
安全点机制保证了程序执行时,在不太长的时间内就会遇到可进入垃圾收集过程的安全点。
但是,无法解决程序“不执行”的情况(比如用户线程处于 Sleep 或者 Blocked 状态),由于此时线程无法响应虚拟机的中断请求,无法再走到安全点挂起自己。
3. 安全区域
3.1 概述
为了解决安全点机制中程序“不执行”的情况,从而引入了安全区域(Safe Region)。
安全区域是指能够确保在某一段代码片段中,引用关系不会发生变化,因此在这个区域中任意地方开始垃圾收集都是安全的。可以理解扩展拉伸的安全点。
3.2 实现思路
当用户线程执行到安全区域里的代码时,会标识自己已经进入了安全区域。
虚拟机发起垃圾收集时,不必理会已声明在安全区域的线程;而当线程离开安全区域时,会检查虚拟机是否已经完成根节点枚举(或者其他暂停用户线程的阶段):
若完成,则继续执行;
否则就必须等待,直至收到可以离开安全区域的信号。
4. 记忆集与卡表
4.1 跨代引用问题
分代收集理论中,为了解决对象跨代引用所带来的问题,垃圾收集器在新生代建立了名为记忆集(Remembered Set)的数据结构,以避免把整个老年代加入 GC Roots 的扫描范围。
实际上,所有涉及部分区域收集(Partial GC)行为的垃圾收集器(例如 G1、ZGC、Shenandoah 等)都会面临同样的问题。
4.2 记忆集
「记忆集」是一种抽象的数据结构,用于记录从「非收集区域」指向「收集区域」的指针集合。
垃圾收集场景中,收集器只需通过记忆集判断出某一块非收集区域是否存在指向收集区域的指针即可,无需了解跨代引用指针的全部细节。
因此,在实现记忆集时,可以采用不同的记录粒度,以节省记忆集的存储和维护成本,几种精度举例如下:
字长精度:每个记录精确到一个机器字长(处理器的寻址位数,如常见的 32 位或 64 位),该字包含跨代指针
对象精度:每个记录精确到一个对象,该对象中有字段包含跨代指针
卡精度:每个记录精确到一块内存区域,该区域中有对象包含跨代指针
4.3 卡表
4.3.1 记忆集&卡表
其中,上述第三种“卡精度”指的是用一种“卡表(Card Table)”的方式来实现记忆集,也是目前最常用的实现方式。
记忆集与卡表的关系:可类比 Java 语言中接口与实现类的关系(比如 Map 与 HashMap)。
4.3.2 卡表&卡页
卡表最简单的形式可以是一个字节数组,数组中的每个元素都对应着其标识的内存区域中一块特定大小的内存块,该内存块称为“卡页(Card Page)”,它们的关系如图所示:
一个卡页的内存中通常包含不止一个对象,只要卡页内有一个(或更多)对象的字段存在跨代指针,就将对应卡表的数组元素的值标识为 1,称为该元素变脏(Dirty),若无则标识为 0.
4.4 卡表的维护
卡表什么时候变脏?谁来把它变脏呢?
何时:当有其他分代区域中的对象引用了本区域对象时,其对应的卡表元素就应该变脏。
如何变脏:HotSpot 虚拟机是通过写屏障实现的。
下面介绍什么是写屏障。
5. 写屏障
5.1 简述
写屏障(Write Barrier)可以看做在虚拟机层面对“引用类型字段赋值”动作的 AOP 切面,赋值前的写屏障称为“写前屏障(Pre-Write Barrier)”,赋值后的写屏障称为“写后屏障(Post-Write Barrier)”。
应用写屏障后,虚拟机会为所有赋值操作生成相应的指令,一旦收集器在写屏障中增加了更新卡表操作,无论更新的是不是老年代对新生代的引用,每次只要对引用进行更新,就会产生额外的开销。
5.1 伪共享问题
5.1.1 伪共享
除了写屏障的开销,高并发场景下还存在“伪共享(False Sharing)”问题:即,多线程修改互相独立的变量时,如果这些变量恰好共享一个缓存行,会彼此影响而导致性能降低。
该问题是处理底层细节时经常需要考虑的。
5.1.2 如何避免
如何避免“伪共享”问题:不采用无条件写屏障,而是先检查卡表标记,仅当该卡表元素未被标记过时才将其标记为变脏。
若以 SQL 的更新操作(UPDATE)进行类比,则:
无条件写屏障:每次 UPDATE 不加判断,直接更新;
开启判断条件后:每次 UPDATE 前,先执行 SELECT,查询结果满足一定条件时再执行 UPDATE。
若开启该判断条件,能避免伪共享问题;但同时也会增加一次额外判断的开销。因此需要根据实际情况来权衡。
JDK 7 之后,HotSpot 虚拟机增加了如下参数来决定是否开启卡表更新的判断条件:
# 是否开启卡表更新的判断条件-XX:+UseCondCardMark
6. 并发的可达性分析
6.1 并发标记问题
可达性分析算法理论上要求全过程都基于一个能保障一致性的快照中才能进行分析,这意味着必须全程冻结用户线程(Stop The World)。
为什么必须在一个能保证一致性的快照上才能进行对象图的遍历呢?
如果用户线程是冻结的,没问题。
若用户线程没冻结,也就是用户线程与收集器并发工作呢?收集器在对象图标记,同时用户线程在修改引用关系(修改对象图的结构),这样可能出现两种后果:
把原本消亡的对象错误标记为存活,这种情况虽不好(产生了浮动垃圾),但还可以容忍。
把原本存活的对象标记为消亡,这就很严重了,程序肯定会因此报错。
下面用三色标记(Tri-color Marking)演示这种情况是如何产生的。
6.2 垃圾收集器标记过程
垃圾收集器从 GC Roots 开始标记的过程示意图如下:
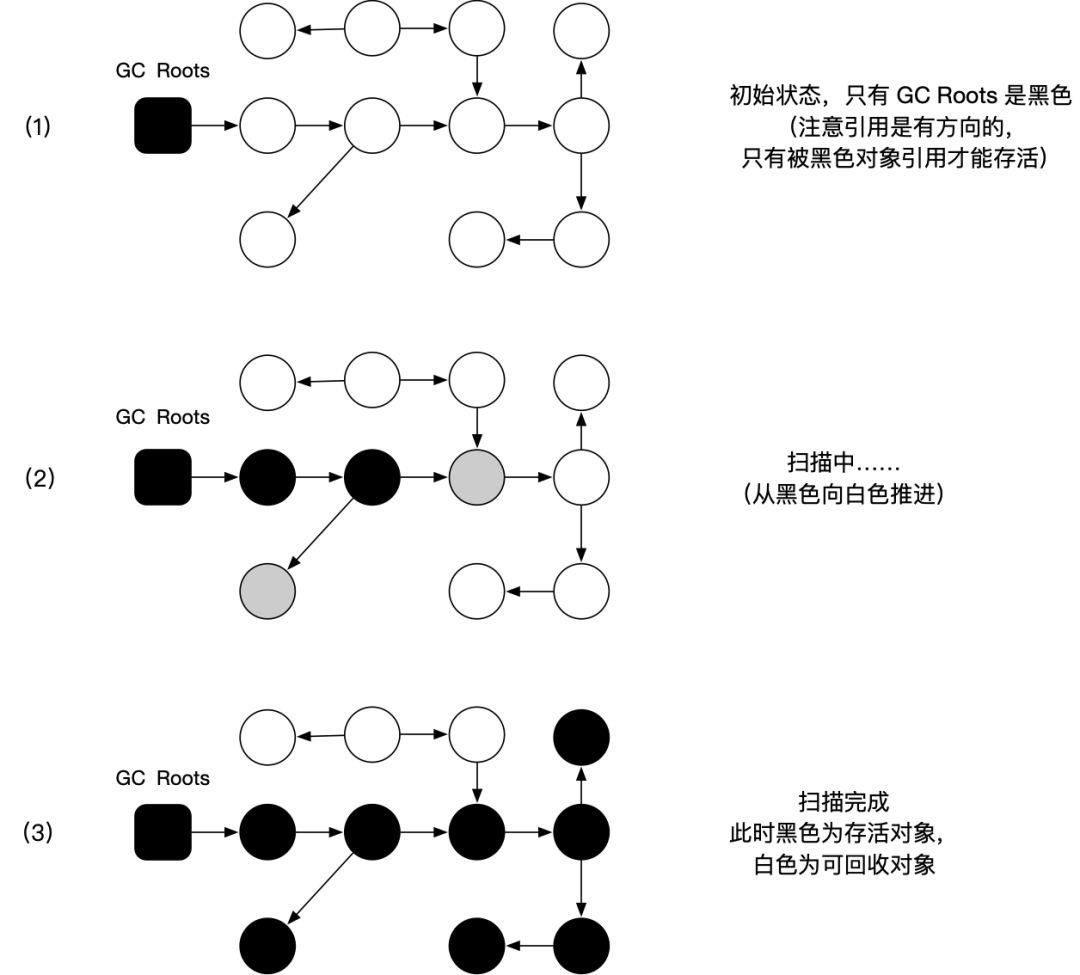
上图三色含义:
白色:对象尚未被垃圾收集器访问过(若在分析结束后,对象仍为白色,则表示不可达)
黑色:对象已被垃圾收集器访问过,且该对象所有引用都已被扫描(安全存活的)
灰色:对象已被垃圾收集器访问过,但未扫描完所有引用(即该对象正在被扫描,可理解为中间态)
注意引用是有方向的。
但是,如果在标记过程中,用户线程对引用关系做了修改,如下:
在上图的(4)中:
原先对象 A 未引用 C,对象 B 引用了 C;
但标记到 B 时,用户线程断开了 B 到 C 的引用,而使 A 引用了 C;
则垃圾收集器标记完成后,C 依然是白色(即会被回收掉);
对象 DEFG 同理。
这样导致的后果就是:正在被对象 A 和 D 引用的对象 C 和 G,在垃圾收集器标记的过程中,由于用户线程的运行,导致本应存活的对象被垃圾收集器标记为消亡、并回收了。程序会因此报错,这是个严重的问题。
6.3 如何解决对象消失
如何解决上述“对象消失”的问题呢?理论证明,当且仅当以下两个条件同时满足时,才会产生“对象消失”的问题:
赋值器插入了一条或多条从黑色对象到白色对象的新引用;
赋值器删除了全部从灰色对象到该白色对象的直接或间接引用。
针对这两个条件,在上图中,以对象 A、B、C 为例解释如下:
若只增加了 A 对 C 的引用,则 C 在垃圾回收后依然是存活的,不会出错。
若只有 B 断开了对 A 的引用,则 C 在垃圾回收后是消亡的,但并没有 A 对 C 的引用,因此也不会出错。
因此,要解决并发扫描时的对象消失问题,只需破坏其中一个即可。由此产生了两种解决方案:增量更新(Increment Update)和原始快照(Snapshot At The Begining, SATB)。
6.3.1 增量更新
思路:破坏第一个条件。
做法:黑色对象(A)插入新的指向白色对象(C)的引用关系(A→C)时,就将这个新插入的引用记录下来,待并发扫描结束之后,再以这些记录过的引用关系中的黑色为根,重新扫描一次。
简化理解:黑色对象一旦新插入了指向白色对象的引用,它就变为灰色(需重新扫描)了。
6.3.2 原始快照
思路:破坏第二个条件。
做法:当灰色对象(B)要删除指向白色对象(C)的引用关系(B→C)时,就将这个要删除的引用记录下来,并发扫描结束后,再以这些记录过的引用关系中的灰色对象为根,重新扫描一次。
简化理解:无论引用关系删除与否,都会按照刚开始扫描那一刻的对象图快照来进行搜索。
这两种方案都有在用:在 HotSpot 虚拟机中,CMS 是基于增量更新来做并发标记的,G1、Shenandoah 则是用原始快照实现的。
6.3.3 举例
以上图为例:在并发扫描时,增加了 A→C 引用,并且删除了 B→C 引用,若不采取任何措施,则扫描结束后对象 C 会消失。
两种解决方案的做法分别如下:
增量更新:将已标记为黑色的对象 A 置为灰色,待并发扫描结束后,重新扫描对象 A。此时可以扫描到 A→C 引用,对象 C 不会消失。
原始快照:若要删除 B→C 引用,则将原始的 B→C 引用记录下来(原始的快照),待并发扫描结束后,重新扫描对象 B,由于记录的是原始信息,其中包含 B→C 引用。这样,即便未扫描到 A→C 引用,对象 C 也不会消失。
此外,无论引用关系记录的插入还是删除,虚拟机都是通过写屏障实现的。
以上是关于JVM笔记-HotSpot的算法细节实现的主要内容,如果未能解决你的问题,请参考以下文章